







基于Spark 2.0 Preview的材料翻译,原[英]文地址:
http://spark.apache.org/docs/2.0.0-preview/streaming-programming-guide.html
Streaming应用实战,参考:http://my.oschina.net/u/2306127/blog/635518
Spark Streaming Programming Guide
Spark Streaming编程指南
Overview
概览
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.
Spark Streaming 是基于Spark 核心API的扩展,使高伸缩性、高带宽、容错的流式数据处理成为可能。数据可以来自于多种源,如Kafka、Flume、Kinesis、或者TCP sockets等,而且可以使用map、reduce、join 和 window等高级接口实现复杂算法的处理。最终,处理的数据可以被推送到数据库、文件系统以及动态布告板。实际上,你还可以将Spark的机器学习( machine learning) 和图计算 (graph processing )算法用于数据流的处理。

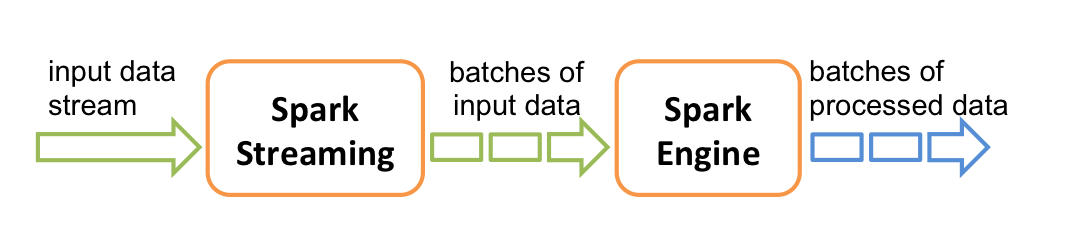
Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.
内部工作流程如下。Spark Streaming接收数据流的动态输入,然后将数据分批,每一批数据通过Spark创建一个结果数据集然后进行处理。
Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data. DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs.
Spark Streaming提供一个高级别的抽象-离散数据流(DStream),代表一个连续的数据流。DStreams可以从Kafka, Flume, and Kinesis等源中创建,或者在其它的DStream上执行高级操作。在内部,DStream代表一系列的 RDDs。
This guide shows you how to start writing Spark Streaming programs with DStreams. You can write Spark Streaming programs in Scala, Java or Python (introduced in Spark 1.2), all of which are presented in this guide. You will find tabs throughout this guide that let you choose between code snippets of different languages.
本指南将岩石如何通过DStreams开始编写一个Spark Streaming程序。你可以使用Scala、Java或者Python。可以通过相应的连接切换去查看相应语言的代码。
Note: There are a few APIs that are either different or not available in Python. Throughout this guide, you will find the tag Python API highlighting these differences.
这在Python里有一些不同,很少部分API暂时没有,本指南进行了标注。
A Quick Example
快速例程
Before we go into the details of how to write your own Spark Streaming program, let’s take a quick look at what a simple Spark Streaming program looks like. Let’s say we want to count the number of words in text data received from a data server listening on a TCP socket. All you need to do is as follows.
在开始Spark Streaming编程之前我们先看看一个简单的Spark Streaming程序将长什么样子。我们从基于TCP socket的数据服务器接收一个文本数据,然后对单词进行计数。看起来像下面这个样子。
First, we import the names of the Spark Streaming classes and some implicit conversions from StreamingContext into our environment in order to add useful methods to other classes we need (like DStream). StreamingContext is the main entry point for all streaming functionality. We create a local StreamingContext with two execution threads, and a batch interval of 1 second.
首先,我们导入Spark Streaming的类命名空间和一些StreamingContext的转换工具。 StreamingContext 是所有的Spark Streaming功能的主入口点。我们创建StreamingContext,指定两个执行线程和分批间隔为1秒钟。
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent from a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))Using this context, we can create a DStream that represents streaming data from a TCP source, specified as hostname (e.g. localhost) and port (e.g. 9999).
使用这个context,我们可以创建一个DStream,这是来自于TCP数据源 的流数据,我们通过hostname (e.g. localhost) 和端口 (e.g. 9999)来指定这个数据源。
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)This lines DStream represents the stream of data that will be received from the data server. Each record in this DStream is a line of text. Next, we want to split the lines by space characters into words.
这里line是一个DStream对象,代表从服务器收到的流数据。每一个DStream中的记录是一个文本行。下一步,我们将每一行中以空格分开的单词分离出来。
// Split each line into words
val words = lines.flatMap(_.split(" "))flatMap is a one-to-many DStream operation that creates a new DStream by generating multiple new records from each record in the source DStream. In this case, each line will be split into multiple words and the stream of words is represented as the words DStream. Next, we want to count these words.
flatMap是“一对多”的DStream操作,通过对源DStream的每一个记录产生多个新的记录创建新DStream。这里,每一行将被分解多个单词,并且单词流代表了words DStream。下一步,我们对这些单词进行计数统计。
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()The words DStream is further mapped (one-to-one transformation) to a DStream of (word, 1) pairs, which is then reduced to get the frequency of words in each batch of data. Finally, wordCounts.print() will print a few of the counts generated every second.
words DStream然后映射为(word, 1)的键值对的Dstream,然后用于统计单词出现的频度。最后,wordCounts.print()打印出每秒钟创建出的计数值。
Note that when these lines are executed, Spark Streaming only sets up the computation it will perform when it is started, and no real processing has started yet. To start the processing after all the transformations have been setup, we finally call
注意,上面这些代码行执行的时候,仅仅是设定了计算执行的逻辑,并没有真正的处理数据。在所有的设定完成后,为了启动处理,需要调用:
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminateThe complete code can be found in the Spark Streaming example NetworkWordCount.
完整的代码可以Spark Streaming 的例程 NetworkWordCount 中找到。
If you have already downloaded and built Spark, you can run this example as follows. You will first need to run Netcat (a small utility found in most Unix-like systems) as a data server by using
如果已经下载和构建了Spark,你可以按照下面的方法运行这个例子。首先运行Netcat(一个Unix风格的小工具)作为数据服务器,如下所示:
$ nc -lk 9999Then, in a different terminal, you can start the example by using
然后,到一个控制台窗口,启动例程:
$ ./bin/run-example streaming.NetworkWordCount localhost 9999Then, any lines typed in the terminal running the netcat server will be counted and printed on screen every second. It will look something like the following.
然后,任何在netcat服务器运行控制台键入的行都会被计数然后每隔一秒钟在屏幕上打印出来,如下所示:
|
|
Basic Concepts
基本概念
Next, we move beyond the simple example and elaborate on the basics of Spark Streaming.
下一步,我们将离开这个简单的例子,详细阐述Spark Streaming的基本概念和功能。
Linking
链接
Similar to Spark, Spark Streaming is available through Maven Central. To write your own Spark Streaming program, you will have to add the following dependency to your SBT or Maven project.
与Spark类似,Spark Streaming也可以通过Maven中心库访问。为了编写你自己的Spark Streaming程序,您将加入下面的依赖到你的SBT或者Maven工程文件。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.0.0-preview</version>
</dependency>
For ingesting data from sources like Kafka, Flume, and Kinesis that are not present in the Spark Streaming core API, you will have to add the corresponding artifact spark-streaming-xyz_2.11 to the dependencies. For example, some of the common ones are as follows.
为了从Kafka/Flume/Kinesis等非Spark Streaming核心API等数据源注入数据,我们需要添加对应的spark-streaming-xyz_2.11到依赖中。例如,像下面的这样:
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka-0-8_2.11 |
| Flume | spark-streaming-flume_2.11 |
| Kinesis | spark-streaming-kinesis-asl_2.11 [Amazon Software License] |
For an up-to-date list, please refer to the Maven repository for the full list of supported sources and artifacts.
对于最新的列表,参考Maven repository 获得全面的数据源河访问部件的列表。
Initializing StreamingContext
初始化StreamingContext
To initialize a Spark Streaming program, a StreamingContext object has to be created which is the main entry point of all Spark Streaming functionality.
为了初始化Spark Streaming程序,StreamingContext 对象必须首先创建作为总入口。
A StreamingContext object can be created from a SparkConf object.
StreamingContext 对象可以通过 SparkConf 对象创建,如下所示。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))The appName parameter is a name for your application to show on the cluster UI. master is a Spark, Mesos or YARN cluster URL, or a special “local[*]” string to run in local mode. In practice, when running on a cluster, you will not want to hardcode master in the program, but rather launch the application with spark-submit and receive it there. However, for local testing and unit tests, you can pass “local[*]” to run Spark Streaming in-process (detects the number of cores in the local system). Note that this internally creates a SparkContext (starting point of all Spark functionality) which can be accessed as ssc.sparkContext.
这里 appName参数是应用在集群中的名称。 master 是 Spark, Mesos 或 YARN cluster URL, 或者“local[*]” 字符串指示运行在 local 模式下。实践中,当运行一个集群, 您不应该硬编码 master 参数在集群中, 而是通过 launch the application with spark-submit 接收其参数。但是, 对于本地测试和单元测试, 你可以传递“local[*]” 来运行 Spark Streaming 在进程内运行(自动检测本地系统的CPU内核数量)。 注意,这里内部创建了 SparkContext (所有的Spark 功能的入口点) ,可以通过 ssc.sparkContext进行存取。
The batch interval must be set based on the latency requirements of your application and available cluster resources. See the Performance Tuning section for more details.
分批间隔时间基于应用延迟需求和可用的集群资源进行设定(译注:设定间隔要大于应用数据的最小延迟需求,同时不能设置太小以至于系统无法在给定的周期内处理完毕),参考 Performance Tuning 部分获得更多信息。
A StreamingContext object can also be created from an existing SparkContext object.
StreamingContext 对象也可以从已有的 SparkContext 对象中创建。
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))After a context is defined, you have to do the following.
- Define the input sources by creating input DStreams.
- Define the streaming computations by applying transformation and output operations to DStreams.
- Start receiving data and processing it using
streamingContext.start(). - Wait for the processing to be stopped (manually or due to any error) using
streamingContext.awaitTermination(). - The processing can be manually stopped using
streamingContext.stop().
在context创建之后,可以接着开始如下的工作:
- 定义 input sources,通过创建 input DStreams完成。
- 定义 streaming 计算,通过DStreams的 transformation 和 output 操作实现。
- 启动接收数据和处理,通过
streamingContext.start()。 - 等待处理停止 (通常因为错误),通过
streamingContext.awaitTermination(). - 处理过程可以手动停止,通过
streamingContext.stop()。
Points to remember:
- Once a context has been started, no new streaming computations can be set up or added to it.
- Once a context has been stopped, it cannot be restarted.
- Only one StreamingContext can be active in a JVM at the same time.
- stop() on StreamingContext also stops the SparkContext. To stop only the StreamingContext, set the optional parameter of
stop()calledstopSparkContextto false. - A SparkContext can be re-used to create multiple StreamingContexts, as long as the previous StreamingContext is stopped (without stopping the SparkContext) before the next StreamingContext is created.
记住:
- 一旦context启动, 没有新的streaming 计算可以被设置和添加进来。
- 一旦context被停止, 它不能被再次启动。
- 只有一个StreamingContext在JVM中在同一时间可以被激活。
- stop() 在StreamingContext执行时,同时停止了SparkContext。为了仅终止StreamingContext, 在
stopSparkContext的Stop时设置选项为false。 - SparkContext 可以重用来创建多个 StreamingContexts, 一直到前一个StreamingContext被停止的时候 (不停止 SparkContext) ,才能创建下一个StreamingContext。
Discretized Streams (DStreams)
离散数据流
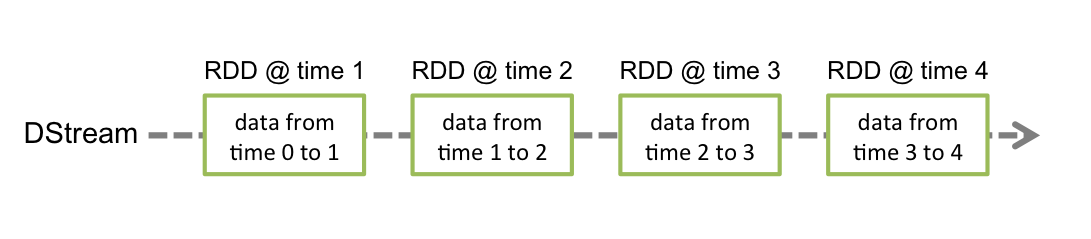
Discretized Stream or DStream is the basic abstraction provided by Spark Streaming. It represents a continuous stream of data, either the input data stream received from source, or the processed data stream generated by transforming the input stream. Internally, a DStream is represented by a continuous series of RDDs, which is Spark’s abstraction of an immutable, distributed dataset (see Spark Programming Guide for more details). Each RDD in a DStream contains data from a certain interval, as shown in the following figure.
离散数据流(DStream)是Spark Streaming最基本的抽象。它代表了一种连续的数据流,要么从某种数据源提取数据,要么从其他数据流映射转换而来。DStream内部是由一系列连 续的RDD组成的,每个RDD都是不可变、分布式的数据集(详见Spark编程指南 – Spark Programming Guide)。每个RDD都包含了特定时间间隔内的一批数据,如下图所示:
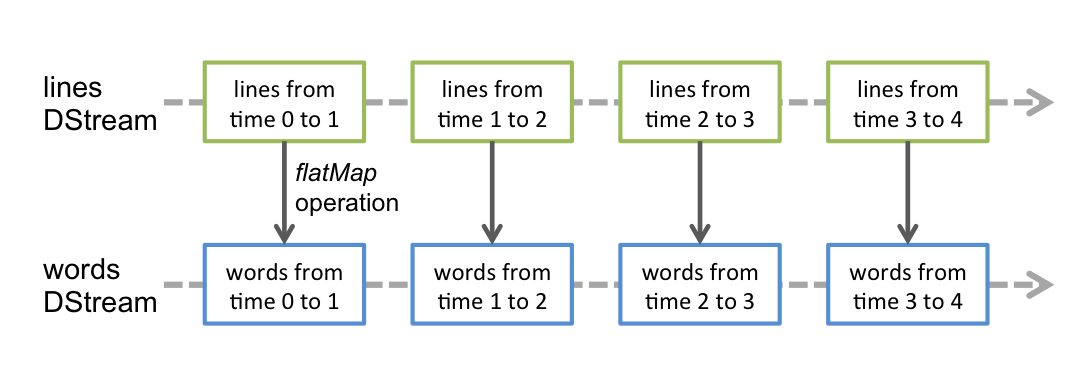
Any operation applied on a DStream translates to operations on the underlying RDDs. For example, in the earlier example of converting a stream of lines to words, the flatMap operation is applied on each RDD in the lines DStream to generate the RDDs of the words DStream. This is shown in the following figure.
