







一、概述
HBase Shell 提供了大多数的 HBase 命令, 通过 HBase Shell 用户可以方便地创建、删除及修改表, 还可以向表中添加数据、列出表中的相关信息等。在启动 HBase 之后,用户可以通过下面的命令进入 HBase Shell 之中,命令如下所示:
[hadoop@node222 ~]$ /usr/local/hbase-1.2.6.1/bin/hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.6.1, rUnknown, Sun Jun 3 23:19:26 CDT 2018
hbase(main):001:0>
输入 help 可以看到命令分组。(注意命令都是小写,有大小写的区分)


二、操作示例
1、general操作
# 查询 HBase 服务器状态 status。
hbase(main):001:0> status
1 active master, 1 backup masters, 2 servers, 0 dead, 1.0000 average load
# 查询hbase版本 version
hbase(main):002:0> version
1.2.6.1, rUnknown, Sun Jun 3 23:19:26 CDT 20182、DDL操作
# 创建一个表,create 'tableName','columnFimalyName1','columnFimalyName2','columnFimalyNameN'
hbase(main):003:0> create 'member','address','info'
0 row(s) in 3.1330 seconds
=> Hbase::Table - member
#列出所有的表
hbase(main):004:0> list
TABLE
member
1 row(s) in 0.0530 seconds
=> ["member"]
#获得表的描述信息
hbase(main):005:0> describe 'member'
Table member is ENABLED
member
COLUMN FAMILIES DESCRIPTION
{NAME => 'address', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FORE
VER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER
', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.3560 seconds
# 删除一个列族 disable alter enable 注意删除前,需要先把表disable
hbase(main):006:0> disable 'member'
0 row(s) in 2.3910 seconds
#删除指定列
hbase(main):007:0> alter 'member',{NAME=>'address',METHOD=>'delete'}
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 2.2840 seconds
hbase(main):008:0> enable 'member'
0 row(s) in 1.4370 seconds
hbase(main):009:0> describe 'member'
Table member is ENABLED
member
COLUMN FAMILIES DESCRIPTION
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER
', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.0350 seconds
# 查看表是否存在
hbase(main):010:0> exist 'member2'
NoMethodError: undefined method `exist' for #<Object:0x53aa2fc9>
#判断表是否为'enable'
hbase(main):011:0> is_enabled 'member'
true
0 row(s) in 0.0260 seconds
# 删除一个表先disable
hbase(main):012:0> disable 'member'
0 row(s) in 2.3150 seconds
hbase(main):013:0> drop 'member'
0 row(s) in 1.3420 seconds
3、DML操作
插入几条记录,put只能一次put '一个表','一行','一个列族:一个列','值't1指表名,r1指行键名,c1指列名,value指单元格值。ts1指时间戳,一般都省略掉了。不能一次put两个列值。
# 创建表
hbase(main):014:0> create 'member','address','info'
