







2.1.1 CommitLog文件(物理队列)
CommitLog是用于存储真实的物理消息的结构,保存消息元数据,所有消息到达Broker后都会保存到commitLog文件,这里需要强调的是所有topic的消息都会统一保存在commitLog中。
举个例子:当前集群有TopicA, TopicB,
这两个Toipc的消息会按照消息到达的先后顺序保存到同一个commitLog中,而不是每个Topic有自己独立的commitLog
onsumeQueue是逻辑队列,仅仅存储了CommitLog的位移而已,真实的存储都在本结构中。
首先这里会使用CommitLog.this.topicQueueTable.put(key, queueOffset),其中的key是 topic-queueId, queueOffset是当前这个key中的消息数,每增加一个消息增加一(不会自减);
这里queueOffset的用途如下:每次用户请求putMessage的时候,将queueOffset返回给客户端使用,这里的queueoffset表示逻辑上的队列偏移。消息存放物理文件,每台broker上的commitLog被本机器所有queue共享不做区分
commitlog文件的存储地址:$HOME\store\commitlog\${fileName}
一个消息存储单元长度是不定的,顺序写但是随机读
每个commitLog文件的默认大小为 1G =1024*1024*1024,满1G之后会自动新建CommitLog文件做保存数据用
commitlog的文件名fileName,名字长度为20位,左边补零,剩余为起始偏移量;比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当这个文件满了,
第二个文件名字为00000000001073741824,起始偏移量为1073741824,以此类推,第三个文件名字为00000000002147483648,起始偏移量为2147483648消息存储的时候会顺序写入文件,
当文件满了,写入下一个文件。
CommitLog的清理机制:
按时间清理,rocketmq默认会清理3天前的commitLog文件;
按磁盘水位清理:当磁盘使用量到达磁盘容量75%,开始清理最老的commitLog文件。
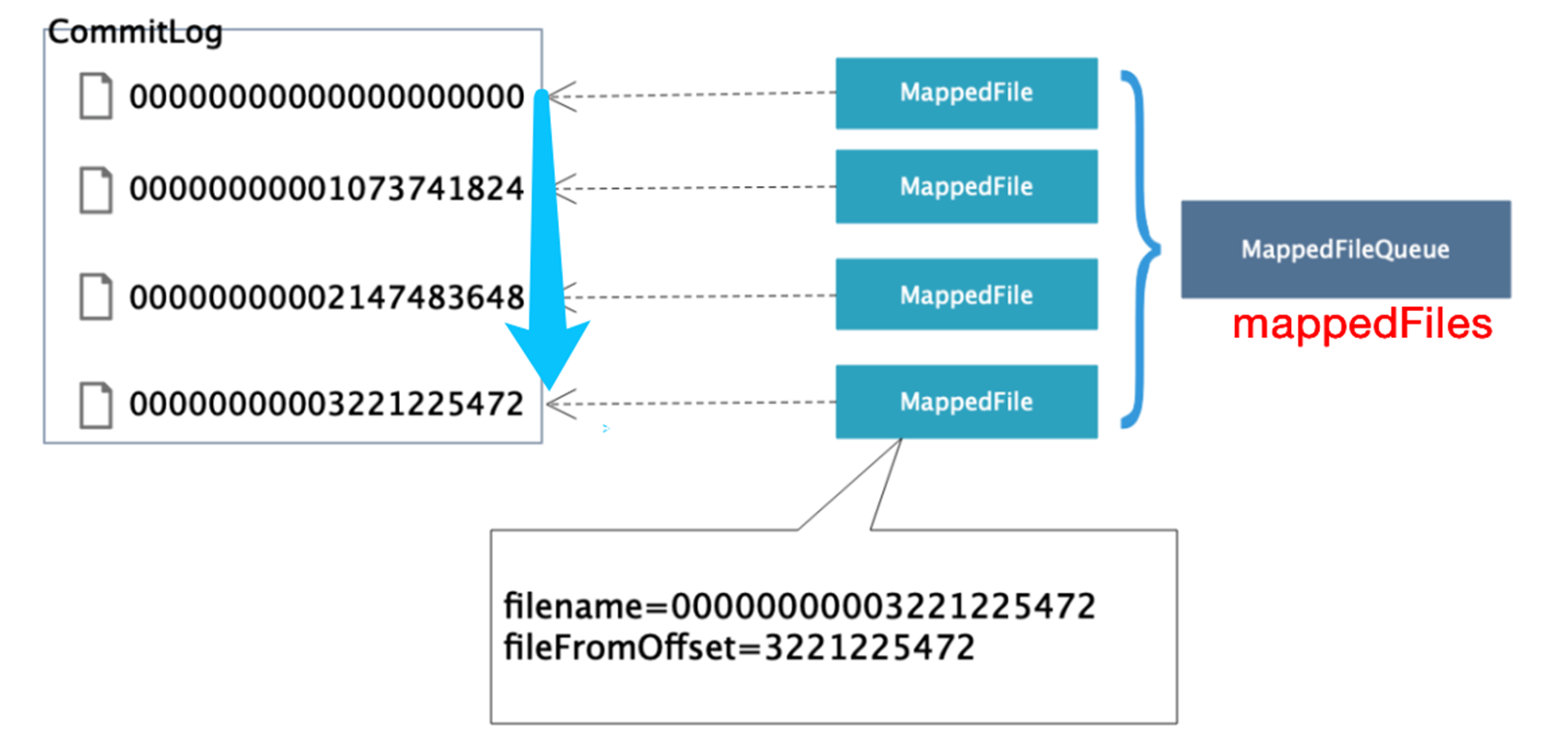
1)、CommitLog 文件生成规则
偏移量:每个 CommitLog 文件的大小为 1G,一般情况下第一个 CommitLog 的起始偏移量为 0,第二个 CommitLog 的起始偏移量为 1073741824 (1G = 1073741824byte)。
2)、怎么知道消息存储在哪个 CommitLog 文件上?
假设 1073742827 为物理偏移量(物理偏移量也即全局偏移量),则其对应的相对偏移量为 1003(1003 = 1073742827 - 1073741824),并且该偏移量位于第二个 CommitLog。
index 和 ComsumerQueue 中都有消息对应的物理偏移量,通过物理偏移量就可以计算出该消息位于哪个 CommitLog 文件上。