任何作用于DStream的算子,其实都会被转化为对其内部RDD的操作。例如,在前面的例子中,我们将 lines 这个DStream转成words DStream对象,其实作用于lines上的flatMap算子,会施加于lines中的每个RDD上,并生成新的对应的RDD,而这些新生成的RDD 对象就组成了words这个DStream对象。其过程如下图所示:
These underlying RDD transformations are computed by the Spark engine. The DStream operations hide most of these details and provide the developer with a higher-level API for convenience. These operations are discussed in detail in later sections.
底层的RDD转换仍然是由Spark引擎来计算。DStream的算子将这些细节隐藏了起来,并为开发者提供了更为方便的高级API。后续会详细讨论这些高级算子。
Input DStreams and Receivers
输入DStream和接收器
Input DStreams are DStreams representing the stream of input data received from streaming sources. In the quick example, lines was an input DStream as it represented the stream of data received from the netcat server. Every input DStream (except file stream, discussed later in this section) is associated with a Receiver (Scala doc, Java doc) object which receives the data from a source and stores it in Spark’s memory for processing.
输入DStream代表从某种流式数据源流入的数据流。在之前的例子里,lines 对象就是输入DStream,它代表从netcat server收到的数据流。每个输入DStream(除文件数据流外)都和一个接收器(Receiver – Scala doc, Java doc)相关联,而接收器则是专门从数据源拉取数据到内存中的对象。
Spark Streaming provides two categories of built-in streaming sources.
- Basic sources: Sources directly available in the StreamingContext API. Examples: file systems, and socket connections.
- Advanced sources: Sources like Kafka, Flume, Kinesis, etc. are available through extra utility classes. These require linking against extra dependencies as discussed in the linking section.
Spark Streaming主要提供两种内建的流式数据源:
- 基础数据源(Basic sources): 在StreamingContext API 中可直接使用的源,如:文件系统,套接字连接或者Akka actor。
- 高级数据源(Advanced sources): 需要依赖额外工具类的源,如:Kafka、Flume、Kinesis、Twitter等数据源。这些数据源都需要增加额外的依赖,详见依赖链接(linking)这一节。
We are going to discuss some of the sources present in each category later in this section.
本节中,我们将会从每种数据源中挑几个继续深入讨论。
Note that, if you want to receive multiple streams of data in parallel in your streaming application, you can create multiple input DStreams (discussed further in the Performance Tuning section). This will create multiple receivers which will simultaneously receive multiple data streams. But note that a Spark worker/executor is a long-running task, hence it occupies one of the cores allocated to the Spark Streaming application. Therefore, it is important to remember that a Spark Streaming application needs to be allocated enough cores (or threads, if running locally) to process the received data, as well as to run the receiver(s).
注意,如果你需要同时从多个数据源拉取数据,那么你就需要创建多个DStream对象(详见后续的性能调优这一小节)。多个DStream对象其实也就同 时创建了多个数据流接收器。但是请注意,Spark的worker/executor 都是长期运行的,因此它们都会各自占用一个分配给Spark Streaming应用的CPU。所以,在运行Spark Streaming应用的时候,需要注意分配足够的CPU core(本地运行时,需要足够的线程)来处理接收到的数据,同时还要足够的CPU core来运行这些接收器。
Points to remember
-
When running a Spark Streaming program locally, do not use “local” or “local[1]” as the master URL. Either of these means that only one thread will be used for running tasks locally. If you are using a input DStream based on a receiver (e.g. sockets, Kafka, Flume, etc.), then the single thread will be used to run the receiver, leaving no thread for processing the received data. Hence, when running locally, always use “local[n]” as the master URL, where n > number of receivers to run (see Spark Properties for information on how to set the master).
-
Extending the logic to running on a cluster, the number of cores allocated to the Spark Streaming application must be more than the number of receivers. Otherwise the system will receive data, but not be able to process it.
要点
- 如果本地运行Spark Streaming应用,记得不能将master设为”local” 或 “local[1]”。这两个值都只会在本地启动一个线程。而如果此时你使用一个包含接收器(如:套接字、Kafka、Flume等)的输入 DStream,那么这一个线程只能用于运行这个接收器,而处理数据的逻辑就没有线程来执行了。因此,本地运行时,一定要将master设 为”local[n]”,其中 n > 接收器的个数(有关master的详情请参考Spark Properties)。
- 将Spark Streaming应用置于集群中运行时,同样,分配给该应用的CPU core数必须大于接收器的总数。否则,该应用就只会接收数据,而不会处理数据。
Basic Sources
基础数据源
We have already taken a look at the ssc.socketTextStream(...) in the quick example which creates a DStream from text data received over a TCP socket connection. Besides sockets, the StreamingContext API provides methods for creating DStreams from files as input sources.
前面的快速入门例子中,我们已经看到,使用ssc.socketTextStream(…) 可以从一个TCP连接中接收文本数据。而除了TCP套接字外,StreamingContext API 还支持从文件或者Akka actor中拉取数据。
-
File Streams: For reading data from files on any file system compatible with the HDFS API (that is, HDFS, S3, NFS, etc.), a DStream can be created as:
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)Spark Streaming will monitor the directory
dataDirectoryand process any files created in that directory (files written in nested directories not supported). Note thatFor simple text files, there is an easier method
streamingContext.textFileStream(dataDirectory). And file streams do not require running a receiver, hence does not require allocating cores.Python API
fileStreamis not available in the Python API, onlytextFileStreamis available. -
文件数据流(File Streams): 可以从任何兼容HDFS API(包括:HDFS、S3、NFS等)的文件系统,创建方式如下:
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)-
Spark Streaming将监视该dataDirectory目录,并处理该目录下任何新建的文件(目前还不支持嵌套目录)。注意:
- 各个文件数据格式必须一致。
- dataDirectory中的文件必须通过moving或者renaming来创建。
- 一旦文件move进dataDirectory之后,就不能再改动。所以如果这个文件后续还有写入,这些新写入的数据不会被读取。
-
另外,文件数据流不是基于接收器的,所以不需要为其单独分配一个CPU core。
Python API
fileStream目前暂时不可用,Python目前只支持textFileStream。对于简单的文本文件,更简单的方式是调用 streamingContext.textFileStream(dataDirectory)。
-
-
Streams based on Custom Receivers: DStreams can be created with data streams received through custom receivers. See the Custom Receiver Guide and DStream Akka for more details.
-
基于自定义Actor的数据流(Streams based on Custom Actors): DStream可以由Akka actor创建得到,只需调用 streamingContext.actorStream(actorProps, actor-name)。详见自定义接收器(Custom Receiver Guide)。actorStream暂时不支持Python API。
-
Queue of RDDs as a Stream: For testing a Spark Streaming application with test data, one can also create a DStream based on a queue of RDDs, using
streamingContext.queueStream(queueOfRDDs). Each RDD pushed into the queue will be treated as a batch of data in the DStream, and processed like a stream. - RDD队列数据流(Queue of RDDs as a Stream): 如果需要测试Spark Streaming应用,你可以创建一个基于一批RDD的DStream对象,只需调用 streamingContext.queueStream(queueOfRDDs)。RDD会被一个个依次推入队列,而DStream则会依次以数据 流形式处理这些RDD的数据。
For more details on streams from sockets and files, see the API documentations of the relevant functions in StreamingContext for Scala, JavaStreamingContext for Java, and StreamingContext for Python.
关于套接字、文件以及Akka actor数据流更详细信息,请参考相关文档:StreamingContext for Scala,JavaStreamingContext for Java, and StreamingContext for Python。
Advanced Sources
高级数据源
Python API As of Spark 2.0.0, out of these sources, Kafka, Kinesis and Flume are available in the Python API.
Python API 自 Spark 2.0.0(译注:1.6.1就已经支持了) 起,Kafka、Kinesis、Flume和MQTT这些数据源将支持Python。
This category of sources require interfacing with external non-Spark libraries, some of them with complex dependencies (e.g., Kafka and Flume). Hence, to minimize issues related to version conflicts of dependencies, the functionality to create DStreams from these sources has been moved to separate libraries that can be linked to explicitly when necessary.
使用这类数据源需要依赖一些额外的代码库,有些依赖还挺复杂的(如:Kafka、Flume)。因此为了减少依赖项版本冲突问题,各个数据源 DStream的相关功能被分割到不同的代码包中,只有用到的时候才需要链接打包进来。
例如,如果你需要使用Twitter的tweets作为数据源,你 需要以下步骤:
- Linking: 将spark-streaming-twitter_2.10工件加入到SBT/Maven项目依赖中。
- Programming: 导入TwitterUtils class,然后调用 TwitterUtils.createStream 创建一个DStream,具体代码见下放。
- Deploying: 生成一个uber Jar包,并包含其所有依赖项(包括 spark-streaming-twitter_2.10及其自身的依赖树),再部署这个Jar包。部署详情请参考部署这一节(Deploying section)。
Note that these advanced sources are not available in the Spark shell, hence applications based on these advanced sources cannot be tested in the shell. If you really want to use them in the Spark shell you will have to download the corresponding Maven artifact’s JAR along with its dependencies and add it to the classpath.
Some of these advanced sources are as follows.
-
Kafka: Spark Streaming 2.0.0 is compatible with Kafka 0.8.2.1. See the Kafka Integration Guide for more details.
-
Flume: Spark Streaming 2.0.0 is compatible with Flume 1.6.0. See the Flume Integration Guide for more details.
-
Kinesis: Spark Streaming 2.0.0 is compatible with Kinesis Client Library 1.2.1. See the Kinesis Integration Guide for more details.
注意,高级数据源在spark-shell中不可用,因此不能用spark-shell来测试基于高级数据源的应用。如果真有需要的话,你需要自行下载相应数据源的Maven工件及其依赖项,并将这些Jar包部署到spark-shell的classpath中。
下面列举了一些高级数据源:
- Kafka: Spark Streaming 1.6.1 可兼容 Kafka 0.8.2.1。详见Kafka Integration Guide。
- Flume: Spark Streaming 1.6.1 可兼容 Flume 1.6.0 。详见Flume Integration Guide。
- Kinesis: Spark Streaming 1.6.1 可兼容 Kinesis Client Library 1.2.1。详见Kinesis Integration Guide。
- Twitter: Spark Streaming TwitterUtils 使用Twitter4j 通过 Twitter’s Streaming API 拉取公开tweets数据流。认证信息可以用任何Twitter4j所支持的方法(methods)。你可以获取所有的公开数据流,当然也可以基于某些关键词进行过滤。示例可以参考TwitterPopularTags 和 TwitterAlgebirdCMS。
Custom Sources
自定义数据源
Python API This is not yet supported in Python.
Python API 自定义数据源目前还不支持Python。
Input DStreams can also be created out of custom data sources. All you have to do is implement a user-defined receiver (see next section to understand what that is) that can receive data from the custom sources and push it into Spark. See the Custom Receiver Guide for details.
输入DStream也可以用自定义的方式创建。你需要做的只是实现一个自定义的接收器(receiver),以便从自定义的数据源接收数据,然后将数据推入Spark中。详情请参考自定义接收器指南(Custom Receiver Guide)。
Receiver Reliability
接收器可靠性
There can be two kinds of data sources based on their reliability. Sources (like Kafka and Flume) allow the transferred data to be acknowledged. If the system receiving data from these reliable sources acknowledges the received data correctly, it can be ensured that no data will be lost due to any kind of failure. This leads to two kinds of receivers:
- Reliable Receiver - A reliable receiver correctly sends acknowledgment to a reliable source when the data has been received and stored in Spark with replication.
- Unreliable Receiver - An unreliable receiver does not send acknowledgment to a source. This can be used for sources that do not support acknowledgment, or even for reliable sources when one does not want or need to go into the complexity of acknowledgment.
从可靠性角度来划分,大致有两种数据源。其中,像Kafka、Flume这样的数据源,它们支持对所传输的数据进行确认。系统收到这类可靠数据源过来的数据,然后发出确认信息,这样就能够确保任何失败情况下,都不会丢数据。因此我们可以将接收器也相应地分为两类:
- 可靠接收器(Reliable Receiver) – 可靠接收器会在成功接收并保存好Spark数据副本后,向可靠数据源发送确认信息。
- 不可靠接收器(Unreliable Receiver) – 不可靠接收器不会发送任何确认信息。不过这种接收器常用语于不支持确认的数据源,或者不想引入数据确认的复杂性的数据源。
The details of how to write a reliable receiver are discussed in the Custom Receiver Guide.
自定义接收器指南(Custom Receiver Guide)中详细讨论了如何写一个可靠接收器。
Transformations on DStreams
DStream支持的transformation算子
Similar to that of RDDs, transformations allow the data from the input DStream to be modified. DStreams support many of the transformations available on normal Spark RDD’s. Some of the common ones are as follows.