0 row(s) in 2.3320 seconds
=> Hbase::Table - member
# put数据
hbase(main):015:0> put 'member', 'scutshuxue', 'info:age', '24'
0 row(s) in 0.2530 seconds
put 'member', 'scutshuxue', 'info:birthday', '1987-06-17'
put 'member', 'scutshuxue', 'info:company', 'alibaba'
put 'member', 'scutshuxue', 'address:contry', 'china'
put 'member', 'scutshuxue', 'address:province', 'zhejiang'
put 'member', 'scutshuxue', 'address:city', 'hangzhou'
# 全表扫描 scan
hbase(main):021:0> scan 'member'
ROW COLUMN+CELL
scutshuxue column=address:city, timestamp=1540027486109, value=hangzhou
scutshuxue column=address:contry, timestamp=1540027484239, value=china
scutshuxue column=address:province, timestamp=1540027484293, value=zhejiang
scutshuxue column=info:age, timestamp=1540027473410, value=24
scutshuxue column=info:birthday, timestamp=1540027484107, value=1987-06-17
scutshuxue column=info:company, timestamp=1540027484194, value=alibaba
1 row(s) in 0.0900 seconds
# 获得数据 get,获得一行的所有数据
hbase(main):022:0> get 'member','scutshuxue'
COLUMN CELL
address:city timestamp=1540027486109, value=hangzhou
address:contry timestamp=1540027484239, value=china
address:province timestamp=1540027484293, value=zhejiang
info:age timestamp=1540027473410, value=24
info:birthday timestamp=1540027484107, value=1987-06-17
info:company timestamp=1540027484194, value=alibaba
6 row(s) in 0.0890 seconds
# 获得数据 get,获得某行,某列族的所有数据
hbase(main):023:0> get 'member','scutshuxue','info'
COLUMN CELL
info:age timestamp=1540027473410, value=24
info:birthday timestamp=1540027484107, value=1987-06-17
info:company timestamp=1540027484194, value=alibaba
3 row(s) in 0.0410 seconds
# 获得数据 get获得某行,某列族,某列的所有数据
hbase(main):024:0> get 'member','scutshuxue','info:age'
COLUMN CELL
info:age timestamp=1540027473410, value=24
1 row(s) in 0.0560 seconds
#更新一条记录 put(把scutshuxue年龄改为99)
hbase(main):025:0> put 'member','scutshuxue','info:age',99
0 row(s) in 0.0290 seconds
#查询表中有多少行
hbase(main):026:0> count 'member'
1 row(s) in 0.0750 seconds
=> 1
# 删除列族中某列值 delete
hbase(main):027:0> delete 'member','scutshuxue','info:age'
0 row(s) in 0.0780 seconds
# 删除整行
hbase(main):034:0> deleteall 'member','scutshuxue'
0 row(s) in 0.0400 seconds
# 将整个表清空,HBase 是通过先对表执行 disable,然后再执行 drop 操作后重建表来实现 truncate 的功能的。
hbase(main):028:0> truncate 'member'
