






python中的函数本身就是对象,所以可以作为参数拿来传递。同时其允许函数的层级嵌套定义,使得灵活性大大增加。
闭包
闭包的定义:将函数的语句块与其运行所需要的环境打包到一起,得到的就是闭包对象。比如这样,在outer中写下一些变量,作为inner的参数,inner本身就像是个类方法然后在outer中定义的变量像成员变量。其实闭包就是为面向过程的编程语言提供了一种面向对象编程的思想方法。
以下是一些闭包中的问题&从语言机理出发的解释,顺便学习下python的机理。(本来打算和笔记本上一样按点整理,但是发现之前对这块知识的理解太青涩,矛盾百出。。一下子找不到头绪,决定可能比较凌乱地罗列一下几个点。)
首先来看一个例子:
def outer(): para = [1] def inner(): para.append(2) print id(para),para print id(para),para return inner if __name__ == '__main__': inner = outer() inner() outer() #输出 49352136 [1] 49352136 [1, 2] 49495880 [1]
首先,前两个输出的id一样,说明outer中的para确实原封不动地拿去给inner用了(至于什么叫原封不动,下文中有解释),且inner对其做了append操作之后para的值确实改变了。但是第三次和前两次的id又不同,这说明每调用一次outer,python就会重新初始化一个para,此时的para已经不是之前的那个para,id都不一样值自然也就回到了最开始的[1]了。
接下来如果把para.append(2)给换成para+=[2]的话,也就是:
def outer(): para = [1] def inner(): para += [2] print id(para),para print id(para),para return inner if __name__ == '__main__': inner = outer() inner() outer() #输出 47189448 [1] (报错UnboundLocalError: local variable 'para' referenced before assignment)
首先第一条输出还是能出现,说明了一个问题,python一直到在调用函数的时候才会开始解释函数中的语句。对于这个示例来说,第一次执行outer的时候,解释器碰到了def inner时并没有进入inner去解释,所以即使在inner有错误python还是会输出第一行的。*(当然SyntaxError是不行的,解释器开始解释时会无关具体语法地检查一遍syntax,通过检查才开始执行的)
其次,为什么+=语句会报错?这和python中的赋值语句的机理有关系。赋值语句的左边,如果直接是个变量名,那么python会默认它是当前最小的命名空间里的一个变量,然后进行一些操作。这个过程中,实际上python自动为你的变量做了声明了。换句话,python中的赋值语句相当于其他语言中先声明再赋值。而这个示例中的para+=[2]相当于para = para+[2] //(啊啊啊啊woc,这个问题我解释不了了orz)
那么如果在para+=[2]之前加上一句para=[3]会怎么样?这时你会发现,不仅para+=[2]能顺利完成,而且三次打印出来的para的id是一样的!这说明了当inner在给一个和外层函数变量同名的变量赋值时,默认这个变量就是外层函数的那个变量!这似乎就解释上文中的那个原封不动的意思?//至于为什么inner里面加一句para的赋值语句之后会连第三次打印出来的id都和前两次一样这点存疑
另外,还想补充一下关于内层函数用到的一些外层函数的变量赋值时机的问题。正如前面所说,只有当内层函数被调用的时候才python会去解析内层函数的语句。而所谓的解析语句的一个重要步骤就是去给被调用的外层函数的变量赋值。所以在下面这样一个示例中会出现如下情况:
def main(): flist = [] for i in range(3): def foo(x): print x+i flist.append(foo) for func in flist: func(2) #输出是 4 4 4 而不是 2 3 4
很显然,我原本的意图可能是让flist中存的3个foo函数对象有不同的功能,即在定义时3个foo函数的i是不同的。但是其实flist.append的时候,其append的只是一个函数对象(或者说只有函数语句的逻辑),并没有具体的指明其调用的外层函数变量i的具体值。这种现象在程序语言的术语中称为“后期绑定(late binding)”。因为每个foo的函数语句是相同的,所以在flist中的3个foo对象也是毫无差别。而在调用的时候,python才会给i去赋值,而i的值就是range(3)中最后一个赋给i的值2.所以输出的三个都是4而不是2,3,4。