和RDD类似,DStream也支持从输入DStream经过各种transformation算子映射成新的DStream。DStream支持很多RDD上常见的transformation算子,一些常用的见下表:
| Transformation | Meaning |
|---|---|
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative and commutative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
A few of these transformations are worth discussing in more detail.
| Transformation算子 | 用途 |
|---|---|
| map(func) | 返回会一个新的DStream,并将源DStream中每个元素通过func映射为新的元素 |
| flatMap(func) | 和map类似,不过每个输入元素不再是映射为一个输出,而是映射为0到多个输出 |
| filter(func) | 返回一个新的DStream,并包含源DStream中被func选中(func返回true)的元素 |
| repartition(numPartitions) | 更改DStream的并行度(增加或减少分区数) |
| union(otherStream) | 返回新的DStream,包含源DStream和otherDStream元素的并集 |
| count() | 返回一个包含单元素RDDs的DStream,其中每个元素是源DStream中各个RDD中的元素个数 |
| reduce(func) | 返回一个包含单元素RDDs的DStream,其中每个元素是通过源RDD中各个RDD的元素经func(func输入两个参数并返回一个同类型结果数据)聚合得到的结果。func必须满足结合律,以便支持并行计算。 |
| countByValue() | 如果源DStream包含的元素类型为K,那么该算子返回新的DStream包含元素为(K, Long)键值对,其中K为源DStream各个元素,而Long为该元素出现的次数。 |
| reduceByKey(func, [numTasks]) | 如果源DStream 包含的元素为 (K, V) 键值对,则该算子返回一个新的也包含(K, V)键值对的DStream,其中V是由func聚合得到的。注意:默认情况下,该算子使用Spark的默认并发任务数(本地模式为2,集群模式下由 spark.default.parallelism 决定)。你可以通过可选参数numTasks来指定并发任务个数。 |
| join(otherStream, [numTasks]) | 如果源DStream包含元素为(K, V),同时otherDStream包含元素为(K, W)键值对,则该算子返回一个新的DStream,其中源DStream和otherDStream中每个K都对应一个 (K, (V, W))键值对元素。 |
| cogroup(otherStream, [numTasks]) | 如果源DStream包含元素为(K, V),同时otherDStream包含元素为(K, W)键值对,则该算子返回一个新的DStream,其中每个元素类型为包含(K, Seq[V], Seq[W])的tuple。 |
| transform(func) | 返回一个新的DStream,其包含的RDD为源RDD经过func操作后得到的结果。利用该算子可以对DStream施加任意的操作。 |
| updateStateByKey(func) | 返回一个包含新”状态”的DStream。源DStream中每个key及其对应的values会作为func的输入,而func可以用于对每个key的“状态”数据作任意的更新操作。 |
下面我们会挑几个transformation算子深入讨论一下。
UpdateStateByKey Operation
updateStateByKey算子
The updateStateByKey operation allows you to maintain arbitrary state while continuously updating it with new information. To use this, you will have to do two steps.
- Define the state - The state can be an arbitrary data type.
- Define the state update function - Specify with a function how to update the state using the previous state and the new values from an input stream.
In every batch, Spark will apply the state update function for all existing keys, regardless of whether they have new data in a batch or not. If the update function returns None then the key-value pair will be eliminated.
updateStateByKey 算子支持维护一个任意的状态。要实现这一点,只需要两步:
- 定义状态 – 状态数据可以是任意类型。
- 定义状态更新函数 – 定义好一个函数,其输入为数据流之前的状态和新的数据流数据,且可其更新步骤1中定义的输入数据流的状态。
在每一个批次数据到达后,Spark都会调用状态更新函数,来更新所有已有key(不管key是否存在于本批次中)的状态。如果状态更新函数返回None,则对应的键值对会被删除。
Let’s illustrate this with an example. Say you want to maintain a running count of each word seen in a text data stream. Here, the running count is the state and it is an integer. We define the update function as:
举例如下。假设你需要维护一个流式应用,统计数据流中每个单词的出现次数。这里将各个单词的出现次数这个整型数定义为状态。我们接下来定义状态更新函数如下:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}This is applied on a DStream containing words (say, the pairs DStream containing (word, 1) pairs in the earlier example).
该状态更新函数可以作用于一个包括(word, 1) 键值对的DStream上(见本文开头的例子)。
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)The update function will be called for each word, with newValues having a sequence of 1’s (from the (word, 1) pairs) and the runningCount having the previous count.
该状态更新函数会为每个单词调用一次,且相应的newValues是一个包含很多个”1″的数组(这些1来自于(word,1)键值对),而runningCount包含之前该单词的计数。本例的完整代码请参考 StatefulNetworkWordCount.scala。
Note that using updateStateByKey requires the checkpoint directory to be configured, which is discussed in detail in the checkpointing section.
注意,调用updateStateByKey前需要配置检查点目录,后续对此有详细的讨论,见检查点(checkpointing)这节。
Transform Operation
transform算子
The transform operation (along with its variations like transformWith) allows arbitrary RDD-to-RDD functions to be applied on a DStream. It can be used to apply any RDD operation that is not exposed in the DStream API. For example, the functionality of joining every batch in a data stream with another dataset is not directly exposed in the DStream API. However, you can easily use transform to do this. This enables very powerful possibilities. For example, one can do real-time data cleaning by joining the input data stream with precomputed spam information (maybe generated with Spark as well) and then filtering based on it.
transform算子(及其变体transformWith)可以支持任意的RDD到RDD的映射操作。也就是说,你可以用tranform算子来包装 任何DStream API所不支持的RDD算子。例如,将DStream每个批次中的RDD和另一个Dataset进行关联(join)操作,这个功能DStream API并没有直接支持。不过你可以用transform来实现这个功能,可见transform其实为DStream提供了非常强大的功能支持。比如说, 你可以用事先算好的垃圾信息,对DStream进行实时过滤。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform(rdd => {
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
})Note that the supplied function gets called in every batch interval. This allows you to do time-varying RDD operations, that is, RDD operations, number of partitions, broadcast variables, etc. can be changed between batches.
注意,这里transform包含的算子,其调用时间间隔和批次间隔是相同的。所以你可以基于时间改变对RDD的操作,如:在不同批次,调用不同的RDD算子,设置不同的RDD分区或者广播变量等。
Window Operations
基于窗口(window)的算子
Spark Streaming also provides windowed computations, which allow you to apply transformations over a sliding window of data. The following figure illustrates this sliding window.
Spark Streaming同样也提供基于时间窗口的计算,也就是说,你可以对某一个滑动时间窗内的数据施加特定tranformation算子。如下图所示:

As shown in the figure, every time the window slides over a source DStream, the source RDDs that fall within the window are combined and operated upon to produce the RDDs of the windowed DStream. In this specific case, the operation is applied over the last 3 time units of data, and slides by 2 time units. This shows that any window operation needs to specify two parameters.
- window length - The duration of the window (3 in the figure).
- sliding interval - The interval at which the window operation is performed (2 in the figure).
如上图所示,每次窗口滑动时,源DStream中落入窗口的RDDs就会被合并成新的windowed DStream。在上图的例子中,这个操作会施加于3个RDD单元,而滑动距离是2个RDD单元。由此可以得出任何窗口相关操作都需要指定一下两个参数:
- (窗口长度)window length – 窗口覆盖的时间长度(上图中为3)
- (滑动距离)sliding interval – 窗口启动的时间间隔(上图中为2)
These two parameters must be multiples of the batch interval of the source DStream (1 in the figure).
注意,这两个参数都必须是DStream批次间隔(上图中为1)的整数倍.
Let’s illustrate the window operations with an example. Say, you want to extend the earlier example by generating word counts over the last 30 seconds of data, every 10 seconds. To do this, we have to apply the reduceByKey operation on the pairs DStream of (word, 1) pairs over the last 30 seconds of data. This is done using the operation reduceByKeyAndWindow.
下面咱们举个例子。假设,你需要扩展前面的那个小栗子,你需要每隔10秒统计一下前30秒内的单词计数。为此,我们需要在包含(word, 1)键值对的DStream上,对最近30秒的数据调用reduceByKey算子。不过这些都可以简单地用一个 reduceByKeyAndWindow搞定。
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))Some of the common window operations are as follows. All of these operations take the said two parameters - windowLength and slideInterval.
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative and commutative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | A more efficient version of the above |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. |
以下列出了常用的窗口算子。所有这些算子都有前面提到的那两个参数 – 窗口长度 和 滑动距离。
| Transformation窗口算子 | 用途 |
|---|---|
| window(windowLength, slideInterval) | 将源DStream窗口化,并返回转化后的DStream |
| countByWindow(windowLength,slideInterval) | 返回数据流在一个滑动窗口内的元素个数 |
| reduceByWindow(func, windowLength,slideInterval) | 基于数据流在一个滑动窗口内的元素,用func做聚合,返回一个单元素数据流。func必须满足结合律,以便支持并行计算。 |
| reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks]) | 基于(K, V)键值对DStream,将一个滑动窗口内的数据进行聚合,返回一个新的包含(K,V)键值对的DStream,其中每个value都是各个key经过func聚合后的结果。 注意:如果不指定numTasks,其值将使用Spark的默认并行任务数(本地模式下为2,集群模式下由 spark.default.parallelism决定)。当然,你也可以通过numTasks来指定任务个数。 |
| reduceByKeyAndWindow(func, invFunc,windowLength,slideInterval, [numTasks]) | 和前面的reduceByKeyAndWindow() 类似,只是这个版本会用之前滑动窗口计算结果,递增地计算每个窗口的归约结果。当新的数据进入窗口时,这些values会被输入func做归约计算,而这 些数据离开窗口时,对应的这些values又会被输入 invFunc 做”反归约”计算。举个简单的例子,就是把新进入窗口数据中各个单词个数“增加”到各个单词统计结果上,同时把离开窗口数据中各个单词的统计个数从相应的 统计结果中“减掉”。不过,你的自己定义好”反归约”函数,即:该算子不仅有归约函数(见参数func),还得有一个对应的”反归约”函数(见参数中的 invFunc)。和前面的reduceByKeyAndWindow() 类似,该算子也有一个可选参数numTasks来指定并行任务数。注意,这个算子需要配置好检查点(checkpointing)才能用。 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 基于包含(K, V)键值对的DStream,返回新的包含(K, Long)键值对的DStream。其中的Long value都是滑动窗口内key出现次数的计数。 和前面的reduceByKeyAndWindow() 类似,该算子也有一个可选参数numTasks来指定并行任务数。 |
Join Operations
Join相关算子
Finally, its worth highlighting how easily you can perform different kinds of joins in Spark Streaming.
最后,值得一提的是,你在Spark Streaming中做各种关联(join)操作非常简单。
Stream-stream joins
流-流(Stream-stream)关联
Streams can be very easily joined with other streams.
一个数据流可以和另一个数据流直接关联。
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)Here, in each batch interval, the RDD generated by stream1 will be joined with the RDD generated by stream2. You can also do leftOuterJoin, rightOuterJoin, fullOuterJoin. Furthermore, it is often very useful to do joins over windows of the streams. That is pretty easy as well.
上面代码中,stream1的每个批次中的RDD会和stream2相应批次中的RDD进行join。同样,你可以类似地使用 leftOuterJoin, rightOuterJoin, fullOuterJoin 等。此外,你还可以基于窗口来join不同的数据流,其实现也很简单,如下;)
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)Stream-dataset joins
流-数据集(stream-dataset)关联
This has already been shown earlier while explain DStream.transform operation. Here is yet another example of joining a windowed stream with a dataset.
其实这种情况已经在前面的DStream.transform算子中介绍过了,这里再举个基于滑动窗口的例子。
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }In fact, you can also dynamically change the dataset you want to join against. The function provided to transform is evaluated every batch interval and therefore will use the current dataset that dataset reference points to.
实际上,在上面代码里,你可以动态地该表join的数据集(dataset)。传给tranform算子的操作函数会在每个批次重新求值,所以每次该函数都会用最新的dataset值,所以不同批次间你可以改变dataset的值。
The complete list of DStream transformations is available in the API documentation. For the Scala API, see DStream and PairDStreamFunctions. For the Java API, see JavaDStream and JavaPairDStream. For the Python API, see DStream.
完整的DStream transformation算子列表见API文档。Scala请参考 DStream 和 PairDStreamFunctions. Java请参考 JavaDStream 和 JavaPairDStream. Python见 DStream。
Output Operations on DStreams
DStream输出算子
Output operations allow DStream’s data to be pushed out to external systems like a database or a file systems. Since the output operations actually allow the transformed data to be consumed by external systems, they trigger the actual execution of all the DStream transformations (similar to actions for RDDs). Currently, the following output operations are defined:
| Output Operation | Meaning |
|---|---|
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream's contents as text files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream's contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]".Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream's contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". Python API This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
输出算子可以将DStream的数据推送到外部系统,如:数据库或者文件系统。因为输出算子会将最终完成转换的数据输出到外部系统,因此只有输出算 子调用时,才会真正触发DStream transformation算子的真正执行(这一点类似于RDD 的action算子)。目前所支持的输出算子如下表:
| 输出算子 | 用途 |
|---|---|
| print() | 在驱动器(driver)节点上打印DStream每个批次中的头十个元素。 Python API 对应的Python API为 pprint() |
| saveAsTextFiles(prefix, [suffix]) | 将DStream的内容保存到文本文件。 每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]” |
| saveAsObjectFiles(prefix, [suffix]) | 将DStream内容以序列化Java对象的形式保存到顺序文件中。 每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]”Python API 暂不支持Python |
| saveAsHadoopFiles(prefix, [suffix]) | 将DStream内容保存到Hadoop文件中。 每个批次一个文件,各文件命名规则为 “prefix-TIME_IN_MS[.suffix]”Python API 暂不支持Python |
| foreachRDD(func) | 这是最通用的输出算子了,该算子接收一个函数func,func将作用于DStream的每个RDD上。 func应该实现将每个RDD的数据推到外部系统中,比如:保存到文件或者写到数据库中。 注意,func函数是在streaming应用的驱动器进程中执行的,所以如果其中包含RDD的action算子,就会触发对DStream中RDDs的实际计算过程。 |
Design Patterns for using foreachRDD
使用foreachRDD的设计模式
dstream.foreachRDD is a powerful primitive that allows data to be sent out to external systems. However, it is important to understand how to use this primitive correctly and efficiently. Some of the common mistakes to avoid are as follows.