文件地址:${user.home} \store\${commitlog}\${fileName}
消息存储结构:
flag 这个标志值rocketmq不做处理,只存储后透传
QUEUEOFFSET这个值是个自增值不是真正的consume queue的偏移量,可以代表这个队列中消息的个数,要通过这个值查找到consume queue中数据,QUEUEOFFSET * 20才是偏移地址
PHYSICALOFFSET 代表消息在commitLog中的物理起始地址偏移量
SYSFLAG消息标志,指明消息是事物事物状态等等消息特征
BORNTIMESTAMP 消息产生端(producer)的时间戳
BORNHOST 消息产生端(producer)地址(address:port)
STORETIMESTAMP 消息在broker存储时间
STOREHOSTADDRESS 消息存储到broker的地址(address:port)
RECONSUMETIMES消息被某个订阅组重新消费了几次(订阅组之间独立计数),因为重试消息发送到了topic名字为%retry%groupName的队列queueId=0的队列中去了
Prepared Transaction Offset 表示是prepared状态的事物消息
2.1.2 ConsumeQueue文件组织:
ConsumerQueue相当于CommitLog的索引文件,消费者消费时会先从ConsumerQueue中查找消息的在commitLog中的offset,再去CommitLog中找元数据。
如果某个消息只在CommitLog中有数据,没在ConsumerQueue中, 则消费者无法消费,Rocktet的事务消息就是这个原理
Consumequeue类对应的是每个topic和queuId下面的所有文件,相当于字典的目录用来指定消息在消息的真正的物理文件commitLog上的位置
每条数据的结构如下图所示:

消息的起始物理偏移量physical offset(long 8字节)+消息大小size(int 4字节)+tagsCode(long 8字节)。
每个topic下的每个queue都有一个对应的consumequeue文件。
文件默认存储路径:${user.home} \store\consumequeue\${topicName}\${queueId}\${fileName}
每个文件由30W条数据组成,每条数据的大小为20个字节,从而每个文件的默认大小为600万个字节(consume queue中存储单元是一个20字节定长的数据)是顺序写顺序读
commitLogOffset是指这条消息在commitLog文件实际偏移量
size就是指消息大小
消息tag的哈希值
ConsumeQueue几个重要的字段
private final String topic;
private final int queueId;//队列id
private final ByteBuffer byteBufferIndex;// 写索引时用到的ByteBuffer
private long maxPhysicOffset = -1;// 最后一个消息对应的物理Offset
每个cosumequeue文件的名称fileName,名字长度为20位,左边补零,剩余为起始偏移量;
比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为600W,
当第一个文件满之后创建的第二个文件的名字为00000000000006000000,起始偏移量为6000000,以此类推,
第三个文件名字为0000
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