要想解决这个问题,有好几种办法。在需要传入内层函数的值不多的情况下,让函数在被定义的时候就记住这个i的值,很简单,就是用参数的默认值。比如把foo函数改造成def (x,y=i):print x+y即可。第二种方法,可以将函数中的res=[]然后再循环地res.append这种机制直接转换为生成器的机制,即直接yield foo即可。在生成器的语境中,for i in range(3)这个循环不会一下子到底,所以i是循序渐进地增加,所以可以做到给出符合预期的2,3,4这样的结果。
闭包的应用场景主要有下(其实python既然支持面向对象编程,肯定用面向对象的思想来写更加简洁易懂。不一定用,就当是长个知识吧。。):
1. 当闭包内层函数执行完之后要更新环境再做进一步处理的情况:
def create(pos = [0]): def move(step): pos[0]+=step return pos return move >>>p = create() #创造一个在起点的对象 >>>print p(1) #向前走一步 [1] #返回当前位置 >>>print p(2) #再向前走两步 [3] #返回当前位置
2. 根据不同外层函数变量得到不同的闭包结果等等
哎。。原本以为已经差不多弄懂这个闭包了,可是今天再看看发现还是有很多不自洽的地方。不过好在python可以用class!闭包。。算了,继续往下吧,装饰器肯定比闭包用的更多
装饰器
来看这样一个闭包结构:
def wrapper(func): def powerup(): print "Something before" res = func() print "Something after" return res return powerup
对于传入wrapper的任何一个函数对象,它都得到了powerup函数对它的加强(在运行它之前会先进行预处理,运行之后会进行后处理)。如果让我们需要加强的一个函数function = wrapper(function)的话,function就“进化”成一个加强版的函数了。
在这个示例中,wrapper就是一个装饰器,在python2.4之后,提供了@wrapper的方法来表示一种装饰器。而在@wrapper下面def的函数就是需要加强的函数了。
如果一个装饰器带参数,那就是说明wrapper这个函数除了func这个参数本身,还带有一些其他参数,比如:
@eventhandler("BUTTON") def handle_button(msg): #一些处理 #相当于: def handle_button(msg): #一些处理 temp = eventhandler("BUTTON") handle_button = temp(handle_button) #简单地说,这个参数的意义就在于根据不同的参数,装饰器函数会给出不同地加强器(if you will)来加强需要加强的函数,自然也就可以得到不同版本的加强函数了。
所以在自定义带参数的装饰器函数的时候,要注意得包三层。第一层是@后面写的那个函数,其接受参数之后返回一个装饰器函数,这个装饰器函数才是之前所谓不带参数的装饰器中的那个装饰器函数。
针对多个装饰器共同装饰的情况:
@a @b @c def func(): ... #相当于: func = a(b(c(func)))
*装饰器也可以用于修饰类,但是在修饰类时就要保证装饰器函数返回的是一个类的抽象对象了(正所谓python之中万物皆对象,类本身也是个对象哦)
在fuctools内建模块中含有wraps这个函数。一般而言在自定义装饰器的时候可以在内层函数开始之前写一个@wraps(func),这样可以保证在使用装饰器时被装饰函数的__name__,__doc__等属性得以保留,看下面的例子中加入和注释@wraps的区别:
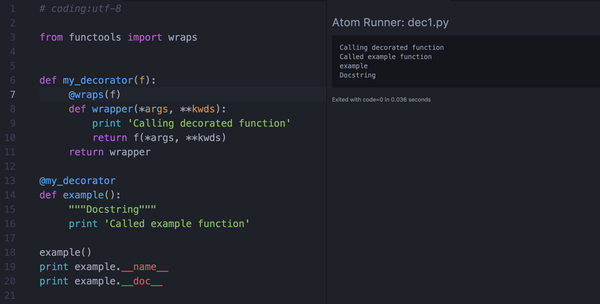
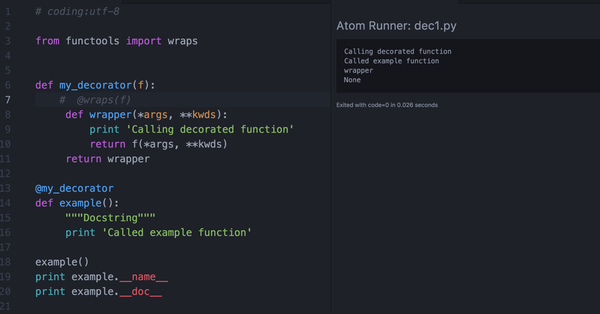
■ 再论装饰器
之前写得都是什么鬼… 重新再来感受一遍装饰器
首先要知道,装饰器用的@符号意思是什么。一般来说,下面两种方式表达的是同一种代码逻辑:
@decorate def target(): print 'Do something' def target(): print 'Do something' target = decorate(target)
只要符合这样规律的decorate函数就是一个简单的装饰器函数(这里还没有涉及到带有参数的装饰器)。换言之,只要一个函数接受一个函数对象作为参数,并且又返回了一个函数对象,那么广义上来说它就是一个装饰器函数。
Python中装饰器,在执行时机的选择上有一个很重要的特点,那就是在“装饰”发生的时刻进行执行。参看下面这段代码:
def decorate(func): print 'register %s' % func return func @decorate def test1(): print 'test1' @decorate def test2(): print 'test2' def main(): print 'Go into main' test1() test2() if __name__ == '__main__': main() ''' 这段代码如果作为__main__脚本运行的结果是 register <function test1 at 0x000000000264AA58> register <function test2 at 0x000000000264AAC8> Go into main test1 test2 ######################### 如果是作为模块被其他程序import,那么也会有输出 register <function test1 at 0x0000000002658A58> register <function test2 at 0x0000000002658AC8> '''
由于装饰器对函数进行装饰的本质是target = decorate(target),所以在定义装饰器和函数关联的时候,装饰器中的代码(指decorate(target)时会执行到的代码)就会被执行。一旦装饰器和函数关联成立,那么从任何地方去调用函数能够调到的都只是装饰过后的函数,因此装饰器代码一定是先于函数能被调用之前执行的。这也是为什么当脚本作为模块被import的时候还是会有输出的原因。
在这个示例的装饰器中,我演示性地做了一个“注册”的操作。这个操作其实就是很多Python的Web框架中干的事情。在MVC模型中,这样的操作将所有endpoint对应的view函数安排到统一的地方,然后根据url映射规则进行从统一view函数库中选出合适的函数做出HTTP回应。
上面示例中对于装饰器返回的函数对象都还是传入装饰器的函数对象本身。实际自定义装饰器肯定不能这么搞。所以更加常用的装饰器的套路可能是这样的:
def decorate(func): def decorated_func(*args,**kwargs): ''' decorated_func这个函数其实可以看做我们需要的“加强版”的func函数。 它接受的参数以及给出的返回理应和func保持一致,从而令func的执行复合我们的预期 ''' # 做一些处理... return func() return decorated_func
再次强调,decorated_func这个内部函数,应该尽量和被修饰的函数func保持输入和输出格式要求上的一致。因为装饰器说到底只是装饰,不应该影响我们自己定义的func函数本身的功能。
提醒一下,decorated_func中的代码不会在“装饰”发生时被执行,因为这些属于内部函数内的代码。
● 带参数的装饰器
带参的装饰器应用更加广泛一点。但是需要注意一个情况:
###### 不带参的场合 ###### @A def B(): # 相当于 def B(): B = A(B) ###### 带参的场合 ###### @A(c,d) def B(): # 相当于 def B(): B = A(c,d)(B)
带参数的时候,带参装饰器函数就不是返回decorated_func本身了,而应该是一个不带参的装饰器函数。也就是说带参装饰器函数(属于广义上的装饰器函数)应该接受一些参数,而返回一个不带参的装饰器函数(狭义上的装饰器函数)
设想一个简单的情况,我们根据装饰器的参数给出不同的不带参装饰器,从而形成一个选择结构。
参看:


def decorate(type='A'): if type == 'A': def nonparam_decorate(func): def decorated_func(param): for ch in param: print 'AAAAA' + ch func(param) return decorated_func return nonparam_decorate else: def nonparam_decorate(func): def decorated_func(param): for ch in param: if ch != 'A': print ch func(param) return decorated_func return nonparam_decorate @decorate(type='A') def testA(s): print 'Input is ' + s @decorate(type='B') def testB(s): print '(In B)Input is ' + s if __name__ == '__main__': testA('ABC') testB('ABC')















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