DStream.foreachRDD是一个非常强大的原生工具函数,用户可以基于此算子将DStream数据推送到外部系统中。不过用户需要了解如何正确而高效地使用这个工具。以下列举了一些常见的错误。
Often writing data to external system requires creating a connection object (e.g. TCP connection to a remote server) and using it to send data to a remote system. For this purpose, a developer may inadvertently try creating a connection object at the Spark driver, and then try to use it in a Spark worker to save records in the RDDs. For example (in Scala),
通常,对外部系统写入数据需要一些连接对象(如:远程server的TCP连接),以便发送数据给远程系统。因此,开发人员可能会不经意地在Spark驱动器(driver)进程中创建一个连接对象,然后又试图在Spark worker节点上使用这个连接。如下例所示:
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}This is incorrect as this requires the connection object to be serialized and sent from the driver to the worker. Such connection objects are rarely transferrable across machines. This error may manifest as serialization errors (connection object not serializable), initialization errors (connection object needs to be initialized at the workers), etc. The correct solution is to create the connection object at the worker.
这段代码是错误的,因为它需要把连接对象序列化,再从驱动器节点发送到worker节点。而这些连接对象通常都是不能跨节点(机器)传递的。比如,连接对 象通常都不能序列化,或者在另一个进程中反序列化后再次初始化(连接对象通常都需要初始化,因此从驱动节点发到worker节点后可能需要重新初始化) 等。解决此类错误的办法就是在worker节点上创建连接对象。
However, this can lead to another common mistake - creating a new connection for every record. For example,
然而,有些开发人员可能会走到另一个极端 – 为每条记录都创建一个连接对象,例如:
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}Typically, creating a connection object has time and resource overheads. Therefore, creating and destroying a connection object for each record can incur unnecessarily high overheads and can significantly reduce the overall throughput of the system. A better solution is to use rdd.foreachPartition - create a single connection object and send all the records in a RDD partition using that connection.
一般来说,连接对象是有时间和资源开销限制的。因此,对每条记录都进行一次连接对象的创建和销毁会增加很多不必要的开销,同时也大大减小了系统的吞吐量。 一个比较好的解决方案是使用 rdd.foreachPartition – 为RDD的每个分区创建一个单独的连接对象,示例如下:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}This amortizes the connection creation overheads over many records.
这样一来,连接对象的创建开销就摊到很多条记录上了。
Finally, this can be further optimized by reusing connection objects across multiple RDDs/batches. One can maintain a static pool of connection objects than can be reused as RDDs of multiple batches are pushed to the external system, thus further reducing the overheads.
最后,还有一个更优化的办法,就是在多个RDD批次之间复用连接对象。开发者可以维护一个静态连接池来保存连接对象,以便在不同批次的多个RDD之间共享同一组连接对象,示例如下:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}Note that the connections in the pool should be lazily created on demand and timed out if not used for a while. This achieves the most efficient sending of data to external systems.
注意,连接池中的连接应该是懒惰创建的,并且有确定的超时时间,超时后自动销毁。这个实现应该是目前发送数据最高效的实现方式。
Other points to remember:
-
DStreams are executed lazily by the output operations, just like RDDs are lazily executed by RDD actions. Specifically, RDD actions inside the DStream output operations force the processing of the received data. Hence, if your application does not have any output operation, or has output operations like
dstream.foreachRDD()without any RDD action inside them, then nothing will get executed. The system will simply receive the data and discard it. -
By default, output operations are executed one-at-a-time. And they are executed in the order they are defined in the application.
其他要点:
- DStream的转化执行也是懒惰的,需要输出算子来触发,这一点和RDD的懒惰执行由action算子触发很类似。特别地,DStream输出 算子中包含的RDD action算子会强制触发对所接收数据的处理。因此,如果你的Streaming应用中没有输出算子,或者你用了 dstream.foreachRDD(func)却没有在func中调用RDD action算子,那么这个应用只会接收数据,而不会处理数据,接收到的数据最后只是被简单地丢弃掉了。
- 默认地,输出算子只能一次执行一个,且按照它们在应用程序代码中定义的顺序执行。
Accumulators and Broadcast Variables
累加器和广播变量
Accumulators and Broadcast variables cannot be recovered from checkpoint in Spark Streaming. If you enable checkpointing and use Accumulators or Broadcast variables as well, you’ll have to create lazily instantiated singleton instances for Accumulators and Broadcast variables so that they can be re-instantiated after the driver restarts on failure. This is shown in the following example.
首先需要注意的是,累加器(Accumulators)和广播变量(Broadcast variables)是无法从Spark Streaming的检查点中恢复回来的。所以如果你开启了检查点功能,并同时在使用累加器和广播变量,那么你最好是使用懒惰实例化的单例模式,因为这样累加器和广播变量才能在驱动器(driver)故障恢复后重新实例化。代码示例如下:
object WordBlacklist {
@volatile private var instance: Broadcast[Seq[String]] = null
def getInstance(sc: SparkContext): Broadcast[Seq[String]] = {
if (instance == null) {
synchronized {
if (instance == null) {
val wordBlacklist = Seq("a", "b", "c")
instance = sc.broadcast(wordBlacklist)
}
}
}
instance
}
}
object DroppedWordsCounter {
@volatile private var instance: Accumulator[Long] = null
def getInstance(sc: SparkContext): Accumulator[Long] = {
if (instance == null) {
synchronized {
if (instance == null) {
instance = sc.accumulator(0L, "WordsInBlacklistCounter")
}
}
}
instance
}
}
wordCounts.foreachRDD((rdd: RDD[(String, Int)], time: Time) => {
// Get or register the blacklist Broadcast
val blacklist = WordBlacklist.getInstance(rdd.sparkContext)
// Get or register the droppedWordsCounter Accumulator
val droppedWordsCounter = DroppedWordsCounter.getInstance(rdd.sparkContext)
// Use blacklist to drop words and use droppedWordsCounter to count them
val counts = rdd.filter { case (word, count) =>
if (blacklist.value.contains(word)) {
droppedWordsCounter += count
false
} else {
true
}
}.collect()
val output = "Counts at time " + time + " " + counts
})See the full source code.
这里有完整代码:source code。
DataFrame and SQL Operations
DataFrame和SQL相关算子
You can easily use DataFrames and SQL operations on streaming data. You have to create a SQLContext using the SparkContext that the StreamingContext is using. Furthermore this has to done such that it can be restarted on driver failures. This is done by creating a lazily instantiated singleton instance of SQLContext. This is shown in the following example. It modifies the earlier word count example to generate word counts using DataFrames and SQL. Each RDD is converted to a DataFrame, registered as a temporary table and then queried using SQL.
在Streaming应用中可以调用DataFrames and SQL来 处理流式数据。开发者可以用通过StreamingContext中的SparkContext对象来创建一个SQLContext,并且,开发者需要确保一旦驱动器(driver)故障恢复后,该SQLContext对象能重新创建出来。同样,你还是可以使用懒惰创建的单例模式来实例化 SQLContext,如下面的代码所示,这里我们将最开始的那个例子做了一些修改,使用DataFrame和SQL来统计单词计数。其实就是,将每个 RDD都转化成一个DataFrame,然后注册成临时表,再用SQL查询这些临时表。
/** DataFrame operations inside your streaming program */
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// Get the singleton instance of SQLContext
val sqlContext = SQLContext.getOrCreate(rdd.sparkContext)
import sqlContext.implicits._
// Convert RDD[String] to DataFrame
val wordsDataFrame = rdd.toDF("word")
// Create a temporary view
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on DataFrame using SQL and print it
val wordCountsDataFrame =
sqlContext.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}See the full source code.
You can also run SQL queries on tables defined on streaming data from a different thread (that is, asynchronous to the running StreamingContext). Just make sure that you set the StreamingContext to remember a sufficient amount of streaming data such that the query can run. Otherwise the StreamingContext, which is unaware of the any asynchronous SQL queries, will delete off old streaming data before the query can complete. For example, if you want to query the last batch, but your query can take 5 minutes to run, then call streamingContext.remember(Minutes(5)) (in Scala, or equivalent in other languages).
See the DataFrames and SQL guide to learn more about DataFrames.
这里有完整代码:source code。
你也可以在其他线程里执行SQL查询(异步查询,即:执行SQL查询的线程和运行StreamingContext的线程不同)。不过这种情况下, 你需要确保查询的时候 StreamingContext 没有把所需的数据丢弃掉,否则StreamingContext有可能已将老的RDD数据丢弃掉了,那么异步查询的SQL语句也可能无法得到查询结果。举 个栗子,如果你需要查询上一个批次的数据,但是你的SQL查询可能要执行5分钟,那么你就需要StreamingContext至少保留最近5分钟的数 据:streamingContext.remember(Minutes(5)) (这是Scala为例,其他语言差不多)
更多DataFrame和SQL的文档见这里: DataFrames and SQL
MLlib Operations
MLlib算子
You can also easily use machine learning algorithms provided by MLlib. First of all, there are streaming machine learning algorithms (e.g. Streaming Linear Regression, Streaming KMeans, etc.) which can simultaneously learn from the streaming data as well as apply the model on the streaming data. Beyond these, for a much larger class of machine learning algorithms, you can learn a learning model offline (i.e. using historical data) and then apply the model online on streaming data. See the MLlib guide for more details.
MLlib 提供了很多机器学习算法。首先,你需要关注的是流式计算相关的机器学习算法(如:Streaming Linear Regression, Streaming KMeans),这些流式算法可以在流式数据上一边学习训练模型,一边用最新的模型处理数据。除此以外,对更多的机器学习算法而言,你需要离线训练这些模型,然后将训练好的模型用于在线的流式数据。详见MLlib。
Caching / Persistence
缓存/持久化
Similar to RDDs, DStreams also allow developers to persist the stream’s data in memory. That is, using the persist() method on a DStream will automatically persist every RDD of that DStream in memory. This is useful if the data in the DStream will be computed multiple times (e.g., multiple operations on the same data). For window-based operations like reduceByWindow and reduceByKeyAndWindow and state-based operations like updateStateByKey, this is implicitly true. Hence, DStreams generated by window-based operations are automatically persisted in memory, without the developer calling persist().
For input streams that receive data over the network (such as, Kafka, Flume, sockets, etc.), the default persistence level is set to replicate the data to two nodes for fault-tolerance.
Note that, unlike RDDs, the default persistence level of DStreams keeps the data serialized in memory. This is further discussed in the Performance Tuning section. More information on different persistence levels can be found in the Spark Programming Guide.
和RDD类似,DStream也支持将数据持久化到内存中。只需要调用 DStream的persist() 方法,该方法内部会自动调用DStream中每个RDD的persist方法进而将数据持久化到内存中。这对于可能需要计算很多次的DStream非常有 用(例如:对于同一个批数据调用多个算子)。对于基于滑动窗口的算子,如:reduceByWindow和reduceByKeyAndWindow,或 者有状态的算子,如:updateStateByKey,数据持久化就更重要了。因此,滑动窗口算子产生的DStream对象默认会自动持久化到内存中 (不需要开发者调用persist)。
对于从网络接收数据的输入数据流(如:Kafka、Flume、socket等),默认的持久化级别会将数据持久化到两个不同的节点上互为备份副本,以便支持容错。
注意,与RDD不同的是,DStream的默认持久化级别是将数据序列化到内存中。进一步的讨论见性能调优这一小节。关于持久化级别(或者存储级别)的更详细说明见Spark编程指南(Spark Programming Guide)。
Checkpointing
检查点
A streaming application must operate 24/7 and hence must be resilient to failures unrelated to the application logic (e.g., system failures, JVM crashes, etc.). For this to be possible, Spark Streaming needs to checkpoint enough information to a fault- tolerant storage system such that it can recover from failures. There are two types of data that are checkpointed.
- Metadata checkpointing - Saving of the information defining the streaming computation to fault-tolerant storage like HDFS. This is used to recover from failure of the node running the driver of the streaming application (discussed in detail later). Metadata includes:
- Configuration - The configuration that was used to create the streaming application.
- DStream operations - The set of DStream operations that define the streaming application.
- Incomplete batches - Batches whose jobs are queued but have not completed yet.
- Data checkpointing - Saving of the generated RDDs to reliable storage. This is necessary in some stateful transformations that combine data across multiple batches. In such transformations, the generated RDDs depend on RDDs of previous batches, which causes the length of the dependency chain to keep increasing with time. To avoid such unbounded increases in recovery time (proportional to dependency chain), intermediate RDDs of stateful transformations are periodically checkpointed to reliable storage (e.g. HDFS) to cut off the dependency chains.
To summarize, metadata checkpointing is primarily needed for recovery from driver failures, whereas data or RDD checkpointing is necessary even for basic functioning if stateful transformations are used.
一般来说Streaming 应用都需要7*24小时长期运行,所以必须对一些与业务逻辑无关的故障有很好的容错(如:系统故障、JVM崩溃等)。对于这些可能性,Spark Streaming 必须在检查点保存足够的信息到一些可容错的外部存储系统中,以便能够随时从故障中恢复回来。所以,检查点需要保存以下两种数据:
- 元数据检查点(Metadata checkpointing) – 保存流式计算逻辑的定义信息到外部可容错存储系统(如:HDFS)。主要用途是用于在故障后回复应用程序本身(后续详谈)。元数包括:
- Configuration – 创建Streaming应用程序的配置信息。
- DStream operations – 定义流式处理逻辑的DStream操作信息。
- Incomplete batches – 已经排队但未处理完的批次信息。
- 数据检查点(Data checkpointing) – 将生成的RDD保存到可靠的存储中。这对一些需要跨批次组合数据或者有状态的算子来说很有必要。在这种转换算子中,往往新生成的RDD是依赖于前几个批次 的RDD,因此随着时间的推移,有可能产生很长的依赖链条。为了避免在恢复数据的时候需要恢复整个依赖链条上所有的数据,检查点需要周期性地保存一些中间 RDD状态信息,以斩断无限制增长的依赖链条和恢复时间。
总之,元数据检查点主要是为了恢复驱动器节点上的故障,而数据或RDD检查点是为了支持对有状态转换操作的恢复。
When to enable Checkpointing
Checkpointing must be enabled for applications with any of the following requirements:
- Usage of stateful transformations - If either
updateStateByKeyorreduceByKeyAndWindow(with inverse function) is used in the application, then the checkpoint directory must be provided to allow for periodic RDD checkpointing. - Recovering from failures of the driver running the application - Metadata checkpoints are used to recover with progress information.
