







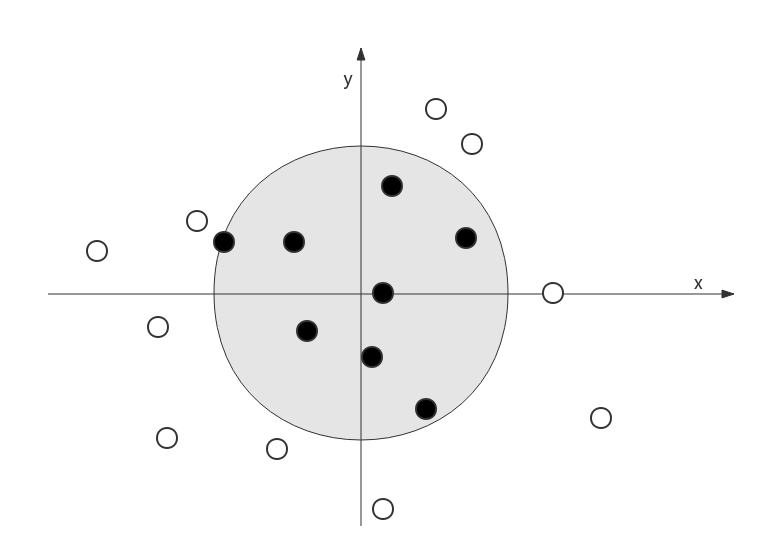
在下面这个图上,找出哪些点在圆内,哪些在圆外,对我们来说非常简单。因为我们有眼睛,能看;有大脑,能想。 但是,如果让电脑来做这件事情,就没那么简单了。我们看一下TensorFlow是如何使用深度神经网络做到的。
介绍
在平面上画一个圆,表达式为x^2+y^2 = 100。 即以原点为中心,半径为100点圆。
在平面上随机生成一批点, 要求 -200<= x <=200, -200<= y <=200。如果点落在圆内(含边界上),则该点的label为0,即图中的实心圆点; 若落在圆外面,则该点label为1,即空心圆点.
要求:通过对数据的分析,生成模型,并对新数据的label进行预测。
步骤
- 生成数据
- 用TensorFlow训练模型
- 预测新数据
1. 生成数据
我用的php代码,大家可以用任何自己喜欢但语言。 文件“generate.php”可以生成2个文件,训练数据training_data.csv和测试数据test_data.csv,代码如下:
<?php
$TRAINING_NUM = 200;//生成训练集坐标点的数量
$TEST_NUM = 100;//生成测试集坐标点的数量
$TRAINING_FILE = "training_data.csv";
$TEST_FILE = "test_data.csv";
generate_data($TRAINING_FILE,$TRAINING_NUM);
generate_data($TEST_FILE,$TEST_NUM);
function generate_data ($file, $num){
unlink($file);
file_put_contents($file,$num.',2,in,out'."\r\n",FILE_APPEND);
$R = 100;
$MIN_X = -200;
$MAX_X = 200;
$MIN_Y = -200;
$MAX_Y = 200;
for ($i=0; $i < $num; $i++) {
$x = rand($MIN_X,$MAX_X);
$y = rand($MIN_Y,$MAX_Y);
$label = 1;
if (($x*$x + $y*$y) <= $R*$R){
$label =0;
}
$line = $x.','.$y.','.$label."\r\n";
file_put_contents($file,$line,FILE_APPEND);
}
}
运行
php generate.php
生成2个文件training_data.csv 和test_date.csv
内容类似下面这样:
200,2,in,out -70,-81,0 -50,-198,0 169,-93,0 51,-78,1 ...
第一行是header。第一行的第一个数字表示文件的总行数(不含header),第二个数字是特征数,本例中有2个特征: x坐标和y坐标。后面2个是label(可忽略)。从第二行开始,每行的三个数字分别是x,y和label。
2. 用TensorFlow训练模型 & 预测新样本
代码circle_dnn_classifier.py 如下:
#coding:utf-8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import numpy as np
# 数据集
TRAINING_FILE = "training_data.csv";
TEST_FILE = "test_data.csv";
# 加载数据
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=TRAINING_FILE,
target_dtype=np.int,
features_dtype=np.int)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=TEST_FILE,
target_dtype=np.int,
features_dtype=np.int)
# 确定所有的特征类型为real-value,特征数量为2
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=2)]
# 创建一个3层的深度神经网络, 分别有 10, 20, 10 个神经元.
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="model")
# 适配模型,训练2000步
classifier.fit(x=training_set.data,y=training_set.target,steps=2000)
# 评估结果
evaluate = classifier.evaluate(x=test_set.data,y=test_set.target)
print(evaluate)
# 对新样本进行预测
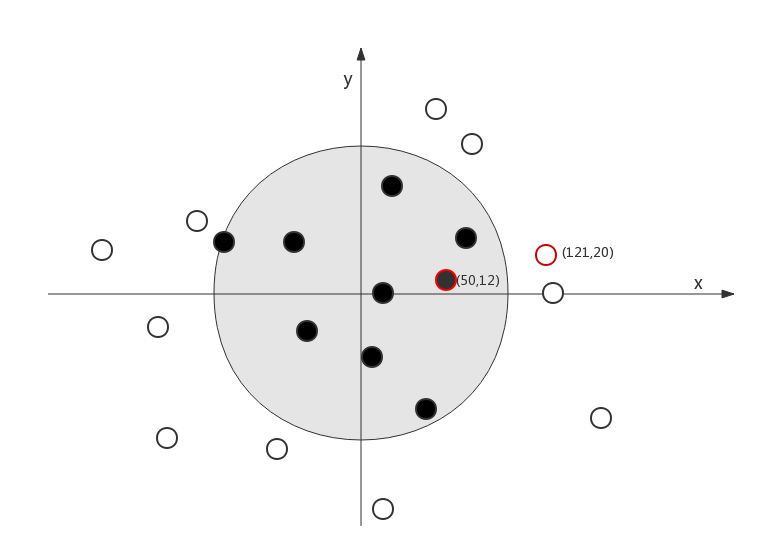
new_samples = np.array([[50, 12], [121, 20]], dtype=int)
y = list(classifier.predict(new_samples, as_iterable=True))
print('Predictions: {}'.format(str(y)))
运行代码:
python circle_dnn_classifier.py
结果
...
{'loss': 0.20674889, 'global_step': 2000, 'accuracy': 0.89999978} //测试数据监测准确率89.99%
...
Predictions: [0, 1] //对新数据预测
可以看到,模型运行正常,准确率是89.99%。
两个新样本在图中的位置,label分别是0和1,TensorFlow识别正确。
可以通过一些简单的办法提高精度:
1.增加训练数据,比如将训练数据增加到5000条(相应地将测试集增加到1000)
2.增加训练次数,比如将step设置为8000
经测试,通过这样的优化,测试结果准确率提高到了99.4%!
大家有兴趣,可以用椭圆或者更加复杂的规则试试,看看TensorFlow训练的效果如何。














 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









