






使用selenium进行翻页获取职位链接,再对链接进行解析
会爬取到部分空列表,感觉是网速太慢了,加了time.sleep()还是会有空列表
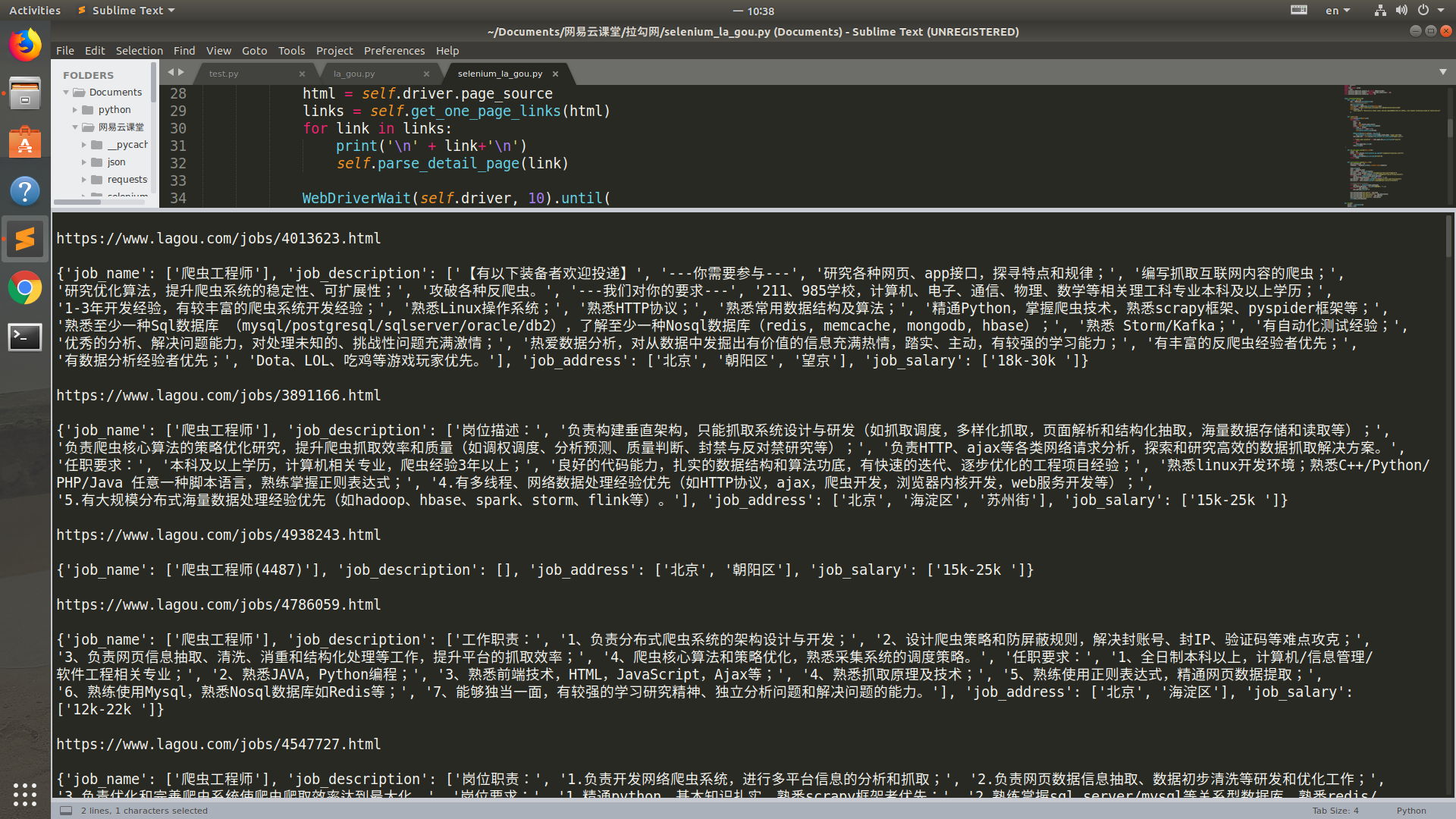
1 from selenium import webdriver 2 import requests 3 import re 4 from lxml import etree 5 import time 6 from selenium.webdriver.support.ui import WebDriverWait 7 from selenium.webdriver.support import expected_conditions as EC 8 from selenium.webdriver.common.by import By 9 10 11 class LagouSpider(object): 12 def __init__(self): 13 opt = webdriver.ChromeOptions() 14 # 把chrome设置成无界面模式 15 opt.set_headless() 16 self.driver = webdriver.Chrome(options=opt) 17 self.url = 'https://www.lagou.com/jobs/list_爬虫?px=default&city=北京' 18 self.headers = { 19 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' 20 } 21 22 23 def run(self): 24 self.driver.get(self.url) 25 while True: 26 html = '' 27 links = [] 28 html = self.driver.page_source 29 links = self.get_one_page_links(html) 30 for link in links: 31 print('\n' + link+'\n') 32 self.parse_detail_page(link) 33 34 WebDriverWait(self.driver, 10).until( 35 EC.presence_of_element_located((By.CLASS_NAME, 'pager_next'))) 36 next_page_btn = self.driver.find_element_by_class_name('pager_next') 37 38 if 'pager_next_disabled' in next_page_btn.get_attribute('class'): 39 break 40 else: 41 next_page_btn.click() 42 time.sleep(1) 43 44 45 def get_one_page_links(self, html): 46 links = [] 47 hrefs = self.driver.find_elements_by_xpath('//a[@class="position_link"]') 48 for href in hrefs: 49 links.append(href.get_attribute('href')) 50 return links 51 52 53 def parse_detail_page(self, url): 54 job_information = {} 55 response = requests.get(url, headers=self.headers) 56 57 time.sleep(2) 58 html = response.text 59 html_element = etree.HTML(html) 60 job_name = html_element.xpath('//div[@class="job-name"]/@title') 61 job_description = html_element.xpath('//dd[@class="job_bt"]//p//text()') 62 for index, i in enumerate(job_description): 63 job_description[index] = re.sub('\xa0', '', i) 64 job_address = html_element.xpath('//div[@class="work_addr"]/a/text()') 65 job_salary = html_element.xpath('//span[@class="salary"]/text()') 66 67 # 字符串处理去掉不必要的信息 68 for index, i in enumerate(job_address): 69 job_address[index] = re.sub('查看地图', '', i) 70 while '' in job_address: 71 job_address.remove('') 72 73 job_information['job_name'] = job_name 74 job_information['job_description'] = job_description 75 job_information['job_address'] = job_address 76 job_information['job_salary'] = job_salary 77 print(job_information) 78 79 80 def main(): 81 spider = LagouSpider() 82 spider.run() 83 84 85 if __name__ == '__main__': 86 main()
运行结果















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









