







我看了许多教程,之前练习过爬取百度百科和汽车之家,都没有成功,可能功力不到,有些问题总看不出到底是哪里出了毛病。
我看得其中有一个教程是做post请求爬取的,我拖拖拉拉的做了许久,恰好爬到数据了,因此特地发个文纪念一下。
声明一个在很多教程里面都看到的内容,不要频繁的、大批量的使用代码去访问别人的网站,服务器是一种很贵的资源。
步骤一:尝试爬取数据
# urllib_post.py
# -*- coding:utf-8 -*-
from urllib.request import urlopen
from urllib.request import Request
from urllib import parse
req = Request("https://kuai.baidu.com/pc/schedule/schedulelist")
postData = parse.urlencode([
("startcityid", 224),
("arrivalcityid", 289),
("startdatetime", 1489507200),
("us", "pc"),
("hmsr", ""),
("hmmd", ""),
("hmpl", ""),
("hmkw", ""),
("hmci", ""),
])
print(postData)
req.add_header("Referer","https://kuai.baidu.com/pc")
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36")
resp = urlopen(req, data=postData.encode(encoding='utf-8'))#bytes(postData, "utf-8")
print(resp.read().decode("utf-8"))我的版本是Python3.5,使用urllib库请求网页数据。据说Python2.x版本的urllib库是分为urllib和urllib2的,urllib2是urllib的升级,但是二者的方法却不重合,经常一起使用。
在请求网页内容的时候,使用了.add_header添加请求头,伪装成浏览器进行请求,这样不容易被爬取的网站拒绝。
直接用浏览器请求网站在控制台(F12→Network→Header)里面看到的是下面这样儿的:
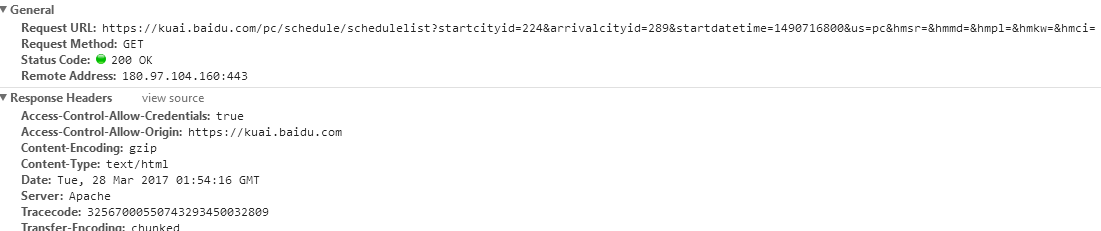
这里我有一个疑问,就是看到Request Method:GET我突然不知道自己是做的get请求还是post请求了。
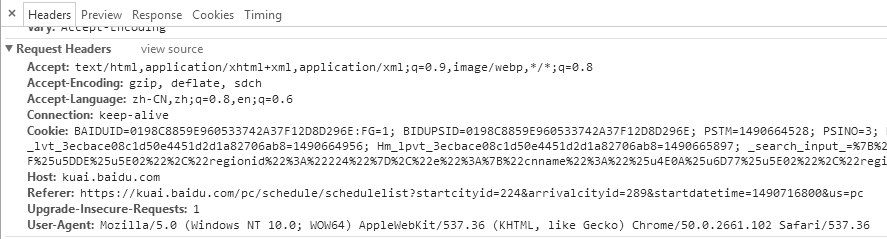
伪装浏览器需要用到的主要就是User-Agent。
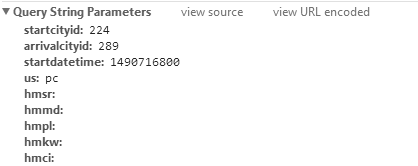
这个是跟在请求链接后面的参数,具体该怎么叫我忘了。
另外,在写代码的时候我还遇到一个麻烦,urlopen(req,data)的data参数显示应该为二进制编码,我直接传入string类型报错。这里有2中方法可以解决:1.string.encode(encoding='utf-8'));2.bytes(string, "utf-8")。
步骤二:使用BeautifulSoup处理数据并存储
# urllib_post_20170327.py
# -*- coding:utf-8 -*-
from urllib.request import urlopen
from urllib.request import Request
from urllib import parse
from bs4 import BeautifulSoup
import json
req = Request("https://kuai.baidu.com/pc/schedule/schedulelist")
# 给请求添加一些Heather头部
req.add_header("Referer","https://kuai.baidu.com/pc")
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36")
def get_one(page=0,schedulelist=[]):
# 初始化时刻表
if page == 0:
schedulelist=[]
# 转换post数据
postData = parse.urlencode([
("startcityid", 224),# 224 苏州
("arrivalcityid", 289),# 289 上海
("startdatetime", 1490630400),# 时间,不知道这个时间网站是怎么计算的
("us", "pc"),
("hmsr", ""),
("hmmd", ""),
("hmpl", ""),
("hmkw", ""),
("hmci", ""),
("page", page)
])
# print(postData)
resp = urlopen(req, data=postData.encode(encoding='utf-8'))#bytes(postData, "utf-8")
# print(resp.read().decode("utf-8"))
# 转换成BeautifulSoup进行处理
bs = BeautifulSoup(resp,"lxml")
if bs.find("ul",{"class":"bus-ls"}) and len(bs.find("ul",{"class":"bus-ls"}).find_all("li",{"class":"clearfix"}))>0:
