







1、Hadoop基本概念
hadoop:是java语言实现的,开源的,能够对大量数据进行分布式处理的软件框架,主要由分布式存储HDFS和分布式计算MapReduce组成。
2、Hadoop是怎么产生的
技术基础,google三驾马车:GFS、MapReduce和BigTable。Hadoop是在google三驾马车基础上的开源实现。
GFS(Google File System)分布式文件系统,对应Hadoop当中的HDFS。
MapReduce分布式计算框架,也是Hadoop处理大数据的核心思想。
BigTable是基于GFS的数据存储系统,对应Hadoop的HBase。
3、Hadoop的特点
优点:
可靠:Hadoop假设计算元素和存储会失败,所以会维护多个工作数据的副本,对失败的节点会重新处理
高效:HDFS的高效数据交互实现和MapReduce结合Local Data处理模式,为高效处理海量信息奠定基础,通过并行方式工作,加快处理速度。
高扩展:可以方便地扩展到数以千计的节点,处理PB级的数据。
低成本:Hadoop是开源的,Hadoop节点可以是任何普通的PC。
分布式架构,海量数据存储
移动计算而非移动数据,化整为零,分片处理
本地化计算,并行IO,降低网络通信
4、三大分布式计算系统比较
Hadoop,Spark,Storm是主流的三大分布式计算系统
Spark VS Hadoop
Hadoop使用硬盘来存储数据,而Spark是将数据存在内存中的,因此Spark何以提供超过Hadoop 100倍的计算速度。内存断电后会丢失,所以Spark不适用于需要长期保存的数据。
Storm VS Hadoop
Storm在Hadoop基础上提供了实时运算的特性,可以实时处理大数据流。不同于Hadoop和Spark,Storm不进行数据的搜集和存储工作,直接通过网络接受并实时处理数据,然后直接通过网络实时传回结果。
所以三者适用于的应用场景分别为:
Hadoop常用于离线的复杂的大数据处理
Spark常用于离线的快速的大数据处理
Storm常用于在线实时的大数据处理
5、Hadoop原理
5.1、HDFS
HDFS(Hadoop Distributed File System),是Hadoop的分布式文件存储系统,将大文件分解为多个Block,每个Block保存多个副本(默认每个Block保存3个副本,64M为1个Block)。提供容错机制,副本丢失或者宕机时自动恢复。将Block按照key-value映射到内存当中(如果小文件太多,那内存的负担会很重)。
HDFS架构图:
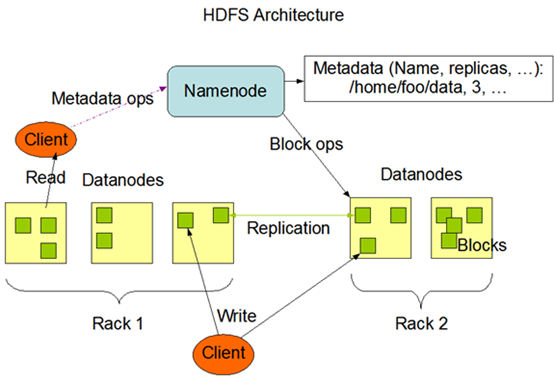
-- NameNode
HDFS使用主从结构,NameNode是Master节点,是领导。所有的客户端的读写请求,都需要首先请求NameNode。
NameNode存储
fsimage:元数据镜像文件(文件系统的目录树,文件的元数据信息)。元数据信息包括文件的信息,文件对应的block信息(版本信息,类型信息,和checksum),以及每一个block所在的DataNode的信息。
edits:元数据的操作日志
-- DataNode
DataNode是Slave,负责真正存储所有的block内容,以及数据块的读写操作
NameNode,DataNode,rack只是一些逻辑上的概念。NameNode和DataNode可能是一台机器也可能是,相邻的一台机器,很多DataNode可能处于同一台机器。rack是逻辑上比DataNode更大的概念,可能是一台机器,一台机柜,也可能是一个机房。通过使文件的备份更广泛地分布到不同的rack,DataNode上可以保证数据的可靠性。
-- HDFS写入数据
1、Client拆分文件为64M一块。
2、Client向NameNode发送写数据请求。
3、NameNode节点,记录block信息。并返回可用的DataNode。
4、Client向DataNode发送block1,2,3….;发送过程是以流式写入。流式写入,数据流向为DataNode1->DataNode2->DataNode3(1,2,3为通过规则选出来的可用的DataNode)
发送完毕后告知NameNode
5、NameNode告知Client发送完成
在写数据的时候:
写1T文件,我们需要3T的存储,3T的网络流量贷款。
在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
-- HDFS读取数据
1、Client向NameNode发送读请求
2、NameNode查看MetaData信息,返回文件的block位置
