








Thien, Nguyen & Kumar, Akshat & Lau, Hoong. (2017). Policy Gradient With Value Function Approximation For Collective Multiagent Planning.
最近一直在忙自己的论文,很久都没有上知乎了。这篇文章的角度很新颖,算法设计跟公式推导都很巧妙,可以借鉴一下。
一、 引言
非中心部分可观马尔可夫决策过程(Dec-POMDP)是一种处理多智能体序列化决策问题的模型,这篇文章针对其中一个子类CDec-POMDP展开研究,CDec-POMDP表示群体的集体行动(collective behavior)会影响联合奖励(joint-reward)和环境动力学。针对CDec-POMDP,文章设计了一种Actor-Critic算法,利用局部奖励信号就能够训练Critic,利用基于数量(在每个状态智能体的数量)方式训练Actor,能够处理大规模多智能体强化学习问题,文章对8000规模的出租车调度问题取得了较好的仿真效果。
Dec-POMDP假设每个智能体根据自身部分可观的局部观测信息来行动,并最大化全局目标值。但是针对大规模的多智能体问题,计算复杂度较高,往往比较难收敛。目前也有很多文献来解决大规模计算复杂的问题,本篇文章从解耦全局奖励和基于数量的方法给出了一种新的AC算法来降低计算复杂度,并且利用神经网络参数化Actor与Critic,采用集中式学习分布式执行的方式。但是这个方法需要一直维护一个计数器,能够实时获取处于各个状态的智能体数量。
二、 CDec-POMDP模型
本节简单介绍一下CDec-POMDP模型,在通常的MDP模型中做了一些变化,更针对性地处理智能体之间的交互问题和大规模数量问题,可以先以一个城市出租车的调度问题来理解模型。最大化一个区域的出租车收益,在每个时刻
T步CDec-POMDP模型如下图所示:
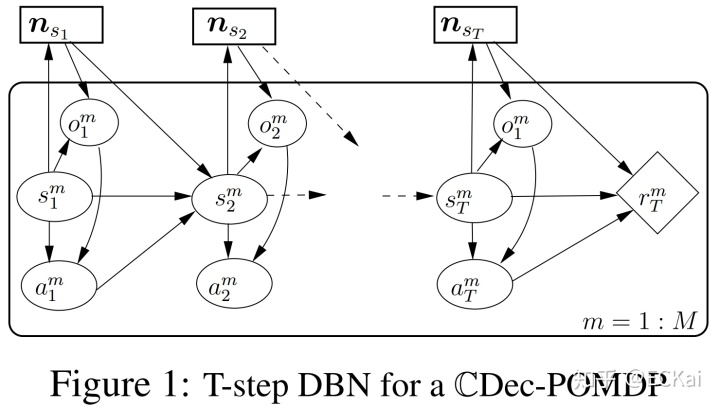
其中智能体总数为M,单个智能体
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 468
468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