Truncating 'member' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 3.7170 seconds
# 一个完整建表语句解析
hbase(main):029:0> create 'NewsClickFeedback',{NAME=>'Toutiao',VERSIONS=>1,BLOCKCACHE=>true,BLOOMFILTER=>'ROW',COMPRESSION=>'SNAPPY',TTL => '259200'},{SPLITS => ['1','2','3','4','5','6','7','8','9','a','b','c','d','e','f']}
0 row(s) in 4.5490 seconds
=> Hbase::Table - NewsClickFeedback
hbase(main):030:0> describe 'NewsClickFeedback'
Table NewsClickFeedback is ENABLED
NewsClickFeedback
COLUMN FAMILIES DESCRIPTION
{NAME => 'Toutiao', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => '2592
00 SECONDS (3 DAYS)', COMPRESSION => 'SNAPPY', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.0460 seconds
参数解析:
VERSIONS
数据版本个数,HBase数据模型允许一个cell的数据为带有不同时间戳的多版本数据集,VERSIONS参数指定了最多保存几个版本数据,默认为1。假如某个用户想保存两个历史版本数据,可以将VERSIONS参数设置为2,再使用如下Scan命令就可以获取到所有历史数据
BLOOMFILTER
布隆过滤器,优化HBase的随机读取性能,可选值NONE|ROW|ROWCOL,默认为NONE,该参数可以单独对某个列簇启用。启用过滤器,对于get操作以及部分scan操作可以剔除掉不会用到的存储文件,减少实际IO次数,提高随机读性能。Row类型适用于只根据Row进行查找,而RowCol类型适用于根据Row+Col联合查找,如下:
Row类型适用于:get ‘NewsClickFeedback’,’row1′
RowCol类型适用于:get ‘NewsClickFeedback’,’row1′,{COLUMN => ‘Toutiao’}
对于有随机读的业务,建议开启Row类型的过滤器,使用空间换时间,提高随机读性能。
COMPRESSION
数据压缩方式,HBase支持多种形式的数据压缩,一方面减少数据存储空间,一方面降低数据网络传输量进而提升读取效率。目前HBase支持的压缩算法主要包括三种:GZip | LZO | Snappy,Snappy的压缩率最低,但是编解码速率最高,对CPU的消耗也最小,目前一般建议使用Snappy
TTL
数据过期时间,单位为秒,默认为永久保存。对于很多业务来说,有时候并不需要永久保存某些数据,永久保存会导致数据量越来越大,消耗存储空间是其一,另一方面还会导致查询效率降低。如果设置了过期时间,HBase在Compact时会通过一定机制检查数据是否过期,过期数据会被删除。用户可以根据具体业务场景设置为一个月或者三个月。示例中TTL => ‘ 259200’设置数据过期时间为三天
IN_MEMORY
数据是否常驻内存,默认为false。HBase为频繁访问的数据提供了一个缓存区域,缓存区域一般存储数据量小、访问频繁的数据,常见场景为元数据存储。默认情况,该缓存区域大小等于Jvm Heapsize * 0.2 * 0.25 ,假如Jvm Heapsize = 70G,存储区域的大小约等于3.2G。需要注意的是HBase Meta元数据信息存储在这块区域,如果业务数据设置为true而且太大会导致Meta数据被置换出去,导致整个集群性能降低,所以在设置该参数时需要格外小心。
BLOCKCACHE
是否开启block cache缓存,默认开启。
SPLITS
region预分配策略。通过region预分配,数据会被均衡到多台机器上,这样可以一定程度上解决热点应用数据量剧增导致系统自动split引起的性能问题。HBase数据是按照rowkey按升序排列,为避免热点数据产生,一般采用hash + partition的方式预分配region,比如示例中rowkey首先使用md5 hash,然后再按照首字母partition为16份,就可以预分配16个region。
MIN_VERSIONS
最小版本数
BLOCKSIZE
数据块的大小
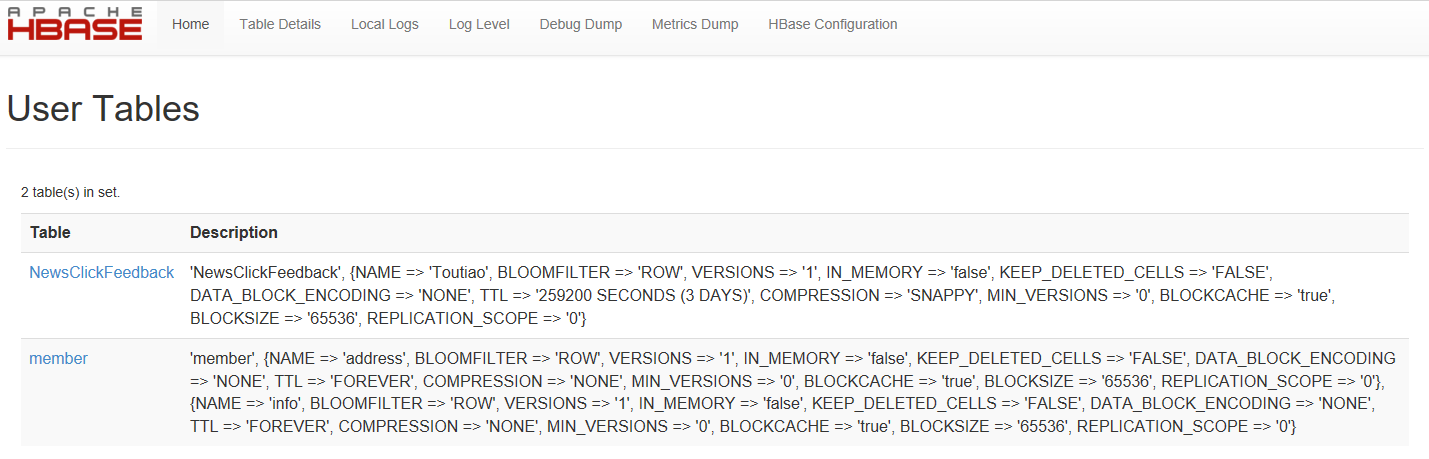
通过web客户端查看以上操作所创建的表















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