Note that simple streaming applications without the aforementioned stateful transformations can be run without enabling checkpointing. The recovery from driver failures will also be partial in that case (some received but unprocessed data may be lost). This is often acceptable and many run Spark Streaming applications in this way. Support for non-Hadoop environments is expected to improve in the future.
何时启用检查点
如果有以下情况出现,你就必须启用检查点了:
- 使用了有状态的转换算子(Usage of stateful transformations) – 不管是用了 updateStateByKey 还是用了 reduceByKeyAndWindow(有”反归约”函数的那个版本),你都必须配置检查点目录来周期性地保存RDD检查点。
- 支持驱动器故障中恢复(Recovering from failures of the driver running the application) – 这时候需要元数据检查点以便恢复流式处理的进度信息。
注意,一些简单的流式应用,如果没有用到前面所说的有状态转换算子,则完全可以不开启检查点。不过这样的话,驱动器(driver)故障恢复后,有 可能会丢失部分数据(有些已经接收但还未处理的数据可能会丢失)。不过通常这点丢失时可接受的,很多Spark Streaming应用也是这样运行的。对非Hadoop环境的支持未来还会继续改进。
How to configure Checkpointing
Checkpointing can be enabled by setting a directory in a fault-tolerant, reliable file system (e.g., HDFS, S3, etc.) to which the checkpoint information will be saved. This is done by using streamingContext.checkpoint(checkpointDirectory). This will allow you to use the aforementioned stateful transformations. Additionally, if you want to make the application recover from driver failures, you should rewrite your streaming application to have the following behavior.
- When the program is being started for the first time, it will create a new StreamingContext, set up all the streams and then call start().
- When the program is being restarted after failure, it will re-create a StreamingContext from the checkpoint data in the checkpoint directory.
This behavior is made simple by using StreamingContext.getOrCreate. This is used as follows.
如何配置检查点
检查点的启用,只需要设置好保存检查点信息的检查点目录即可,一般会会将这个目录设为一些可容错的、可靠性较高的文件系统(如:HDFS、S3 等)。开发者只需要调用 streamingContext.checkpoint(checkpointDirectory)。设置好检查点,你就可以使用前面提到的有状态转换 算子了。另外,如果你需要你的应用能够支持从驱动器故障中恢复,你可能需要重写部分代码,实现以下行为:
- 如果程序是首次启动,就需要new一个新的StreamingContext,并定义好所有的数据流处理,然后调用StreamingContext.start()。
- 如果程序是故障后重启,就需要从检查点目录中的数据中重新构建StreamingContext对象。
- Scala
- Java
- Python
不过这个行为可以用StreamingContext.getOrCreate来实现,示例如下:
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()
context.awaitTermination()If the checkpointDirectory exists, then the context will be recreated from the checkpoint data. If the directory does not exist (i.e., running for the first time), then the function functionToCreateContext will be called to create a new context and set up the DStreams. See the Scala example RecoverableNetworkWordCount. This example appends the word counts of network data into a file.
In addition to using getOrCreate one also needs to ensure that the driver process gets restarted automatically on failure. This can only be done by the deployment infrastructure that is used to run the application. This is further discussed in the Deployment section.
Note that checkpointing of RDDs incurs the cost of saving to reliable storage. This may cause an increase in the processing time of those batches where RDDs get checkpointed. Hence, the interval of checkpointing needs to be set carefully. At small batch sizes (say 1 second), checkpointing every batch may significantly reduce operation throughput. Conversely, checkpointing too infrequently causes the lineage and task sizes to grow, which may have detrimental effects. For stateful transformations that require RDD checkpointing, the default interval is a multiple of the batch interval that is at least 10 seconds. It can be set by using dstream.checkpoint(checkpointInterval). Typically, a checkpoint interval of 5 - 10 sliding intervals of a DStream is a good setting to try.
如果 checkpointDirectory 目录存在,则context对象会从检查点数据重新构建出来。如果该目录不存在(如:首次运行),则 functionToCreateContext 函数会被调用,创建一个新的StreamingContext对象并定义好DStream数据流。完整的示例请参见RecoverableNetworkWordCount,这个例子会将网络数据中的单词计数统计结果添加到一个文件中。
除了使用getOrCreate之外,开发者还需要确保驱动器进程能在故障后重启。这一点只能由应用的部署环境基础设施来保证。进一步的讨论见部署(Deployment)这一节。
另外需要注意的是,RDD检查点会增加额外的保存数据的开销。这可能会导致数据流的处理时间变长。因此,你必须仔细的调整检查点间隔时间。如果批次 间隔太小(比如:1秒),那么对每个批次保存检查点数据将大大减小吞吐量。另一方面,检查点保存过于频繁又会导致血统信息和任务个数的增加,这同样会影响 系统性能。对于需要RDD检查点的有状态转换算子,默认的间隔是批次间隔的整数倍,且最小10秒。开发人员可以这样来自定义这个间 隔:dstream.checkpoint(checkpointInterval)。一般推荐设为批次间隔时间的5~10倍。
Deploying Applications
部署应用
This section discusses the steps to deploy a Spark Streaming application.
本节中将主要讨论一下如何部署Spark Streaming应用。
Requirements
To run a Spark Streaming applications, you need to have the following.
-
Cluster with a cluster manager - This is the general requirement of any Spark application, and discussed in detail in the deployment guide.
-
Package the application JAR - You have to compile your streaming application into a JAR. If you are using
spark-submitto start the application, then you will not need to provide Spark and Spark Streaming in the JAR. However, if your application uses advanced sources (e.g. Kafka, Flume), then you will have to package the extra artifact they link to, along with their dependencies, in the JAR that is used to deploy the application. For example, an application usingKafkaUtilswill have to includespark-streaming-kafka-0-8_2.11and all its transitive dependencies in the application JAR. -
Configuring sufficient memory for the executors - Since the received data must be stored in memory, the executors must be configured with sufficient memory to hold the received data. Note that if you are doing 10 minute window operations, the system has to keep at least last 10 minutes of data in memory. So the memory requirements for the application depends on the operations used in it.
-
Configuring checkpointing - If the stream application requires it, then a directory in the Hadoop API compatible fault-tolerant storage (e.g. HDFS, S3, etc.) must be configured as the checkpoint directory and the streaming application written in a way that checkpoint information can be used for failure recovery. See the checkpointing section for more details.
- Configuring automatic restart of the application driver - To automatically recover from a driver failure, the deployment infrastructure that is used to run the streaming application must monitor the driver process and relaunch the driver if it fails. Different cluster managers have different tools to achieve this.
- Spark Standalone - A Spark application driver can be submitted to run within the Spark Standalone cluster (see cluster deploy mode), that is, the application driver itself runs on one of the worker nodes. Furthermore, the Standalone cluster manager can be instructed to supervise the driver, and relaunch it if the driver fails either due to non-zero exit code, or due to failure of the node running the driver. See cluster mode and supervise in the Spark Standalone guide for more details.
- YARN - Yarn supports a similar mechanism for automatically restarting an application. Please refer to YARN documentation for more details.
- Mesos - Marathon has been used to achieve this with Mesos.
-
Configuring write ahead logs - Since Spark 1.2, we have introduced write ahead logs for achieving strong fault-tolerance guarantees. If enabled, all the data received from a receiver gets written into a write ahead log in the configuration checkpoint directory. This prevents data loss on driver recovery, thus ensuring zero data loss (discussed in detail in the Fault-tolerance Semantics section). This can be enabled by setting the configuration parameter
spark.streaming.receiver.writeAheadLog.enabletotrue. However, these stronger semantics may come at the cost of the receiving throughput of individual receivers. This can be corrected by running more receivers in parallel to increase aggregate throughput. Additionally, it is recommended that the replication of the received data within Spark be disabled when the write ahead log is enabled as the log is already stored in a replicated storage system. This can be done by setting the storage level for the input stream toStorageLevel.MEMORY_AND_DISK_SER. While using S3 (or any file system that does not support flushing) for write ahead logs, please remember to enablespark.streaming.driver.writeAheadLog.closeFileAfterWriteandspark.streaming.receiver.writeAheadLog.closeFileAfterWrite. See Spark Streaming Configuration for more details. - Setting the max receiving rate - If the cluster resources is not large enough for the streaming application to process data as fast as it is being received, the receivers can be rate limited by setting a maximum rate limit in terms of records / sec. See the configuration parameters
spark.streaming.receiver.maxRatefor receivers andspark.streaming.kafka.maxRatePerPartitionfor Direct Kafka approach. In Spark 1.5, we have introduced a feature called backpressure that eliminate the need to set this rate limit, as Spark Streaming automatically figures out the rate limits and dynamically adjusts them if the processing conditions change. This backpressure can be enabled by setting the configuration parameterspark.streaming.backpressure.enabledtotrue.
前提条件
要运行一个Spark Streaming 应用,你首先需要具备以下条件:
- 集群以及集群管理器 – 这是一般Spark应用的基本要求,详见 deployment guide。
- 给Spark应用打个JAR包 – 你需要将你的应用打成一个JAR包。如果使用
spark-submit提交应用,那么你不需要提供Spark和Spark Streaming的相关JAR包。但是,如果你使用了高级数据源(advanced sources – 如:Kafka、Flume、Twitter等),那么你需要将这些高级数据源相关的JAR包及其依赖一起打包并部署。例如,如果你使用了 TwitterUtils,那么就必须将spark-streaming-twitter_2.10及其相关依赖都打到应用的JAR包中。 - 为执行器(executor)预留足够的内存 – 执行器必须配置预留好足够的内存,因为接受到的数据都得存在内存里。注意,如果某些窗口长度达到10分钟,那也就是说你的系统必须知道保留10分钟的数据在内存里。可见,到底预留多少内存是取决于你的应用处理逻辑的。
- 配置检查点 – 如果你的流式应用需要检查点,那么你需要配置一个Hadoop API兼容的可容错存储目录作为检查点目录,流式应用的信息会写入这个目录,故障恢复时会用到这个目录下的数据。详见前面的检查点小节。
- 配置驱动程序自动重启 – 流式应用自动恢复的前提就是,部署基础设施能够监控驱动器进程,并且能够在其故障时,自动重启之。不同的集群管理器有不同的工具来实现这一功能:
- Spark独立部署 – Spark独立部署集群可以支持将Spark应用的驱动器提交到集群的某个worker节点上运行。同时,Spark的集群管理器可以对该驱动器进程进行 监控,一旦驱动器退出且返回非0值,或者因worker节点原始失败,Spark集群管理器将自动重启这个驱动器。详见Spark独立部署指南(Spark Standalone guide)。
- YARN – YARN支持和独立部署类似的重启机制。详细请参考YARN的文档。
- Mesos – Mesos上需要用Marathon来实现这一功能。
- 配置WAL(write ahead log)- 从Spark 1.2起,我们引入了write ahead log来提高容错性。如果启用这个功能,则所有接收到的数据都会以write ahead log形式写入配置好的检查点目录中。这样就能确保数据零丢失(容错语义有详细的讨论)。用户只需将 spark.streaming.receiver.writeAheadLog 设为true。不过,这同样可能会导致接收器的吞吐量下降。不过你可以启动多个接收器并行接收数据,从而提升整体的吞吐量(more receivers in parallel)。 另外,建议在启用WAL后禁用掉接收数据多副本功能,因为WAL其实已经是存储在一个多副本存储系统中了。你只需要把存储级别设为 StorageLevel.MEMORY_AND_DISK_SER。如果是使用S3(或者其他不支持flushing的文件系统)存储WAL,一定要记 得启用这两个标识:spark.streaming.driver.writeAheadLog.closeFileAfterWrite 和 spark.streaming.receiver.writeAheadLog.closeFileAfterWrite。更详细请参考: Spark Streaming Configuration。
- 设置好最大接收速率 – 如果集群可用资源不足以跟上接收数据的速度,那么可以在接收器设置一下最大接收速率,即:每秒接收记录的条数。相关的主要配置 有:spark.streaming.receiver.maxRate,如果使用Kafka Direct API 还需要设置 spark.streaming.kafka.maxRatePerPartition。从Spark 1.5起,我们引入了backpressure的概念来动态地根据集群处理速度,评估并调整该接收速率。用户只需将 spark.streaming.backpressure.enabled设为true即可启用该功能。
Upgrading Application Code
升级应用代码
If a running Spark Streaming application needs to be upgraded with new application code, then there are two possible mechanisms.
-
The upgraded Spark Streaming application is started and run in parallel to the existing application. Once the new one (receiving the same data as the old one) has been warmed up and is ready for prime time, the old one be can be brought down. Note that this can be done for data sources that support sending the data to two destinations (i.e., the earlier and upgraded applications).
-
The existing application is shutdown gracefully (see
StreamingContext.stop(...)orJavaStreamingContext.stop(...)for graceful shutdown options) which ensure data that has been received is completely processed before shutdown. Then the upgraded application can be started, which will start processing from the same point where the earlier application left off. Note that this can be done only with input sources that support source-side buffering (like Kafka, and Flume) as data needs to be buffered while the previous application was down and the upgraded application is not yet up. And restarting from earlier checkpoint information of pre-upgrade code cannot be done. The checkpoint information essentially contains serialized Scala/Java/Python objects and trying to deserialize objects with new, modified classes may lead to errors. In this case, either start the upgraded app with a different checkpoint directory, or delete the previous checkpoint directory.
