







转载申明:最近在看AlphaGo的原理,刚好在
https://blog.csdn.net/a1805180411/article/details/51155164
发现了这篇文章,感觉写的非常好,好东西就要分享,所以转载过来供大家学习。
以下是转载全文。
导读:关于Alfa Go的评论文章很多,但真正能够与开发团队交流的却不多,感谢Alfa Go开发团队DeepMind的朋友对我这篇文章内容的关注与探讨,指出我在之前那一版文章中用字上的不够精确,所以在此又作调整。我之前文章提到的「全局」指的是跨时间点的整场赛局,很容易被误认为是某个特定时点整个棋盘的棋局,所以后面全部都修改为「整体棋局」。此外,关于整体棋局评估,除了透过脱机数据学习的评价网络之外,还可以透过根据目前状态实时计算的不同策略评价差异(这项技术称之为Rollouts),它透过将计算结果进行快取,也能做到局部考虑整体棋局的效果。再次感谢DeepMind朋友的斧正。
在人类连输AlphaGo三局后的今天,正好是一个好时机,可以让大家对于AlphaGo所涉及的深度学习技术能够有更多的理解(而不是想象复仇者联盟中奥创将到来的恐慌)。在说明Alpha Go的深度学习技术之前,我先用几个简单的事实总结来厘清大家最常误解的问题:
●AlphaGo这次使用的技术本质上与深蓝截然不同,不再是使用暴力解题法来赢过人类。
●没错,AlphaGo是透过深度学习能够掌握更抽象的概念,但是计算机还是没有自我意识与思考。
●AlphaGo并没有理解围棋的美学与策略,他只不过是找出了2个美丽且强大的函数来决定他的落子。
什么是类神经网络?
其实类神经网络是很古老的技术了,在1943年,Warren McCulloch以及Walter Pitts首次提出神经元的数学模型,之后到了1958年,心理学家Rosenblatt提出了感知器(Perceptron)的概念,在前者神经元的结构中加入了训练修正参数的机制(也是我们俗称的学习),这时类神经网络的基本学理架构算是完成。类神经网络的神经元其实是从前端收集到各种讯号(类似神经的树突),然后将各个讯号根据权重加权后加总,然后透过活化函数转换成新讯号传送出去(类似神经元的轴突)。
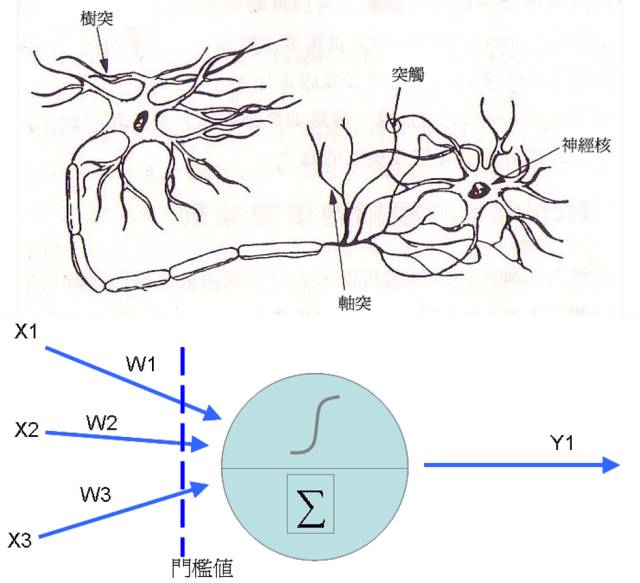
至于类神经网络则是将神经元串接起来,我们可以区分为输入层(表示输入变量),输出层(表示要预测的变量),而中间的隐藏层是用来增加神经元的复杂度,以便让它能够仿真更复杂的函数转换结构。每个神经元之间都有连结,其中都各自拥有权重,来处理讯号的加权。
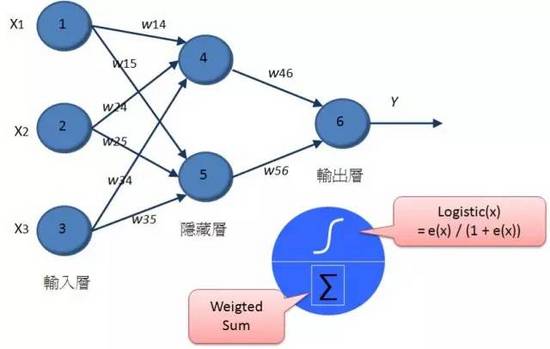
传统的类神经网络技术,就是透过随机指派权重,然后透过递归计算的方式,根据输入的训练数据,逐一修正权重,来让整体的错误率可以降到最低。随着倒传导网络、无监督式学习等技术的发展,那时一度类神经网络蔚为显学,不过人类很快就遇到了困难,那就是计算能力的不足。因为当隐藏层只有一层的时候,其实大多数的状况,类神经网络的分类预测效果其实并不会比传统统计的罗吉斯回归差太多,但是却要耗费更庞大的计算能力,但是随着隐藏层神经元的增加,或者是隐藏层的增加,那么所需要计算权重数量就会严重暴增。所以到了八十年代后期,整个类神经网络的研究就进入了寒冬,各位可能只能在洗衣机里体会到它小小威力(现在洗衣机里根据倒入衣物评估水量与运行时间很多都是用类神经网络作的),说真的,类神经网络一点都没有被认为强大。
这个寒冬一直持续到2006年,在Hinton以及Lecun小组提出了「A fast
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