bs_schedulelist = bs.find("ul",{"class":"bus-ls"}).find_all("li",{"class":"clearfix"})
for item in bs_schedulelist:
schedule = {}
schedule["startTime"] = item.find("p",{"class":"start-time-text"}).get_text()
schedule["startStation"] = item.find("p",{"class":"start-station"}).get_text()
schedule["arriveStation"] = item.find("p",{"class":"arrive-station"}).get_text()
schedule["busLevel"] = item.find("div",{"class":"bus-lv"}).get_text()
schedule["ticketPrice"] = item.find("div",{"class":"ticket-price"}).get_text()
schedulelist.append(schedule)
print(len(schedulelist))
# 递归
get_one(page=page+1, schedulelist=schedulelist)
else:
# 当不满足条件时返回内容,跳出递归
print("获取完成")
print(json.dumps(schedulelist))
return
return json.dumps(schedulelist)
# 直接运行当前文件时执行的内容
if __name__== "__main__":
schedulelist=get_one()
print(schedulelist)
# 文件操作
fs = open("schedulelist.txt", "w")
fs.write(schedulelist)
fs.close()
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
下表列出了主要的解析器,以及它们的优缺点:(这个是从BeautifulSoup官方文档粘过来的)
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") |
|
|
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") |
|
|
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml", "xml"]) BeautifulSoup(markup, "xml") |
|
|
| html5lib | BeautifulSoup(markup, "html5lib") |
|
|
解析器使用pip install进行下载。
我使用的是lxml HTML 解析器,原因简单粗暴,因为我使用BeautifulSoup解析html的时候没有传入解析器对应的参数,报错了之后提示我可以这么用【BeautifulSoup(markup, "lxml")】。
我在处理分页的时候用了递归,其实并不用这么做,循环可能是更好的方式。对于初识递归光环的我,好不容易能找个地方用一下,自然不会错过。递归的时候也出了一点问题,就是我return返回的数据,原本我的return json.dumps(schedulelist)是写在else里面的,结果导致最外层的get_one()没有返回任何数据,经大神提点,改成了代码现在的样子。不过我心里还是觉得自己写的这个递归有点问题,至于哪里有问题,可能还得更深入的学习才知道。
步骤三:使用数据库存储获得的数据
# -*- coding:utf-8 -*-
from urllib.request import urlopen
from urllib.request import Request
from urllib import parse
from bs4 import BeautifulSoup
import json
import pymysql
req = Request("https://kuai.baidu.com/pc/schedule/schedulelist")
# 给请求添加一些Heather头部
req.add_header("Referer","https://kuai.baidu.com/pc")
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36")
def get_one(page=0,schedulelist=[]):
# 初始化时刻表
if page == 0:
schedulelist=[]
# 转换post数据
postData = parse.urlencode([
("startcityid", 224),# 224 上海
("arrivalcityid", 289),# 289 苏州
("startdatetime", 1491062400),
("us", "pc"),
("hmsr", ""),
("hmmd", ""),
("hmpl", ""),
("hmkw", ""),
("hmci", ""),
("page", page)
])
# print(postData)
resp = urlopen(req, data=postData.encode(encoding='utf-8'))#bytes(postData, "utf-8")