升级Spark Streaming应用程序代码,可以使用以下两种方式:
- 新的Streaming程序和老的并行跑一段时间,新程序完成初始化以后,再关闭老的。注意,这种方式适用于能同时发送数据到多个目标的数据源(即:数据源同时将数据发给新老两个Streaming应用程序)。
- 老程序能够优雅地退出(参考
StreamingContext.stop(...)orJavaStreamingContext.stop(...)), 即:确保所收到的数据都已经处理完毕后再退出。然后再启动新的Streaming程序,而新程序将接着在老程序退出点上继续拉取数据。注意,这种方式需要 数据源支持数据缓存(或者叫数据堆积,如:Kafka、Flume),因为在新旧程序交接的这个空档时间,数据需要在数据源处缓存。目前还不能支持从检查 点重启,因为检查点存储的信息包含老程序中的序列化对象信息,在新程序中将其反序列化可能会出错。这种情况下,只能要么指定一个新的检查点目录,要么删除 老的检查点目录。
Monitoring Applications
应用监控
Beyond Spark’s monitoring capabilities, there are additional capabilities specific to Spark Streaming. When a StreamingContext is used, the Spark web UI shows an additional Streaming tab which shows statistics about running receivers (whether receivers are active, number of records received, receiver error, etc.) and completed batches (batch processing times, queueing delays, etc.). This can be used to monitor the progress of the streaming application.
The following two metrics in web UI are particularly important:
- Processing Time - The time to process each batch of data.
- Scheduling Delay - the time a batch waits in a queue for the processing of previous batches to finish.
If the batch processing time is consistently more than the batch interval and/or the queueing delay keeps increasing, then it indicates that the system is not able to process the batches as fast they are being generated and is falling behind. In that case, consider reducing the batch processing time.
The progress of a Spark Streaming program can also be monitored using the StreamingListener interface, which allows you to get receiver status and processing times. Note that this is a developer API and it is likely to be improved upon (i.e., more information reported) in the future.
除了Spark自身的监控能力(monitoring capabilities)之外,对Spark Streaming还有一些额外的监控功能可用。如果实例化了StreamingContext,那么你可以在Spark web UI上看到多出了一个Streaming tab页,上面显示了正在运行的接收器(是否活跃,接收记录的条数,失败信息等)和处理完的批次信息(批次处理时间,查询延时等)。这些信息都可以用来监控streaming应用。
web UI上有两个度量特别重要:
- 批次处理耗时(Processing Time) – 处理单个批次耗时
- 批次调度延时(Scheduling Delay) -各批次在队列中等待时间(等待上一个批次处理完)
如果批次处理耗时一直比批次间隔时间大,或者批次调度延时持续上升,就意味着系统处理速度跟不上数据接收速度。这时候你就得考虑一下怎么把批次处理时间降下来(reducing)。
Spark Streaming程序的处理进度可以用StreamingListener接口来监听,这个接口可以监听到接收器的状态和处理时间。不过需要注意的是,这是一个developer API接口,换句话说这个接口未来很可能会变动(可能会增加更多度量信息)。
Performance Tuning
Getting the best performance out of a Spark Streaming application on a cluster requires a bit of tuning. This section explains a number of the parameters and configurations that can be tuned to improve the performance of you application. At a high level, you need to consider two things:
-
Reducing the processing time of each batch of data by efficiently using cluster resources.
-
Setting the right batch size such that the batches of data can be processed as fast as they are received (that is, data processing keeps up with the data ingestion).
性能调优
要获得Spark Streaming应用的最佳性能需要一点点调优工作。本节将深入解释一些能够改进Streaming应用性能的配置和参数。总体上来说,你需要考虑这两方面的事情:
- 提高集群资源利用率,减少单批次处理耗时。
- 设置合适的批次大小,以便使数据处理速度能跟上数据接收速度。
Reducing the Batch Processing Times
There are a number of optimizations that can be done in Spark to minimize the processing time of each batch. These have been discussed in detail in the Tuning Guide. This section highlights some of the most important ones.
减少批次处理时间
有不少优化手段都可以减少Spark对每个批次的处理时间。细节将在优化指南(Tuning Guide)中详谈。这里仅列举一些最重要的。
Level of Parallelism in Data Receiving
Receiving data over the network (like Kafka, Flume, socket, etc.) requires the data to be deserialized and stored in Spark. If the data receiving becomes a bottleneck in the system, then consider parallelizing the data receiving. Note that each input DStream creates a single receiver (running on a worker machine) that receives a single stream of data. Receiving multiple data streams can therefore be achieved by creating multiple input DStreams and configuring them to receive different partitions of the data stream from the source(s). For example, a single Kafka input DStream receiving two topics of data can be split into two Kafka input streams, each receiving only one topic. This would run two receivers, allowing data to be received in parallel, thus increasing overall throughput. These multiple DStreams can be unioned together to create a single DStream. Then the transformations that were being applied on a single input DStream can be applied on the unified stream. This is done as follows.
数据接收并发度
跨网络接收数据(如:从Kafka、Flume、socket等接收数据)需要在Spark中序列化并存储数据。
如果接收数据的过程是系统瓶颈,那么可以考虑增加数据接收的并行度。注意,每个输入DStream只包含一个单独的接收器(receiver,运行 约worker节点),每个接收器单独接收一路数据流。所以,配置多个输入DStream就能从数据源的不同分区分别接收多个数据流。例如,可以将从 Kafka拉取两个topic的数据流分成两个Kafka输入数据流,每个数据流拉取其中一个topic的数据,这样一来会同时有两个接收器并行地接收数 据,因而增加了总体的吞吐量。同时,另一方面我们又可以把这些DStream数据流合并成一个,然后可以在合并后的DStream上使用任何可用的 transformation算子。示例代码如下:
val numStreams = 5
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print()Another parameter that should be considered is the receiver’s blocking interval, which is determined by the configuration parameter spark.streaming.blockInterval. For most receivers, the received data is coalesced together into blocks of data before storing inside Spark’s memory. The number of blocks in each batch determines the number of tasks that will be used to process the received data in a map-like transformation. The number of tasks per receiver per batch will be approximately (batch interval / block interval). For example, block interval of 200 ms will create 10 tasks per 2 second batches. If the number of tasks is too low (that is, less than the number of cores per machine), then it will be inefficient as all available cores will not be used to process the data. To increase the number of tasks for a given batch interval, reduce the block interval. However, the recommended minimum value of block interval is about 50 ms, below which the task launching overheads may be a problem.
An alternative to receiving data with multiple input streams / receivers is to explicitly repartition the input data stream (using inputStream.repartition(<number of partitions>)). This distributes the received batches of data across the specified number of machines in the cluster before further processing.
另一个可以考虑优化的参数就是接收器的阻塞间隔,该参数由配置参数(configuration parameter)spark.streaming.blockInterval 决定。大多数接收器都会将数据合并成一个个数据块,然后再保存到spark内存中。对于map类算子来说,每个批次中数据块的个数将会决定处理这批数据并 行任务的个数,每个接收器每批次数据处理任务数约等于 (批次间隔 / 数据块间隔)。例如,对于2秒的批次间隔,如果数据块间隔为200ms,则创建的并发任务数为10。如果任务数太少(少于单机cpu core个数),则资源利用不够充分。如需增加这个任务数,对于给定的批次间隔来说,只需要减少数据块间隔即可。不过,我们还是建议数据块间隔至少要 50ms,否则任务的启动开销占比就太高了。
另一个切分接收数据流的方法是,显示地将输入数据流划分为多个分区(使用 inputStream.repartition(<number of partitions>))。该操作会在处理前,将数据散开重新分发到集群中多个节点上。
Level of Parallelism in Data Processing
数据处理并发度
Cluster resources can be under-utilized if the number of parallel tasks used in any stage of the computation is not high enough. For example, for distributed reduce operations like reduceByKey and reduceByKeyAndWindow, the default number of parallel tasks is controlled by the spark.default.parallelism configuration property. You can pass the level of parallelism as an argument (see PairDStreamFunctions documentation), or set the spark.default.parallelism configuration property to change the default.
在计算各个阶段(stage)中,任何一个阶段的并发任务数不足都有可能造成集群资源利用率低。例如,对于reduce类的算子, 如:reduceByKey 和 reduceByKeyAndWindow,其默认的并发任务数是由 spark.default.parallelism 决定的。你既可以修改这个默认值(spark.default.parallelism),也可以通过参数指定这个并发数量(见PairDStreamFunctions)。
Data Serialization
The overheads of data serialization can be reduced by tuning the serialization formats. In the case of streaming, there are two types of data that are being serialized.
-
Input data: By default, the input data received through Receivers is stored in the executors’ memory with StorageLevel.MEMORY_AND_DISK_SER_2. That is, the data is serialized into bytes to reduce GC overheads, and replicated for tolerating executor failures. Also, the data is kept first in memory, and spilled over to disk only if the memory is insufficient to hold all of the input data necessary for the streaming computation. This serialization obviously has overheads – the receiver must deserialize the received data and re-serialize it using Spark’s serialization format.
-
Persisted RDDs generated by Streaming Operations: RDDs generated by streaming computations may be persisted in memory. For example, window operations persist data in memory as they would be processed multiple times. However, unlike the Spark Core default of StorageLevel.MEMORY_ONLY, persisted RDDs generated by streaming computations are persisted with StorageLevel.MEMORY_ONLY_SER (i.e. serialized) by default to minimize GC overheads.
In both cases, using Kryo serialization can reduce both CPU and memory overheads. See the Spark Tuning Guide for more details. For Kryo, consider registering custom classes, and disabling object reference tracking (see Kryo-related configurations in the Configuration Guide).
In specific cases where the amount of data that needs to be retained for the streaming application is not large, it may be feasible to persist data (both types) as deserialized objects without incurring excessive GC overheads. For example, if you are using batch intervals of a few seconds and no window operations, then you can try disabling serialization in persisted data by explicitly setting the storage level accordingly. This would reduce the CPU overheads due to serialization, potentially improving performance without too much GC overheads.
调整数据的序列化格式可以大大减少数据序列化的开销。在spark Streaming中主要有两种类型的数据需要序列化:
- 输入数据: 默认地,接收器收到的数据是以 StorageLevel.MEMORY_AND_DISK_SER_2 的 存储级别存储到执行器(executor)内存中的。也就是说,收到的数据会被序列化以减少GC开销,同时保存两个副本以容错。同时,数据会优先保存在内 存里,当内存不足时才吐出到磁盘上。很明显,这个过程中会有数据序列化的开销 – 接收器首先将收到的数据反序列化,然后再以spark所配置指定的格式来序列化数据。
- Streaming算子所生产的持久化的RDDs: Streaming计算所生成的RDD可能会持久化到内存中。例如,基于窗口的算子会将数据持久化到内存,因为窗口数据可能会多次处理。所不同的是,spark core默认用 StorageLevel.MEMORY_ONLY 级别持久化RDD数据,而spark streaming默认使用StorageLevel.MEMORY_ONLY_SER 级别持久化接收到的数据,以便尽量减少GC开销。
不管是上面哪一种数据,都可以使用Kryo序列化来减少CPU和内存开销,详见Spark Tuning Guide。另,对于Kryo,你可以考虑这些优化:注册自定义类型,禁用对象引用跟踪(详见Configuration Guide)。
在一些特定的场景下,如果数据量不是很大,那么你可以考虑不用序列化格式,不过你需要注意的是取消序列化是否会导致大量的GC开销。例如,如果你的 批次间隔比较短(几秒)并且没有使用基于窗口的算子,这种情况下你可以考虑禁用序列化格式。这样可以减少序列化的CPU开销以优化性能,同时GC的增长也 不多。
Task Launching Overheads
If the number of tasks launched per second is high (say, 50 or more per second), then the overhead of sending out tasks to the slaves may be significant and will make it hard to achieve sub-second latencies. The overhead can be reduced by the following changes:
- Execution mode: Running Spark in Standalone mode or coarse-grained Mesos mode leads to better task launch times than the fine-grained Mesos mode. Please refer to the Running on Mesos guide for more details.
These changes may reduce batch processing time by 100s of milliseconds, thus allowing sub-second batch size to be viable.
任务启动开销
如果每秒启动的任务数过多(比如每秒50个以上),那么将任务发送给slave节点的开销会明显增加,那么你也就很难达到亚秒级(sub-second)的延迟。不过以下两个方法可以减少任务的启动开销:
- 任务序列化(Task Serialization): 使用Kryo来序列化任务,以减少任务本身的大小,从而提高发送任务的速度。任务的序列化格式是由 spark.closure.serializer 属性决定的。不过,目前还不支持闭包序列化,未来的版本可能会增加对此的支持。
- 执行模式(Execution mode): Spark独立部署或者Mesos粗粒度模式下任务的启动时间比Mesos细粒度模式下的任务启动时间要短。详见Running on Mesos guide。
这些调整有可能能够减少100ms的批次处理时间,这也使得亚秒级的批次间隔成为可能。
Setting the Right Batch Interval
For a Spark Streaming application running on a cluster to be stable, the system should be able to process data as fast as it is being received. In other words, batches of data should be processed as fast as they are being generated. Whether this is true for an application can be found by monitoring the processing times in the streaming web UI, where the batch processing time should be less than the batch interval.
Depending on the nature of the streaming computation, the batch interval used may have significant impact on the data rates that can be sustained by the application on a fixed set of cluster resources. For example, let us consider the earlier WordCountNetwork example. For a particular data rate, the system may be able to keep up with reporting word counts every 2 seconds (i.e., batch interval of 2 seconds), but not every 500 milliseconds. So the batch interval needs to be set such that the expected data rate in production can be sustained.
