







Lucene 的索引结构是有层次结构的,主要分以下几个层次:
1、索引(index)
- Lucene 索引指的是文件夹下的所有文件
2、段(Segment)
- 一个索引包含了多个段,每个段都是独立的,添加索引时会产生新的段,不同段可以合并
3、文档(Document)
- 文档存储在段中,新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到
同一个段中。
4、域(Field)
- 域指的是文档中的字段,不同域的索引方式可以不同,即不同字段类型
6、词(Trem)
- 词是索引的最小单位,是经过词法分析和语言处理后的字符串。
Lucene 的索引结构中,即保存了正向信息,也保存了反向信息。
按层次保存了从索引,一直到词的包含关系:
- 索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)
包含正向信息的文件有
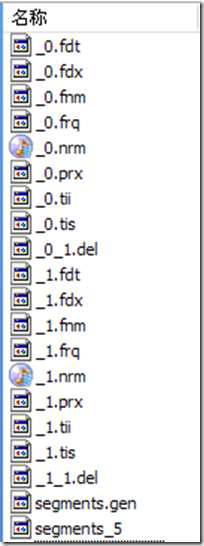
segments_N 保存了此索引包含多少个段,每个段包含多少篇文档。
XXX.fnm 保存了此段包含了多少个域,每个域的名称及索引方式。
XXX.fdx,XXX.fdt 保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
XXX.tvx,XXX.tvd,XXX.tvf 保存了此段包含多少文档,每篇文档包含了多少域,每个域包含了多少词,每个词的字符串,位置等信息。
包含反向信息的文件有
保存了词典到倒排表的映射:词(Term) –> 文档(Document)
包含反向信息的文件有:
XXX.tis,XXX.tii 保存了词典(Term Dictionary),也即此段包含的所有的词按字典顺序的排序。
XXX.frq 保存了倒排表,也即包含每个词的文档ID 列表。
XXX.prx 保存了倒排表中每个词在包含此词的文档中的位置。















 868
868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









