






我们要排序的初始数字集存储在数组中,例如[10, 3, 76, 34, 23, 32],排序后,我们得到一个排序后的数组[3,10,23,32,34,76]
堆排序的工作原理是将数组的元素可视化为一种特殊的完整二叉树,称为堆。
前提条件是,您必须了解完整的二叉树和堆数据结构。
数组索引和树元素之间的关系
完整的二叉树具有一个有趣的属性,我们可以用来查找任何节点的子代和父代。
如果数组中任何元素的索引为 一世,索引中的元素2i+1将成为左子元素,2i+2索引中的元素将成为右子元素。另外,索引处任何元素的父元素由(i-1)/2的下限给出。

数组和堆索引之间的关系
让我们测试一下
1的左孩子(索引0)
= 索引(2 * 0 + 1)中的元素
= 索引1中的元素
= 12
1的右孩子(索引0)
= 索引(2 * 0 + 2)中的元素
= 索引2中的元素
= 9
相似地,
12的左孩子(索引1)
= 索引(2 * 1 + 1)中的元素
= 索引3中的元素
= 5
12的右孩子(索引1)
= 索引(2 * 1 + 2)中的元素
= 索引4中的元素
= 6
我们还要确认规则是否适用于寻找任何节点的父节点
9的父母(索引2)
=(2-1)/ 2
= 1 / 2
= 0.5
〜索引0
= 1
12的父母(索引1)
=(1-1)/ 2
= 索引 0
= 1
了解数组索引到树位置的这种映射对于了解堆数据结构如何工作以及如何用于实现堆排序至关重要。
什么是堆数据结构?
堆是一种特殊的基于树的数据结构。如果满足以下条件,则据说二叉树遵循堆数据结构:
它是一个完整的二叉树