A good approach to figure out the right batch size for your application is to test it with a conservative batch interval (say, 5-10 seconds) and a low data rate. To verify whether the system is able to keep up with the data rate, you can check the value of the end-to-end delay experienced by each processed batch (either look for “Total delay” in Spark driver log4j logs, or use the StreamingListener interface). If the delay is maintained to be comparable to the batch size, then system is stable. Otherwise, if the delay is continuously increasing, it means that the system is unable to keep up and it therefore unstable. Once you have an idea of a stable configuration, you can try increasing the data rate and/or reducing the batch size. Note that a momentary increase in the delay due to temporary data rate increases may be fine as long as the delay reduces back to a low value (i.e., less than batch size).
设置合适的批次间隔
要想streaming应用在集群上稳定运行,那么系统处理数据的速度必须能跟上其接收数据的速度。换句话说,批次数据的处理速度应该和其生成速度一样快。对于特定的应用来说,可以从其对应的监控(monitoring)页面上观察验证,页面上显示的处理耗时应该要小于批次间隔时间。
根据spark streaming计算的性质,在一定的集群资源限制下,批次间隔的值会极大地影响系统的数据处理能力。例如,在WordCountNetwork示例 中,对于特定的数据速率,一个系统可能能够在批次间隔为2秒时跟上数据接收速度,但如果把批次间隔改为500毫秒系统可能就处理不过来了。所以,批次间隔 需要谨慎设置,以确保生产系统能够处理得过来。
要找出适合的批次间隔,你可以从一个比较保守的批次间隔值(如5~10秒)开始测试。要验证系统是否能跟上当前的数据接收速率,你可能需要检查一下端到端的批次处理延迟(可以看看Spark驱动器log4j日志中的Total delay,也可以用StreamingListener接 口来检测)。如果这个延迟能保持和批次间隔差不多,那么系统基本就是稳定的。否则,如果这个延迟持久在增长,也就是说系统跟不上数据接收速度,那也就意味 着系统不稳定。一旦系统文档下来后,你就可以尝试提高数据接收速度,或者减少批次间隔值。不过需要注意,瞬间的延迟增长可以只是暂时的,只要这个延迟后续 会自动降下来就没有问题(如:降到小于批次间隔值)
Memory Tuning
Tuning the memory usage and GC behavior of Spark applications has been discussed in great detail in the Tuning Guide. It is strongly recommended that you read that. In this section, we discuss a few tuning parameters specifically in the context of Spark Streaming applications.
The amount of cluster memory required by a Spark Streaming application depends heavily on the type of transformations used. For example, if you want to use a window operation on the last 10 minutes of data, then your cluster should have sufficient memory to hold 10 minutes worth of data in memory. Or if you want to use updateStateByKey with a large number of keys, then the necessary memory will be high. On the contrary, if you want to do a simple map-filter-store operation, then the necessary memory will be low.
In general, since the data received through receivers is stored with StorageLevel.MEMORY_AND_DISK_SER_2, the data that does not fit in memory will spill over to the disk. This may reduce the performance of the streaming application, and hence it is advised to provide sufficient memory as required by your streaming application. Its best to try and see the memory usage on a small scale and estimate accordingly.
内存调优
Spark应用内存占用和GC调优已经在调优指南(Tuning Guide)中有详细的讨论。墙裂建议你读一读那篇文档。本节中,我们只是讨论一下几个专门用于Spark Streaming的调优参数。
Spark Streaming应用在集群中占用的内存量严重依赖于具体所使用的tranformation算子。例如,如果想要用一个窗口算子操纵最近10分钟的数 据,那么你的集群至少需要在内存里保留10分钟的数据;另一个例子是updateStateByKey,如果key很多的话,相对应的保存的key的 state也会很多,而这些都需要占用内存。而如果你的应用只是做一个简单的 “映射-过滤-存储”(map-filter-store)操作的话,那需要的内存就很少了。
一般情况下,streaming接收器接收到的数据会以 StorageLevel.MEMORY_AND_DISK_SER_2 这个存储级别存到spark中,也就是说,如果内存装不下,数据将被吐到磁盘上。数据吐到磁盘上会大大降低streaming应用的性能,因此还是建议根 据你的应用处理的数据量,提供充足的内存。最好就是,一边小规模地放大内存,再观察评估,然后再放大,再评估。
Another aspect of memory tuning is garbage collection. For a streaming application that requires low latency, it is undesirable to have large pauses caused by JVM Garbage Collection.
There are a few parameters that can help you tune the memory usage and GC overheads:
-
Persistence Level of DStreams: As mentioned earlier in the Data Serialization section, the input data and RDDs are by default persisted as serialized bytes. This reduces both the memory usage and GC overheads, compared to deserialized persistence. Enabling Kryo serialization further reduces serialized sizes and memory usage. Further reduction in memory usage can be achieved with compression (see the Spark configuration
spark.rdd.compress), at the cost of CPU time. -
Clearing old data: By default, all input data and persisted RDDs generated by DStream transformations are automatically cleared. Spark Streaming decides when to clear the data based on the transformations that are used. For example, if you are using a window operation of 10 minutes, then Spark Streaming will keep around the last 10 minutes of data, and actively throw away older data. Data can be retained for a longer duration (e.g. interactively querying older data) by setting
streamingContext.remember. -
CMS Garbage Collector: Use of the concurrent mark-and-sweep GC is strongly recommended for keeping GC-related pauses consistently low. Even though concurrent GC is known to reduce the overall processing throughput of the system, its use is still recommended to achieve more consistent batch processing times. Make sure you set the CMS GC on both the driver (using
--driver-java-optionsinspark-submit) and the executors (using Spark configurationspark.executor.extraJavaOptions). -
Other tips: To further reduce GC overheads, here are some more tips to try.
- Persist RDDs using the
OFF_HEAPstorage level. See more detail in the Spark Programming Guide. - Use more executors with smaller heap sizes. This will reduce the GC pressure within each JVM heap.
- Persist RDDs using the
另一个内存调优的方向就是垃圾回收。因为streaming应用往往都需要低延迟,所以肯定不希望出现大量的或耗时较长的JVM垃圾回收暂停。
以下是一些能够帮助你减少内存占用和GC开销的参数或手段:
- DStream持久化级别(Persistence Level of DStreams): 前面数据序列化(Data Serialization) 这小节已经提到过,默认streaming的输入RDD会被持久化成序列化的字节流。相对于非序列化数据,这样可以减少内存占用和GC开销。如果启用 Kryo序列化,还能进一步减少序列化数据大小和内存占用量。如果你还需要进一步减少内存占用的话,可以开启数据压缩(通过 spark.rdd.compress这个配置设定),只不过数据压缩会增加CPU消耗。
- 清除老数据(Clearing old data): 默认情况下,所有的输入数据以及DStream的transformation算子产生的持久化RDD都是自动清理的。Spark Streaming会根据所使用的transformation算子来清理老数据。例如,你用了一个窗口操作处理最近10分钟的数据,那么Spark Streaming会保留至少10分钟的数据,并且会主动把更早的数据都删掉。当然,你可以设置 streamingContext.remember 以保留更长时间段的数据(比如:你可能会需要交互式地查询更老的数据)。
- CMS垃圾回收器(CMS Garbage Collector): 为了尽量减少GC暂停的时间,我们墙裂建议使用CMS垃圾回收器(concurrent mark-and-sweep GC)。虽然CMS GC会稍微降低系统的总体吞吐量,但我们仍建议使用它,因为CMS GC能使批次处理的时间保持在一个比较恒定的水平上。最后,你需要确保在驱动器(通过spark-submit中的–driver-java- options设置)和执行器(使用spark.executor.extraJavaOptions配置参数)上都设置了CMS GC。
- 其他提示: 如果还想进一步减少GC开销,以下是更进一步的可以尝试的手段:
- 配合Tachyon使用堆外内存来持久化RDD。详见Spark编程指南(Spark Programming Guide)
- 使用更多但是更小的执行器进程。这样GC压力就会分散到更多的JVM堆中。
Fault-tolerance Semantics
容错语义
In this section, we will discuss the behavior of Spark Streaming applications in the event of failures.
本节中,我们将讨论Spark Streaming应用在出现失败时的具体行为。
Background
To understand the semantics provided by Spark Streaming, let us remember the basic fault-tolerance semantics of Spark’s RDDs.
- An RDD is an immutable, deterministically re-computable, distributed dataset. Each RDD remembers the lineage of deterministic operations that were used on a fault-tolerant input dataset to create it.
- If any partition of an RDD is lost due to a worker node failure, then that partition can be re-computed from the original fault-tolerant dataset using the lineage of operations.
- Assuming that all of the RDD transformations are deterministic, the data in the final transformed RDD will always be the same irrespective of failures in the Spark cluster.
Spark operates on data in fault-tolerant file systems like HDFS or S3. Hence, all of the RDDs generated from the fault-tolerant data are also fault-tolerant. However, this is not the case for Spark Streaming as the data in most cases is received over the network (except when fileStream is used). To achieve the same fault-tolerance properties for all of the generated RDDs, the received data is replicated among multiple Spark executors in worker nodes in the cluster (default replication factor is 2). This leads to two kinds of data in the system that need to recovered in the event of failures:
- Data received and replicated - This data survives failure of a single worker node as a copy of it exists on one of the other nodes.
- Data received but buffered for replication - Since this is not replicated, the only way to recover this data is to get it again from the source.
Furthermore, there are two kinds of failures that we should be concerned about:
- Failure of a Worker Node - Any of the worker nodes running executors can fail, and all in-memory data on those nodes will be lost. If any receivers were running on failed nodes, then their buffered data will be lost.
- Failure of the Driver Node - If the driver node running the Spark Streaming application fails, then obviously the SparkContext is lost, and all executors with their in-memory data are lost.
With this basic knowledge, let us understand the fault-tolerance semantics of Spark Streaming.
背景
要理解Spark Streaming所提供的容错语义,我们首先需要回忆一下Spark RDD所提供的基本容错语义。
- RDD是不可变的,可重算的,分布式数据集。每个RDD都记录了其创建算子的血统信息,其中每个算子都以可容错的数据集作为输入数据。
- 如果RDD的某个分区因为节点失效而丢失,则该分区可以根据RDD的血统信息以及相应的原始输入数据集重新计算出来。
- 假定所有RDD transformation算子计算过程都是确定性的,那么通过这些算子得到的最终RDD总是包含相同的数据,而与Spark集群的是否故障无关。
Spark主要操作一些可容错文件系统的数据,如:HDFS或S3。因此,所有从这些可容错数据源产生的RDD也是可容错的。然而,对于Spark Streaming并非如此,因为多数情况下Streaming需要从网络远端接收数据,这回导致Streaming的数据源并不可靠(尤其是对于使用了 fileStream的应用)。要实现RDD相同的容错属性,数据接收就必须用多个不同worker节点上的Spark执行器来实现(默认副本因子是 2)。因此一旦出现故障,系统需要恢复两种数据:
- 接收并保存了副本的数据 – 数据不会因为单个worker节点故障而丢失,因为有副本!
- 接收但尚未保存副本数据 – 因为数据并没有副本,所以一旦故障,只能从数据源重新获取。
此外,还有两种可能的故障类型需要考虑:
- Worker节点故障 – 任何运行执行器的worker节点一旦故障,节点上内存中的数据都会丢失。如果这些节点上有接收器在运行,那么其包含的缓存数据也会丢失。
- Driver节点故障 – 如果Spark Streaming的驱动节点故障,那么很显然SparkContext对象就没了,所有执行器及其内存数据也会丢失。
有了以上这些基本知识,下面我们就进一步了解一下Spark Streaming的容错语义。
Definitions
The semantics of streaming systems are often captured in terms of how many times each record can be processed by the system. There are three types of guarantees that a system can provide under all possible operating conditions (despite failures, etc.)
- At most once: Each record will be either processed once or not processed at all.
- At least once: Each record will be processed one or more times. This is stronger than at-most once as it ensure that no data will be lost. But there may be duplicates.
- Exactly once: Each record will be processed exactly once - no data will be lost and no data will be processed multiple times. This is obviously the strongest guarantee of the three.
定义
流式系统的可靠度语义可以据此来分类:单条记录在系统中被处理的次数保证。一个流式系统可能提供保证必定是以下三种之一(不管系统是否出现故障):
- 至多一次(At most once): 每条记录要么被处理一次,要么就没有处理。
- 至少一次(At least once): 每条记录至少被处理过一次(一次或多次)。这种保证能确保没有数据丢失,比“至多一次”要强。但有可能出现数据重复。
- 精确一次(Exactly once): 每条记录都精确地只被处理一次 – 也就是说,既没有数据丢失,也不会出现数据重复。这是三种保证中最强的一种。
Basic Semantics
In any stream processing system, broadly speaking, there are three steps in processing the data.
-
Receiving the data: The data is received from sources using Receivers or otherwise.
-
Transforming the data: The received data is transformed using DStream and RDD transformations.
-
Pushing out the data: The final transformed data is pushed out to external systems like file systems, databases, dashboards, etc.
If a streaming application has to achieve end-to-end exactly-once guarantees, then each step has to provide an exactly-once guarantee. That is, each record must be received exactly once, transformed exactly once, and pushed to downstream systems exactly once. Let’s understand the semantics of these steps in the context of Spark Streaming.
-
Receiving the data: Different input sources provide different guarantees. This is discussed in detail in the next subsection.
-
Transforming the data: All data that has been received will be processed exactly once, thanks to the guarantees that RDDs provide. Even if there are failures, as long as the received input data is accessible, the final transformed RDDs will always have the same contents.
-
Pushing out the data: Output operations by default ensure at-least once semantics because it depends on the type of output operation (idempotent, or not) and the semantics of the downstream system (supports transactions or not). But users can implement their own transaction mechanisms to achieve exactly-once semantics. This is discussed in more details later in the section.