3、根据一定规则(优先选择附近的数据),按顺序读取block
5.2、MapReduce
Map是把一组数据一对一的映射为另外的一组数据,其映射的规则由一个map函数来指定。Reduce是对一组数据进行归约,这个归约的规则由一个reduce函数指定。
整个的MapReduce执行过程可以表示为:
(input)<k1, v1> => map => <k2, v2> => combine => <k2, v2’> => reduce => <k3, v3>(output)
也可以表示为流程图:
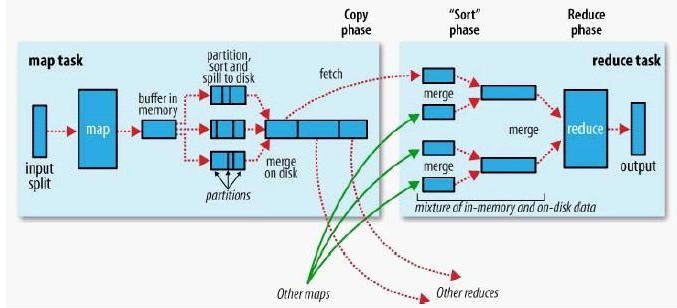
1、分割:把输入数据分割成不相关的若干键/值对(key1/value1)集合,作为input
2、映射:这些键/值对会由多个map任务来并行地处理。输出一些中间键/值对key2/value2集合
3、排序:MapReduce会对map的输出(key2/value2)按照key2进行排序(便于归并)
4、conbine:属于同一个key2的所有value2组合在一起作为reduce任务的输入(相当于提前reduce,减小key2的数量,减小reduce的负担)
5、Partition:将mapper的输出分配到reducer;(Map的中间结果通常用”hash(key) mod R”这个结果作为标准)
6、规约:由reduce任务计算出最终结果并输出key3/value3。
程序员需要做的
单机程序需要处理数据读取和写入、数据处理
Hadoop程序需要实现map和reduce函数
map和reduce之间的数据传输、排序,容错处理等由Hadoop MapReduce和HDFS自动完成。
常用操作命令
hadoop的命令操作大部分都被分配到hdfs或者mapred替代了。
1、查询hadoop版本
[root@server01 /]# hadoop version
2、hadoop fs命令现在基本都使用hdfs dfs替代了
[root@server01 hadoop]# hadoop fs -help
[root@server01 hadoop]# hdfs dfs -help
3、递归显示指定目录下的所有文件及文件夹
[root@server01 hadoop]# hdfs dfs -ls /
4、创建指定的目录
[root@server01 hadoop]# hdfs dfs -mkdir -p /practice
5、创建指定名称的空文件
[root@server01 hadoop]# hdfs dfs -touchz /practice/file_0821.txt
6、将本地的文件复制到hdfs的指定目录(可相对路径可绝对路径)
[root@server01 hadoop]# hdfs dfs -put LICENSE.txt /practice
7、拷贝HDFS文件至本地文件系统(可相对路径可绝对路径)
[root@server01 hadoop]# hdfs dfs -get /practice/LICENSE.txt HDFS_LICENSE.txt
8、统计HDFS指定目录下各文件的大小
[root@server01 hadoop]# hdfs dfs -du /practice
9、移动文件位置,改名
[root@server01 hadoop]# hdfs dfs -mv /practice/file_0821.txt /practice/dir02
10、拷贝改名
[root@server01 hadoop]# hdfs dfs -cp /practice/dir01/LICENSE.txt /practice/dir02/LICENSE.bak
11、查看文件内容
[root@server01 hadoop]# hdfs dfs -cat /practice/LICENSE.txt
12、将本地文件追加至hdfs文件中
[root@server01 hadoop]# hdfs dfs -appendToFile LICENSE.txt /practice/dir02/file_0821.sql
13、HDFS管理命令
[root@server01 hadoop]# hdfs dfsadmin -report
[root@server01 hadoop]# hdfs dfsadmin -printTopology















 9564
9564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