树中的所有节点都遵循其大于子节点的属性,即,最大元素位于根及其子节点,并且小于根,依此类推。这样的堆称为最大堆。相反,如果所有节点都小于其子节点,则称为最小堆
以下示例图显示了最大堆和最小堆。
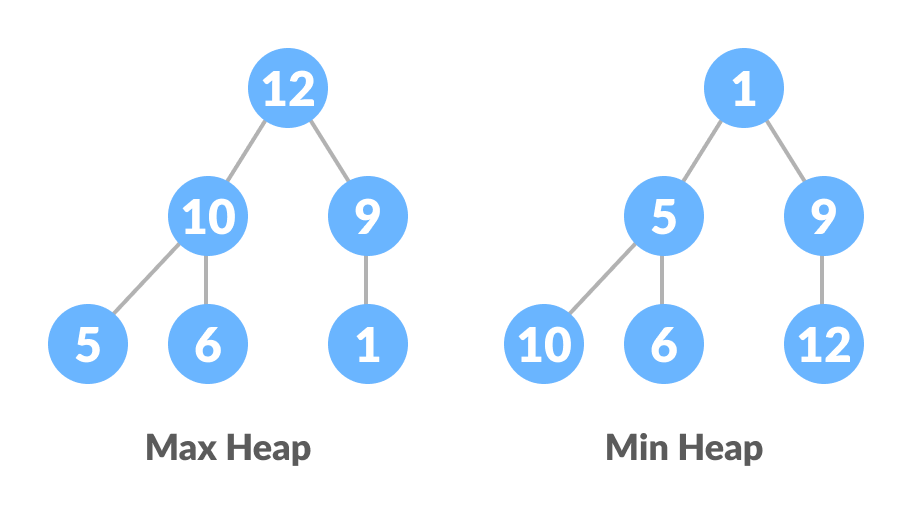
最大堆和最小堆
要了解更多信息,请访问堆数据结构。
如何“堆肥”一棵树
从完整的二叉树开始,我们可以通过在堆的所有非叶元素上运行一个称为heapify的函数,将其修改为最大堆。
由于heapify使用递归,因此可能很难掌握。因此,让我们首先考虑如何只用三个元素堆放一棵树。
heapify(array)
Root = array[0]
Largest = largest( array[0] , array [2*0 + 1]. array[2*0+2])
if(Root != Largest)
Swap(Root, Largest)
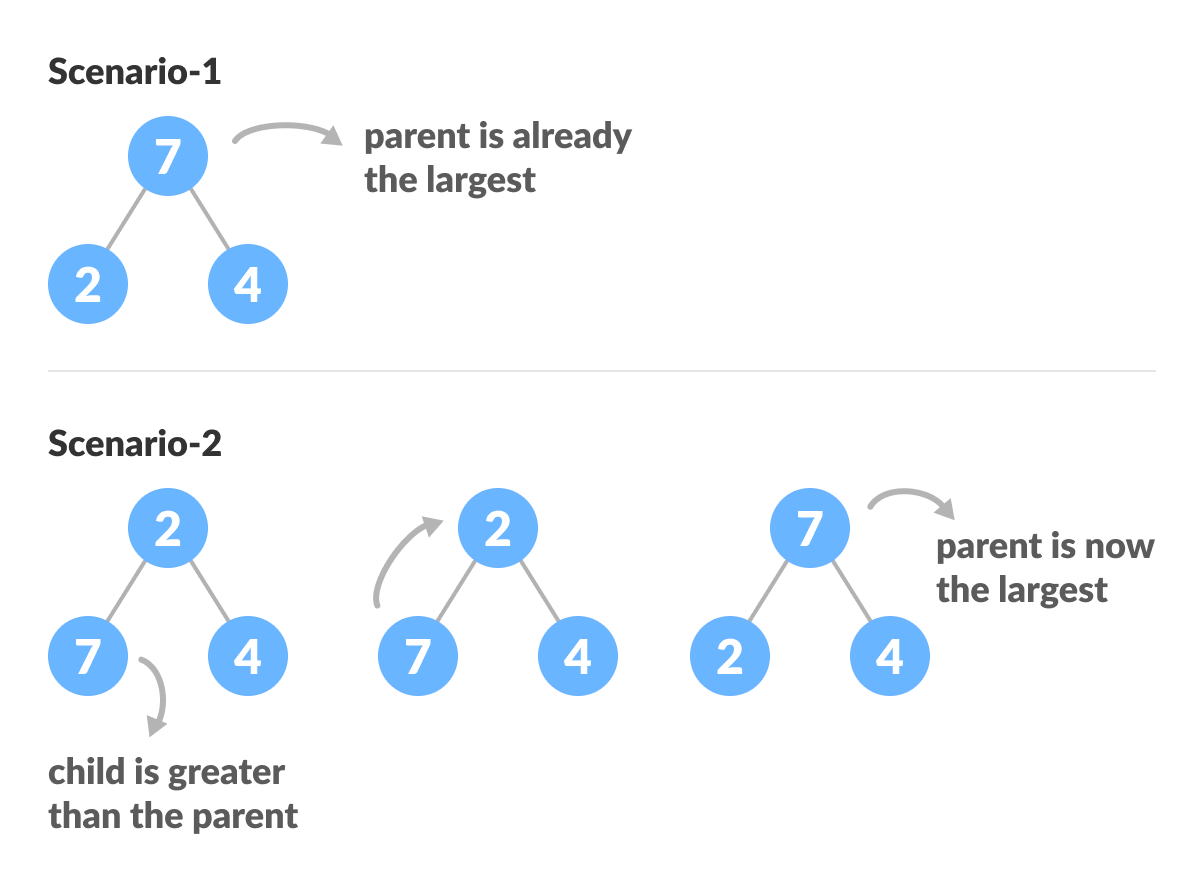
重整基础案例
上面的示例显示了两种情况-一种情况,其中根是最大的元素,而我们无需执行任何操作。另一个根中有一个较大的元素,我们需要交换以维护max-heap属性。
如果您以前使用过递归算法,则可能已经确定这必须是基本情况。
现在让我们考虑另一个场景,其中存在多个级别。

当其子树已经是最大堆时,如何堆置根元素
顶部元素不是最大堆,但是所有子树都是最大堆。
为了维持整个树的max-heap属性,我们将不得不继续向下推2直到它到达正确的位置。
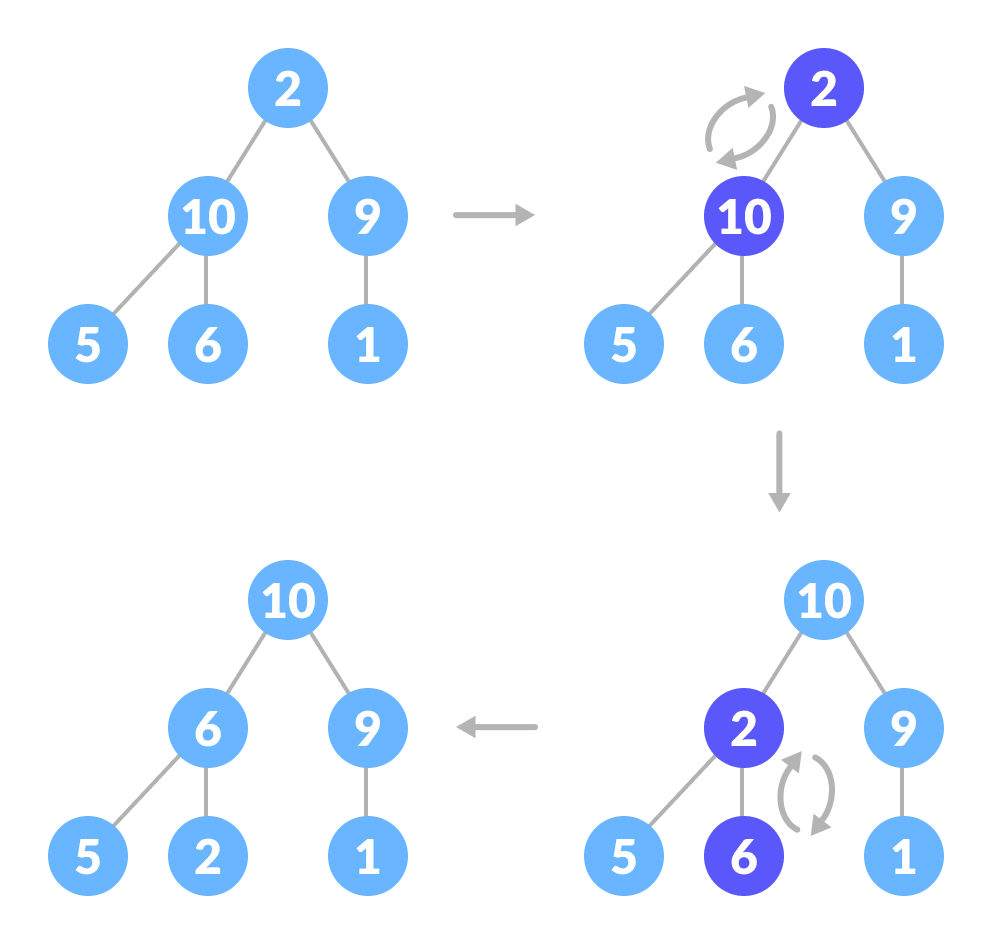
