







统计一列中所有相同的数据,枚举。
![]()
或者是统计行数。
![]()
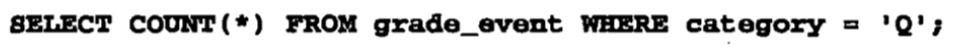
![]()
COUNT(*)是统计统计所有被选择出来满足条件的指定的行数,COUNT(列名)统计非NULL的值的个数。
统计多少个州有总统出生。

GROUP BY
这个关键词可查询在某一个数据列中有多少种不同值出现,搭配COUNT(*)可统计那些值出现的个数。

SELECT * FROM `hi_wtgl_wtjl` GROUP BY clr只显示GROUP BY 后面列出现的第一条数据。最好和COUNT(*)搭配使用。原理应该是对所有数据逐条判断,若碰断新的数据,则将该条数据放到一个容器准备显示,若碰到已有数据,则其统计数量+1。
需要用到分门别类的统计,最好使用GROUP BY 关键词。
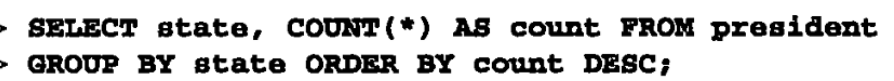
注意以上语句, ORDER BY不能直接使用 COUNT(*) 作为函数进行排序,必须要转换成一个count变量!
或者定义输出位置。

最好还是用之前一种。

HAVING 和WHERE 的区别在于 COUNT()之类的汇总函数可以在HAVING子句中存在。

HAVING 子句查询命令特别适合查找某个数列中重复出现的值。或者不重复出现的值(HAVING COUNT = 1).
MIN(),MAX(),SUM(),AVG()。可求出某个数量中最小值,最大值,总和,平均值。

WITH ROLLUP

用这句作为聚合,它还会统计出在之前所有列的统计结果。
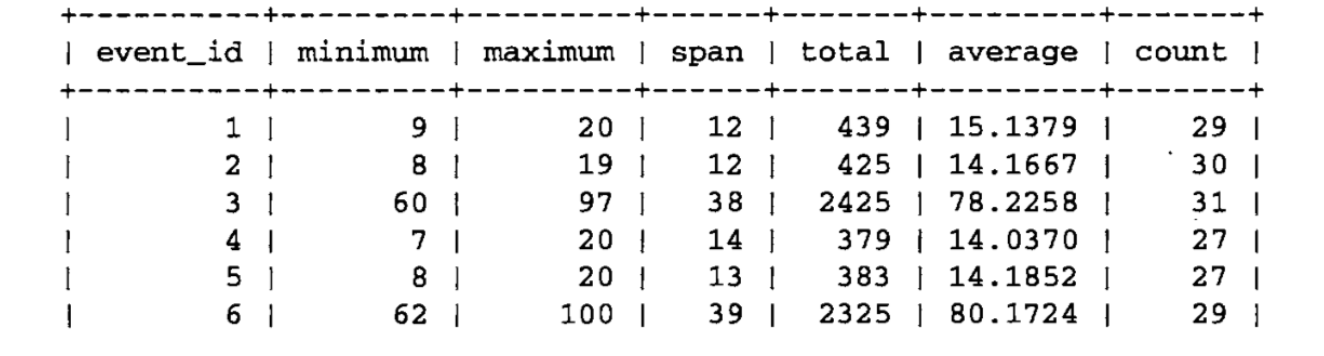
加了之后多了一条数据。















 9291
9291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