基础语义
任何流式处理系统一般都会包含以下三个数据处理步骤:
- 数据接收(Receiving the data): 从数据源拉取数据。
- 数据转换(Transforming the data): 将接收到的数据进行转换(使用DStream和RDD transformation算子)。
- 数据推送(Pushing out the data): 将转换后最终数据推送到外部文件系统,数据库或其他展示系统。
如果Streaming应用需要做到端到端的“精确一次”的保证,那么就必须在以上三个步骤中各自都保证精确一次:即,每条记录必须,只接收一次、处理一次、推送一次。下面让我们在Spark Streaming的上下文环境中来理解一下这三个步骤的语义:
- 数据接收: 不同数据源提供的保证不同,下一节再详细讨论。
- 数据转换: 所有的数据都会被“精确一次”处理,这要归功于RDD提供的保障。即使出现故障,只要数据源还能访问,最终所转换得到的RDD总是包含相同的内容。
- 数据推送: 输出操作默认保证“至少一次”的语义,是否能“精确一次”还要看所使用的输出算子(是否幂等)以及下游系统(是否支持事务)。不过用户也可以开发自己的事务机制来实现“精确一次”语义。这个后续会有详细讨论。
Semantics of Received Data
Different input sources provide different guarantees, ranging from at-least once to exactly once. Read for more details.
With Files
If all of the input data is already present in a fault-tolerant file system like HDFS, Spark Streaming can always recover from any failure and process all of the data. This gives exactly-once semantics, meaning all of the data will be processed exactly once no matter what fails.
With Receiver-based Sources
For input sources based on receivers, the fault-tolerance semantics depend on both the failure scenario and the type of receiver. As we discussed earlier, there are two types of receivers:
- Reliable Receiver - These receivers acknowledge reliable sources only after ensuring that the received data has been replicated. If such a receiver fails, the source will not receive acknowledgment for the buffered (unreplicated) data. Therefore, if the receiver is restarted, the source will resend the data, and no data will be lost due to the failure.
- Unreliable Receiver - Such receivers do not send acknowledgment and therefore can lose data when they fail due to worker or driver failures.
Depending on what type of receivers are used we achieve the following semantics. If a worker node fails, then there is no data loss with reliable receivers. With unreliable receivers, data received but not replicated can get lost. If the driver node fails, then besides these losses, all of the past data that was received and replicated in memory will be lost. This will affect the results of the stateful transformations.
To avoid this loss of past received data, Spark 1.2 introduced write ahead logs which save the received data to fault-tolerant storage. With the write ahead logs enabled and reliable receivers, there is zero data loss. In terms of semantics, it provides an at-least once guarantee.
接收数据语义
不同的输入源提供不同的数据可靠性级别,从“至少一次”到“精确一次”。
从文件接收数据
如果所有的输入数据都来源于可容错的文件系统,如HDFS,那么Spark Streaming就能在任何故障中恢复并处理所有的数据。这种情况下就能保证精确一次语义,也就是说不管出现什么故障,所有的数据总是精确地只处理一次,不多也不少。
基于接收器接收数据
对于基于接收器的输入源,容错语义将同时依赖于故障场景和接收器类型。前面也已经提到过,spark Streaming主要有两种类型的接收器:
- 可靠接收器 – 这类接收器会在数据接收并保存好副本后,向可靠数据源发送确认信息。这类接收器故障时,是不会给缓存的(已接收但尚未保存副本)数据发送确认信息。因此,一旦接收器重启,没有收到确认的数据,会重新从数据源再获取一遍,所以即使有故障也不会丢数据。
- 不可靠接收器 – 这类接收器不会发送确认信息,因此一旦worker和driver出现故障,就有可能会丢失数据。
对于不同的接收器,我们可以获得如下不同的语义。如果一个worker节点故障了,对于可靠接收器来书,不会有数据丢失。而对于不可靠接收器,缓存 的(接收但尚未保存副本)数据可能会丢失。如果driver节点故障了,除了接收到的数据之外,其他的已经接收且已经保存了内存副本的数据都会丢失,这将 会影响有状态算子的计算结果。
为了避免丢失已经收到且保存副本的数,从 spark 1.2 开始引入了WAL(write ahead logs),以便将这些数据写入到可容错的存储中。只要你使用可靠接收器,同时启用WAL(write ahead logs enabled),那么久再也不用为数据丢失而担心了。并且这时候,还能提供“至少一次”的语义保证。
The following table summarizes the semantics under failures:
| Deployment Scenario | Worker Failure | Driver Failure |
|---|---|---|
| Spark 1.1 or earlier, OR Spark 1.2 or later without write ahead logs | Buffered data lost with unreliable receivers Zero data loss with reliable receivers At-least once semantics | Buffered data lost with unreliable receivers Past data lost with all receivers Undefined semantics |
| Spark 1.2 or later with write ahead logs | Zero data loss with reliable receivers At-least once semantics | Zero data loss with reliable receivers and files At-least once semantics |
下表总结了故障情况下的各种语义:
| 部署场景 | Worker 故障 | Driver 故障 |
|---|---|---|
| Spark 1.1及以前版本 或者 Spark 1.2及以后版本,且未开启WAL | 若使用不可靠接收器,则可能丢失缓存(已接收但尚未保存副本)数据; 若使用可靠接收器,则没有数据丢失,且提供至少一次处理语义 | 若使用不可靠接收器,则缓存数据和已保存数据都可能丢失; 若使用可靠接收器,则没有缓存数据丢失,但已保存数据可能丢失,且不提供语义保证 |
| Spark 1.2及以后版本,并启用WAL | 若使用可靠接收器,则没有数据丢失,且提供至少一次语义保证 | 若使用可靠接收器和文件,则无数据丢失,且提供至少一次语义保证 |
With Kafka Direct API
In Spark 1.3, we have introduced a new Kafka Direct API, which can ensure that all the Kafka data is received by Spark Streaming exactly once. Along with this, if you implement exactly-once output operation, you can achieve end-to-end exactly-once guarantees. This approach (experimental as of Spark 2.0.0) is further discussed in the Kafka Integration Guide.
从Kafka Direct API接收数据
从Spark 1.3开始,我们引入Kafka Direct API,该API能为Kafka数据源提供“精确一次”语义保证。有了这个输入API,再加上输出算子的“精确一次”保证,你就能真正实现端到端的“精确 一次”语义保证。(改功能截止Spark 1.6.1还是实验性的)更详细的说明见:Kafka Integration Guide。
Semantics of output operations
Output operations (like foreachRDD) have at-least once semantics, that is, the transformed data may get written to an external entity more than once in the event of a worker failure. While this is acceptable for saving to file systems using the saveAs***Files operations (as the file will simply get overwritten with the same data), additional effort may be necessary to achieve exactly-once semantics. There are two approaches.
-
Idempotent updates: Multiple attempts always write the same data. For example,
saveAs***Filesalways writes the same data to the generated files. -
Transactional updates: All updates are made transactionally so that updates are made exactly once atomically. One way to do this would be the following.
- Use the batch time (available in
foreachRDD) and the partition index of the RDD to create an identifier. This identifier uniquely identifies a blob data in the streaming application. -
Update external system with this blob transactionally (that is, exactly once, atomically) using the identifier. That is, if the identifier is not already committed, commit the partition data and the identifier atomically. Else, if this was already committed, skip the update.
dstream.foreachRDD { (rdd, time) => rdd.foreachPartition { partitionIterator => val partitionId = TaskContext.get.partitionId() val uniqueId = generateUniqueId(time.milliseconds, partitionId) // use this uniqueId to transactionally commit the data in partitionIterator } }
- Use the batch time (available in
从Kafka Direct API接收数据
从Spark 1.3开始,我们引入Kafka Direct API,该API能为Kafka数据源提供“精确一次”语义保证。有了这个输入API,再加上输出算子的“精确一次”保证,你就能真正实现端到端的“精确 一次”语义保证。(改功能截止Spark 1.6.1还是实验性的)更详细的说明见:Kafka Integration Guide。
输出算子的语义
输出算子(如 foreachRDD)提供“至少一次”语义保证,也就是说,如果worker故障,单条输出数据可能会被多次写入外部实体中。不过这对于文件系统来说是 可以接受的(使用saveAs***Files 多次保存文件会覆盖之前的),所以我们需要一些额外的工作来实现“精确一次”语义。主要有两种实现方式:
- 幂等更新(Idempotent updates): 就是说多次操作,产生的结果相同。例如,多次调用saveAs***Files保存的文件总是包含相同的数据。
- 事务更新(Transactional updates): 所有的更新都是事务性的,这样一来就能保证更新的原子性。以下是一种实现方式:
- 用批次时间(在foreachRDD中可用)和分区索引创建一个唯一标识,该标识代表流式应用中唯一的一个数据块。
- 基于这个标识建立更新事务,并使用数据块数据更新外部系统。也就是说,如果该标识未被提交,则原子地将标识代表的数据更新到外部系统。否则,就认为该标识已经被提交,直接忽略之。
dstream.foreachRDD { (rdd, time) => rdd.foreachPartition { partitionIterator => val partitionId = TaskContext.get.partitionId() val uniqueId = generateUniqueId(time.milliseconds, partitionId) // 使用uniqueId作为事务的唯一标识,基于uniqueId实现partitionIterator所指向数据的原子事务提交 } }
Migration Guide from 0.9.1 or below to 1.x
Between Spark 0.9.1 and Spark 1.0, there were a few API changes made to ensure future API stability. This section elaborates the steps required to migrate your existing code to 1.0.
Input DStreams: All operations that create an input stream (e.g., StreamingContext.socketStream, FlumeUtils.createStream, etc.) now returns InputDStream / ReceiverInputDStream (instead of DStream) for Scala, and JavaInputDStream / JavaPairInputDStream / JavaReceiverInputDStream / JavaPairReceiverInputDStream (instead of JavaDStream) for Java. This ensures that functionality specific to input streams can be added to these classes in the future without breaking binary compatibility. Note that your existing Spark Streaming applications should not require any change (as these new classes are subclasses of DStream/JavaDStream) but may require recompilation with Spark 1.0.
Custom Network Receivers: Since the release to Spark Streaming, custom network receivers could be defined in Scala using the class NetworkReceiver. However, the API was limited in terms of error handling and reporting, and could not be used from Java. Starting Spark 1.0, this class has been replaced by Receiver which has the following advantages.
- Methods like
stopandrestarthave been added to for better control of the lifecycle of a receiver. See the custom receiver guide for more details. - Custom receivers can be implemented using both Scala and Java.
在Spark 0.9.1和Spark 1.0之间,有一些API接口变更,变更目的是为了保障未来版本API的稳定。本节将详细说明一下从已有版本迁移升级到1.0所需的工作。
输入DStream(Input DStreams): 所有创建输入流的算子(如:StreamingContext.socketStream, FlumeUtils.createStream 等)的返回值不再是DStream(对Java来说是JavaDStream),而是 InputDStream / ReceiverInputDStream(对Java来说是JavaInputDStream / JavaPairInputDStream /JavaReceiverInputDStream / JavaPairReceiverInputDStream)。这样才能确保特定输入流的功能能够在未来持续增加到这些class中,而不会打破二进制兼容性。注意,已有的Spark Streaming应用应该不需要任何代码修改(新的返回类型都是DStream的子类),只不过需要基于Spark 1.0重新编译一把。
定制网络接收器(Custom Network Receivers): 自从Spark Streaming发布以来,Scala就能基于NetworkReceiver来定制网络接收器。但由于错误处理和汇报API方便的限制,该类型不能在Java中使用。所以Spark 1.0开始,用 Receiver 来替换掉这个NetworkReceiver,主要的好处如下:
- 该类型新增了stop和restart方法,便于控制接收器的生命周期。详见custom receiver guide。
- 定制接收器用Scala和Java都能实现。
To migrate your existing custom receivers from the earlier NetworkReceiver to the new Receiver, you have to do the following.
- Make your custom receiver class extend
org.apache.spark.streaming.receiver.Receiverinstead oforg.apache.spark.streaming.dstream.NetworkReceiver. - Earlier, a BlockGenerator object had to be created by the custom receiver, to which received data was added for being stored in Spark. It had to be explicitly started and stopped from
onStart()andonStop()methods. The new Receiver class makes this unnecessary as it adds a set of methods namedstore(<data>)that can be called to store the data in Spark. So, to migrate your custom network receiver, remove any BlockGenerator object (does not exist any more in Spark 1.0 anyway), and usestore(...)methods on received data.
为了将已有的基于NetworkReceiver的自定义接收器迁移到Receiver上来,你需要如下工作:
- 首先你的自定义接收器类型需要从
org.apache.spark.streaming.receiver.Receiver继承,而不再是org.apache.spark.streaming.dstream.NetworkReceiver。 - 原先,我们需要在自定义接收器中创建一个BlockGenerator来保存接收到的数据。你必须显示的实现onStart() 和 onStop() 方法。而在新的Receiver class中,这些都不需要了,你只需要调用它的store系列的方法就能将数据保存到Spark中。所以你接下来需要做的迁移工作就是,删除 BlockGenerator对象(这个类型在Spark 1.0之后也没有了~),然后用store(…)方法来保存接收到的数据。
Actor-based Receivers: The Actor-based Receiver APIs have been moved to DStream Akka. Please refer to the project for more details.
基于Actor的接收器(Actor-based Receivers): 从actor class继承后,并实现了org.apache.spark.streaming.receiver.Receiver 后,即可从Akka Actors中获取数据。获取数据的类被重命名为 org.apache.spark.streaming.receiver.ActorHelper ,而保存数据的pushBlocks(…)方法也被重命名为 store(…)。其他org.apache.spark.streaming.receivers包中的工具类也被移到 org.apache.spark.streaming.receiver 包下并重命名,新的类名应该比之前更加清晰。
Where to Go from Here
更多的参考资料
- Additional guides
- External DStream data sources:
- API documentation
- Scala docs
- Java docs
- Python docs
- More examples in Scala and Java and Python
- Paper and video describing Spark Streaming.














 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