当子树为max-heaps时如何堆放根元素
因此,要在两个子树都是max-heap的树中维护max-heap属性,我们需要在根元素上重复运行heapify,直到它大于其子元素或成为叶节点为止。
我们可以将这两个条件组合在一个heapify函数中
void heapify(int arr[], int n, int i) {
// Find largest among root, left child and right child
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < n && arr[left] > arr[largest])
largest = left;
if (right < n && arr[right] > arr[largest])
largest = right;
// Swap and continue heapifying if root is not largest
if (largest != i) {
swap(&arr[i], &arr[largest]);
heapify(arr, n, largest);
}
}
此功能适用于基本情况和任何大小的树。因此,只要子树是最大堆,我们就可以将根元素移动到正确的位置,以保持任何树大小的最大堆状态。
建立最大堆
要从任何树构建最大堆,我们可以从下至上开始对每个子树进行堆放,并在将函数应用于包括根元素的所有元素后以最大堆结束。
对于完整的树,非叶子节点的第一个索引由给出n/2 - 1。之后的所有其他节点都是叶节点,因此不需要进行堆放。
因此,我们可以建立一个最大堆
// Build heap (rearrange array)
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
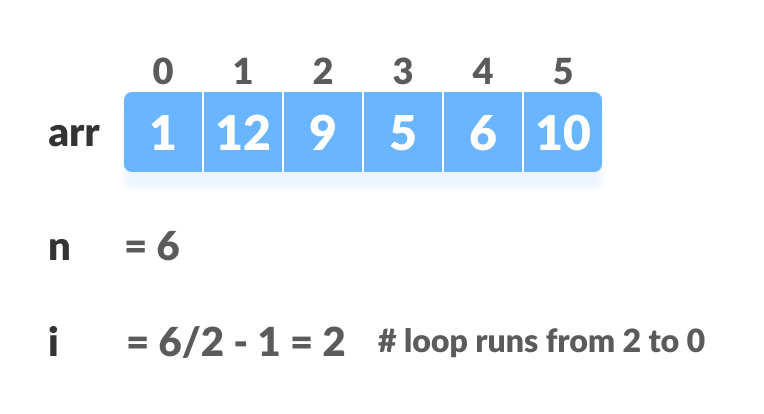
创建数组并计算i
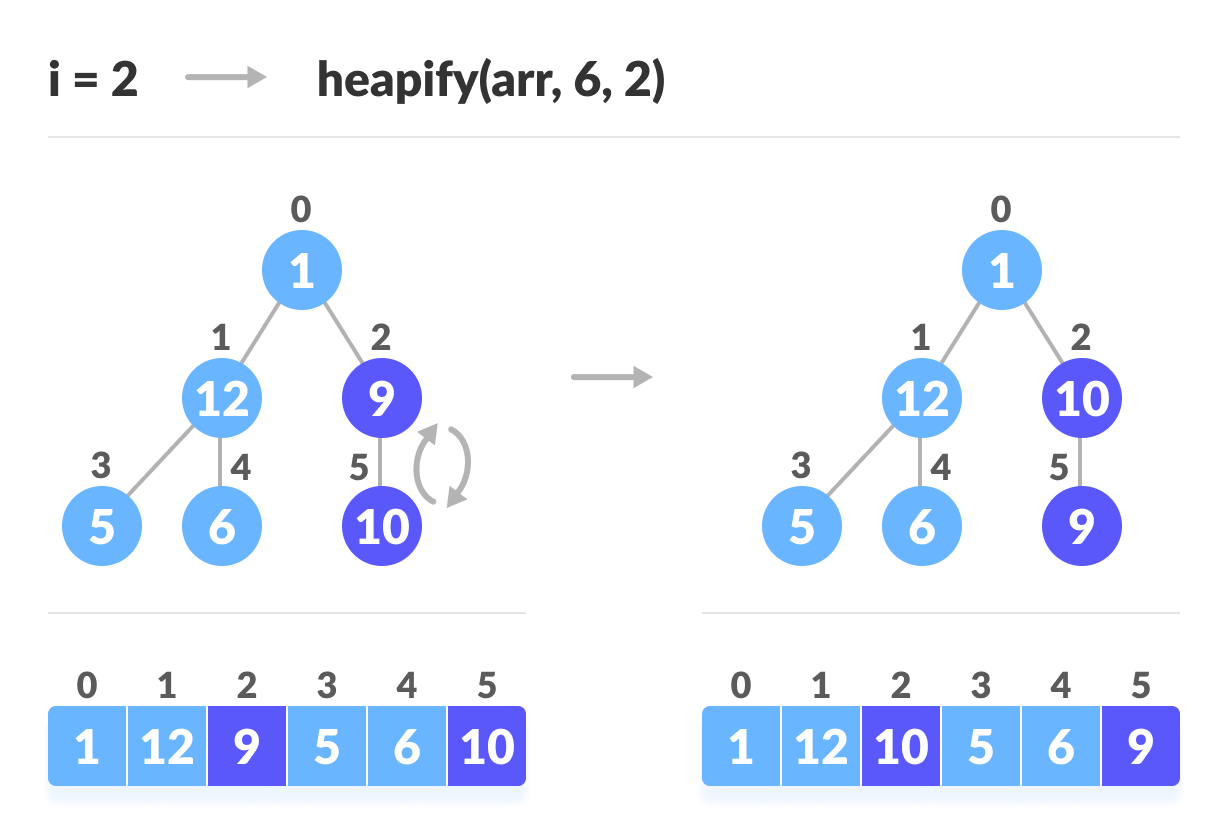
建立用于堆排序的最大堆的步骤
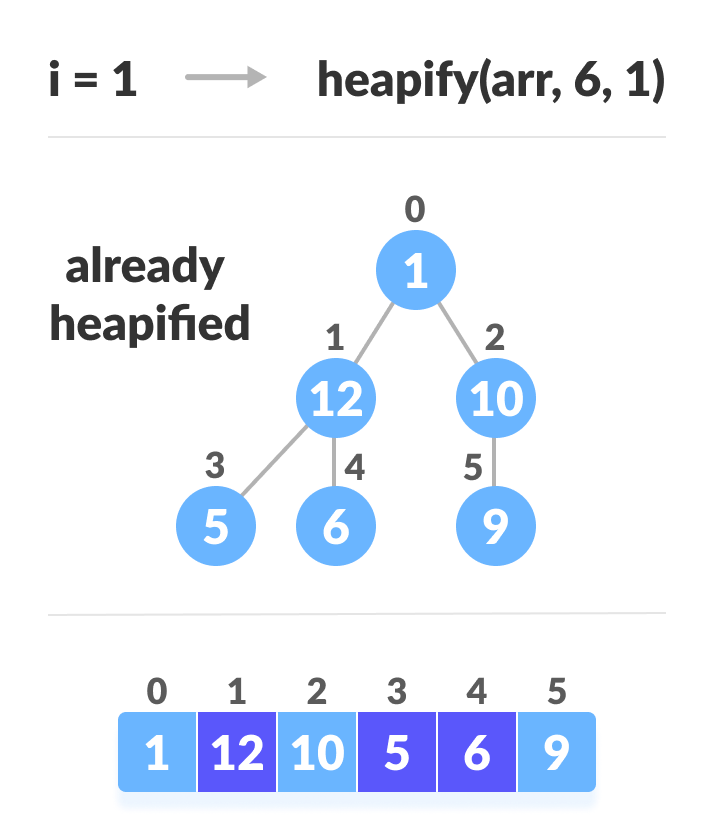
建立用于堆排序的最大堆的步骤
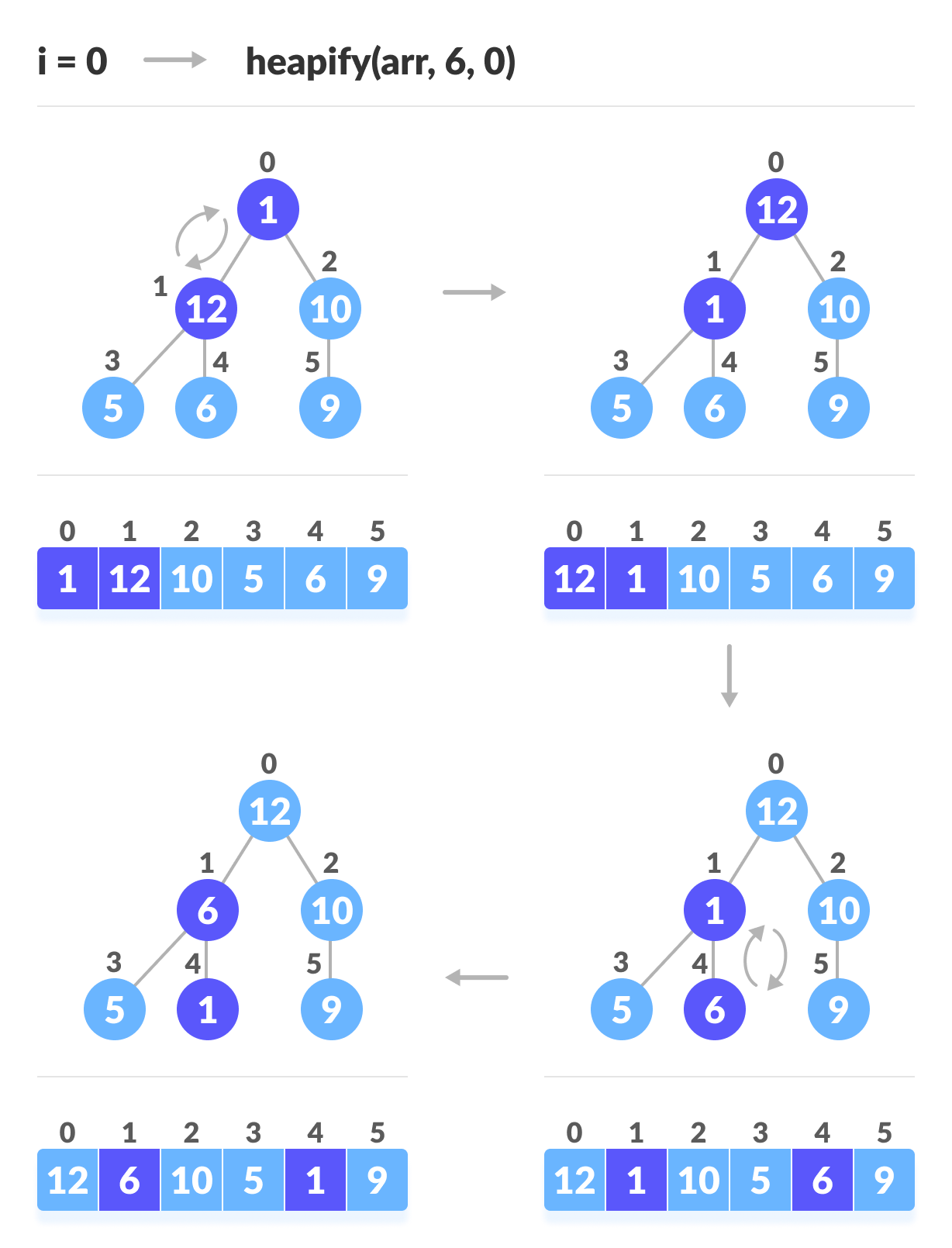
建立用于堆排序的最大堆的步骤
如上图所示,我们首先堆放最小的最小树,然后逐渐向上移动直到到达根元素。
恭喜,如果您到此为止都已经了解了所有内容,那么您就可以掌握堆方法了。
堆排序如何工作?
由于树满足Max-Heap属性,因此最大的项存储在根节点上。
交换:删除根元素,并将其放在数组的末尾(第n个位置)。将树的最后一项(堆)放在空白处。
删除:将堆大小减小1。
堆肥:再次堆肥根元素,以便我们在根上拥有最高的元素。
重复该过程,直到对列表中的所有项目进行排序为止。
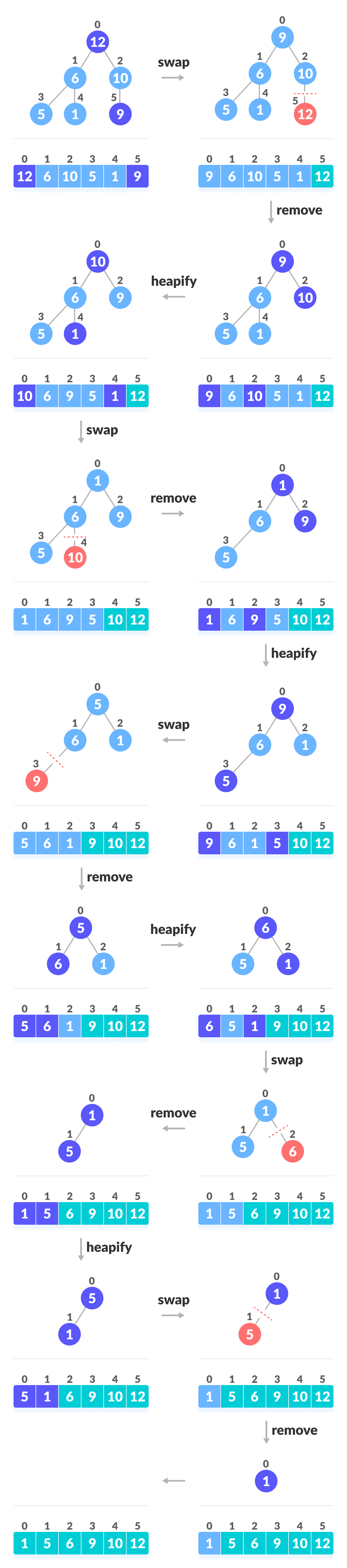
交换,删除和堆化
下面的代码显示了该操作。
// Heap sort
for (int i = n - 1; i >= 0; i--) {
swap(&arr[0], &arr[i]);