# print(resp.read().decode("utf-8"))
# 转换成BeautifulSoup进行处理
bs = BeautifulSoup(resp,"lxml")
if bs.find("ul",{"class":"bus-ls"}) and len(bs.find("ul",{"class":"bus-ls"}).find_all("li",{"class":"clearfix"}))>0:
bs_schedulelist = bs.find("ul",{"class":"bus-ls"}).find_all("li",{"class":"clearfix"})
for item in bs_schedulelist:
schedule = {}
schedule["startTime"] = item.find("p",{"class":"start-time-text"}).get_text()
schedule["startStation"] = item.find("p",{"class":"start-station"}).get_text()
schedule["arriveStation"] = item.find("p",{"class":"arrive-station"}).get_text()
schedule["busLevel"] = item.find("div",{"class":"bus-lv"}).get_text()
schedule["ticketPrice"] = item.find("div",{"class":"ticket-price"}).get_text()
schedulelist.append(schedule)
print(len(schedulelist))
# 递归
get_one(page=page+1, schedulelist=schedulelist)
else:
# 当不满足条件时返回内容,跳出递归
print("获取完成")
return
return schedulelist
class InsertSchedule(object):
def __init__(self, conn):
self.conn = conn
def insert(self,schedulelist):
cursor = self.conn.cursor()
try:
for schedule in schedulelist:
sql = "insert schedule values(\"%s\",\"%s\",\"%s\",\"%s\",\"%s\")"%(schedule.get("startTime",None),schedule.get("startStation",None),schedule.get("arriveStation",None),schedule.get("busLevel",None),schedule.get("ticketPrice",None))
print(sql)
cursor.execute(sql)
except Exception as e:
print(e)
raise e
finally:
cursor.close()
# 直接运行当前文件时执行的内容
if __name__== "__main__":
conn = pymysql.connect(host="localhost",port=3306,user="root",password="qaz123456",db="demo",charset="utf8mb4")
insertSchedule=InsertSchedule(conn)
try:
schedulelist=get_one()
insertSchedule.insert(schedulelist);
conn.commit()
except Exception as e:
conn.rollback()
print("出现问题:"+str(e))
raise e
finally:
conn.close()
我定义了一个InsertSchedule类来进行数据库操作,用到了一些关于事务提交和回滚的概念。实际上我这个简单的demo是不需要这些东西的,可能写在函数里面会更简单明了一些。但是鉴于我最近学习的内容,就直接生搬硬套的拿过来用的,这种用法在很多其他的地方是非常有意思的。
另外,据说用循环插入多条数据是非常损耗数据库性能的事情,可以先获得插入多行的sql语句,再cursor.execute(sql)执行。当然,这样的修改加上拼接字符串让我感觉非常难做,故老老实实做一个笨蛋初学者,将就现在这样用了。
还有一件很重要的事情,操作数据库的数据连接对象connection和游标对象cursor都应该及时关闭,以免浪费资源。
最终结果:
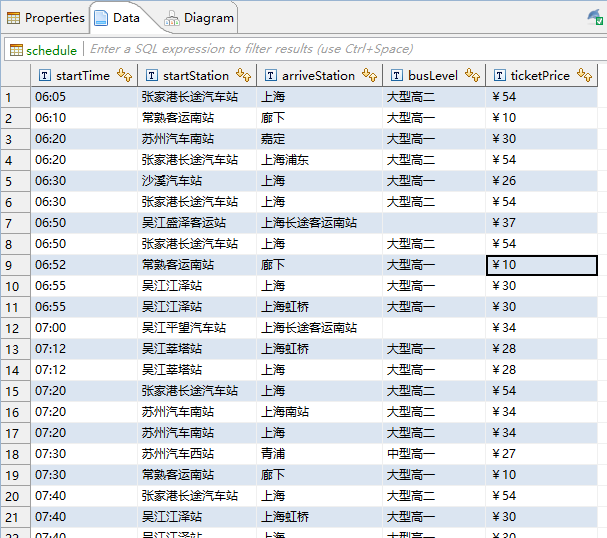
过程十分绵长曲折,但最终结果让人成功满满,清晰的数据呈现在眼前,仿佛打开了一扇新世界的大门。
参考资料:
- http://www.imooc.com/video/12625【使用urllib发送post请求(视频)】
- http://www.ituring.com.cn/book/1709【《Python网络数据采集》】
- https://www.crummy.com/software/BeautifulSoup/bs4/doc/【Beautiful Soup Documentation(有中文版可选择,特别良心)】
- http://www.imooc.com/learn/475【Python操作MySQL数据库(视频)】














 3912
3912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









