






一:grep的简介:
文本搜索工具,根据用户指定的文本模式对目标文件进行逐行搜索,显示能够被模式所匹配到的行。配合正则表达式的使用可以实现强大的文本处理。下面一一说明正则的例子。
二:文本处理工具分类
常用的有:grep,egrep,fgrep。
区别:
grep:在没有参数的情况下,只输出符合RE(Regular Expression)字符。
egrep:等同于grep -E,和grep最大的区别就是表现在转义符上比如grep 做次数匹配时\{n,m\}egrep则不需要直接{n,m}。egrep方便,简介。
fgrep:等同于grep -f,但是不能使用正则表达式。所有的字符匹配功能均已消失。
三:grep参数说明:
格式:grep [OPTIONS] PATTERN(模式) [FILE...]
常用选项:
--color=auto:显示颜色的参数。
-n:输出行号。
-v:反向匹配,显示不能被模式所匹配到的行。比如指定root,匹配的就不是root。
例子:

-o:仅显示被模式匹配到的所指定的字符。

-i:不区分大小写字符。

-A #:不但能匹配到指定的字符那一行。而且字符后面所指定的n行也能显示出来。

-B #:不但能匹配到指定的字符那一行。而且字符前面所指定的n行也能显示出来。

-C #:不但能匹配到指定的字符那一行。而且字符前后所指定的n行也能显示出来。

为了方便我把grep --color=auto定义一个别名,别名为cgrep。方便使用。后续直接使用cgrep 就能显示颜色了。
alias cgrep="grep --color=auto"
四:常用的字符匹配和实例:
只要使用字符匹配和一些元字符的时候,必须用引号引起来;
引号用单引或双引都即可。
.:任意单个字符,指的就是一个点代表1个字符。这个字符不特殊指分,符号也行。

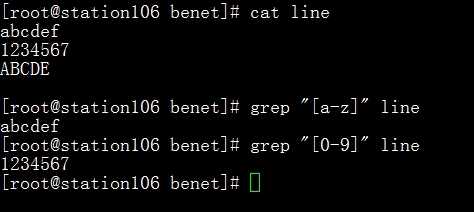
[]:指定范围内的任意单个字符。这个括号中指定的字符都能匹配出来,匹配范围广。

[^]:指定范围外的任意单个字符,和上面[]这个想法。取反。通俗的意思就是括号中所指定的字符,就匹配不到了。

五:特殊字符表示。
[[:digit:]]:表示所有的数字。 [[:lower:]]:表示小写字母。 [[:upper:]]:表示大写字母。 [[:alpha:]]:表示全部的大写和小写字母。 [[:alnum:]]:表示全部的字母和数字。 [[:space:]]:表示空格符。 [[:punct:]]表示标点符号。
例子如下:
[[:digit:]]:表示所有的数字。

[[:lower:]]:表示小写字母。

[[:upper:]]:表示大写字母。

[[:alpha:]]:表示全部的大写和小写字母。

[[:alnum:]]:表示全部的字母和数字。

[[:space:]]:表示空格符。

[[:punct:]]表示标点符号。

六:次数匹配:
*:任意次,意为匹配的字符中,有任意个字符都行。

.*:匹配任意长度的任意字符。

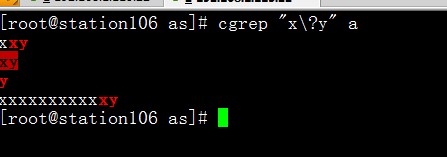
\?:匹配其前面的字符0次或1次;"a\?b"指的就是a后面到b中间可以有一个字符或者什么都没有。

七:贪婪模式匹配:尽可能的去匹配。永无止境。
\{m\}:匹配m次;

\{m,n\}:至少m次,最多n次;

\{m,\}:至少m次;多的话贪婪匹配。

\{0,n}:至多n次;
八:位置锚定匹配:用于指定字符出现的位置。
^:用于锚定行首。
$:用于锚定行尾。

^$:锚定空白行。

\<或\b锚定词首。

\>或\b锚定词尾。

九:分组
\(\):指的就是括号里面的字符属于一个组。在一块的就匹配显示出来。


十:引用
1\:后向引用,引用前面的第一个左括号以及与之对应的右括号中的模式所匹配到的内容。
2\:后向引用,引用前面的第二个左括号以及与之对应的右括号中的模式所匹配到的内容。
。。。。。。。。。。。。

下面讲解Egrep扩展正则表达式:功能和grep 有区别的地方下面会举例说名。
字符匹配:
.:任意单个字符。
[]:指定范围内的任意单个字符。
[^]:指定范围外的任意单个字符。
次数匹配:
*:匹配其前面的字符任意次。
?:匹配其前面的字符0次或1次。
+:匹配其前面的字符至少1次。
{m}:匹配其前面的字符m次。这里可以看出来了和grep区别是少了转义符\。
{m,n}:至少m次,至多n次。
{m,}:至少m次。
{0,n}:至多n次。
锚定匹配:
^:行首锚定。
$:行尾锚定。
\<或\b:词首锚定。
\>或\b:词尾锚定。
分组匹配:
():分组。
|:或者,ac|bc。匹配ac和bc所在的字符。
fgrep:相当于grep -f,不解析正则表达式。
以上就是基本的使用。
下面通过例子在演示一下。
练习:
1)显示/proc/meminfo文件中以大小写s开头的行:

2)显示默认/etc/rc.d/rc.sysinit文件中,以#开头,后面至少一个空白字符,而后又有至少一个非空白字符的行。

egrep "^#[[:space:]]{1,}[^[:space:]]{1,}" /etc/rc.d/rc.sysinit
3)显示/boot/grub/grub.conf中以至少一个空白字符开头的行。

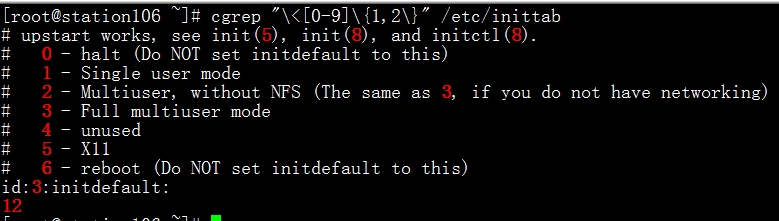
4)找出/etc/inittab文件中以为数和两位数:

5)找出用户名和shell相同的用户。

6)找出netstat -tan命令执行的结果中以"LISTEN"或“ESTABLISHE"结尾的行。
netstat -tan| egrep "(LISTEN|ESTABLISHED)"
————————————————————————————————
PS:
以上就是自己所能理解和总结的内容。由于能力有限,希望对各位有所帮助。如果疑问--》吐槽--》在评论——》指出不明白处--》然后给你解答--》解答后如有不明--》继续吐槽--》继续给你解答。
转载于:https://blog.51cto.com/shunzi/1362003














 4509
4509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}