// Heapify root element to get highest element at root again
heapify(arr, i, 0);
}
Java示例
// Heap Sort in Java
public class HeapSort {
public void sort(int arr[]) {
int n = arr.length;
// Build max heap
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
// Heap sort
for (int i = n - 1; i >= 0; i--) {
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
// Heapify root element
heapify(arr, i, 0);
}
}
void heapify(int arr[], int n, int i) {
// Find largest among root, left child and right child
int largest = i;
int l = 2 * i + 1;
int r = 2 * i + 2;
if (l < n && arr[l] > arr[largest])
largest = l;
if (r < n && arr[r] > arr[largest])
largest = r;
// Swap and continue heapifying if root is not largest
if (largest != i) {
int swap = arr[i];
arr[i] = arr[largest];
arr[largest] = swap;
heapify(arr, n, largest);
}
}
// Function to print an array
static void printArray(int arr[]) {
int n = arr.length;
for (int i = 0; i < n; ++i)
System.out.print(arr[i] + " ");
System.out.println();
}
// Driver code
public static void main(String args[]) {
int arr[] = { 1, 12, 9, 5, 6, 10 };
HeapSort hs = new HeapSort();
hs.sort(arr);
System.out.println("Sorted array is");
printArray(arr);
}
}
堆排序复杂度
O(nlog n)对于所有情况(最佳情况,平均情况和最坏情况),堆排序都有时间复杂性。
让我们了解原因。包含n个元素的完整二叉树的高度为log n
如我们先前所见,要完全堆放其子树已经是max-heaps的元素,我们需要继续比较该元素及其左,右子元素,并将其向下推,直到其两个子元素均小于其大小。
在最坏的情况下,我们需要将元素从根移动到叶节点,进行多次log(n)比较和交换。
