







- kafka:一个消息队列,保证了消息的顺序,严格遵循FIFO原则,其实kafka只是在局部保 证了消息的顺序性,后续会讲解。
- 名词:
broken:一台安装了kafka的服务器就是一个broken;
topic:消息的主题,同一类的消息定义为一个主题;
partition:分区,一个topic下有一个或多个分区;
segment:partition的最小单位,segment文件由两部分组成,分
别为“.index”文件和“.log”文件,分别表示为segment索
引文件和数据文件。
- 关系图
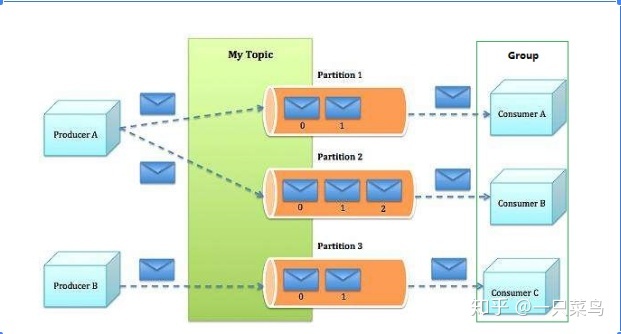
生产者往kafka中发送消息,定义消息的topic,如果不指定partition,消息会采用默认的负载均衡策略分发到不同的partition中,kafka只保证了每个partiton中的消息是有序的,不保证整体topic消息有序,这也就是之前所说的局部有序。消费者从kafka中拉取数据进行消费,注意这里是拉取而不是kafka去推送消息,这样设计的好处就在消费端可以根据自身的消费能力去消费数据,消费时指定消费主题topic和消费群组,也可以指定partition进行消费,不指定的话默认全部消费。
在Kafka文件存储中,同一个topic下有多个不同的partition,每个partiton为一个目录,partition的名称规则为:topic名称+有序序号,第一个序号从0开始计,最大的序号为partition数量减1,partition是实际物理上的概念,而topic是逻辑上的概念。
上面提到partition还可以细分为segment,这个segment又是什么?如果就以partition为最小存储单位,我们可以想象当Kafka producer不断发送消息,必然会引起partition文件的无限扩张,这样对于消息文件的维护以及已经被消费的消息的清理带来严重的影响,所以这里以segment为单位又将partition细分。每个partition(目录)相当于一个巨型文件被平均分配到多个大小相等的segment(段)数据文件中(每个segment 文件中消息数量不一定相等)这种特性也方便old segment的删除,即方便已被消费的消息的清理,提高磁盘的利用率。每个partition只需要支持顺序读写就行,segment的文件生命周期由服务端配置参数(log.segment.bytes,log.roll.{ms,hours}等若干参数)决定。
segment文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为segment索引文件和数据文件。这两个文件的命令规则为:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充,如下:
- 00000000000000000000.index
- 00000000000000000000.log
- 00000000000000170410.index
- 00000000000000170410.log
- 00000000000000239430.index
- 00000000000000239430.log
- 实践
搭建kafka环境请看上一篇总结《kafka环境搭建》
一只菜鸟:kafka环境搭建zhuanlan.zhihu.com 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