在build_max_heap阶段,我们对n/2元素执行此操作,因此build_heap步骤的最坏情况复杂度为n/2*log n ~ nlog n。
在排序步骤中,我们将根元素与最后一个元素交换并堆放根元素。对于每个元素,这再次花费log n最糟糕的时间,因为我们可能必须将元素从根到叶一直带到一路。因为我们重复这个ñ次,heap_sort步骤也为nlog n。
同样,由于build_max_heap和heap_sort步骤是一个接一个地执行的,因此算法的复杂度不会增加,而是保持在的顺序nlog n。
它还在O(1)空间复杂度上执行排序。与快速排序相比,它具有更好的最坏情况( O(nlog n) )。快速排序O(n^2)在最坏的情况下具有复杂性。但是在其他情况下,快速排序速度很快。Introsort是堆排序的替代方案,它结合了快速排序和堆排序以保留两者的优点:最坏情况下的堆排序速度和平均速度。
堆分类应用
涉及安全性的系统和嵌入式系统(例如Linux Kernel)之所以使用Heap Sort,是因为O(n log n)Heapsort运行时间的O(1)上限以及其辅助存储的上限是恒定的。
尽管堆排序O(n log n)即使在最坏的情况下也具有时间复杂性,但它没有更多的应用程序(与其他排序算法(如快速排序,合并排序)相比)。但是,如果我们要从项目列表中提取最小(或最大)的数据,而无需保持其余项目按排序顺序的开销,则可以有效地使用其基础数据结构堆。例如,优先队列。















 1834
1834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









