







所有的省时间优化,主要是讲Hadoop采用的数据本地优化,避免浪费宝贵的网络带宽,但是有时候对于一个Map任务输入来说,储存有某个HDFS数据块备份的三个节点可能正在运行其他map任务,此时作业调度,也就是所谓的JobTracker需在三个备份中的某个数据寻求同个机架中的空闲机器来运行该map任务。
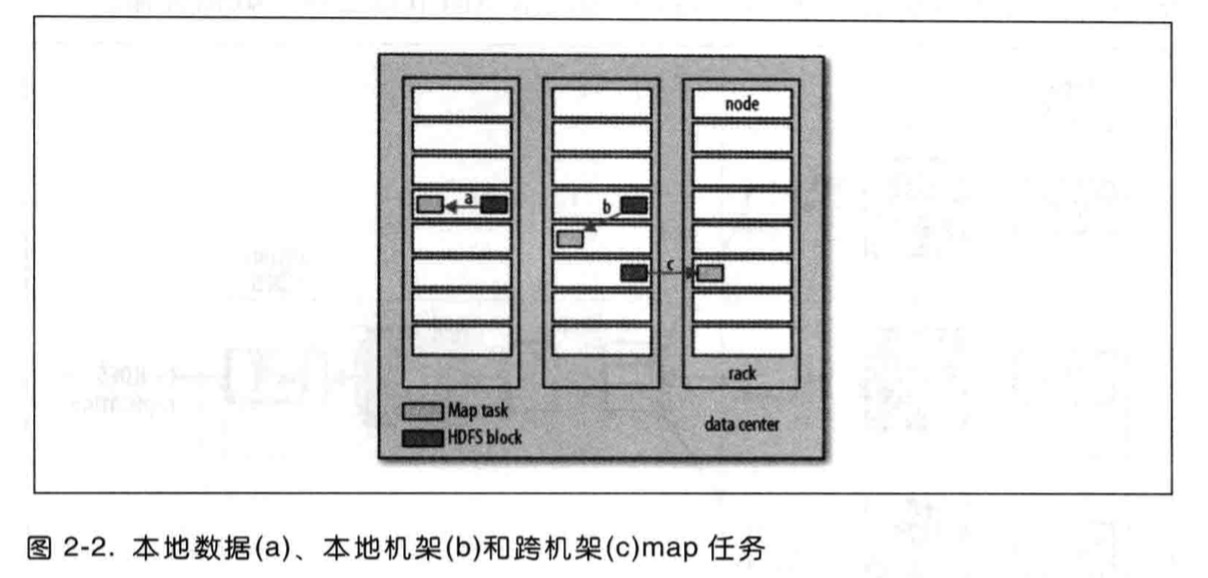
所以我们应该清楚了为什么最佳分片大小应该与块大小相同:因为这种机制可以确保可以储存在单个节点上的最大输入块的大小。换句话说加重的字体是我们的目标。如果分片跨越两个数据块,那么对于任何一个HDFS节点,基本上都不可能同时储存这两个数据块,因此分片中的部分数据需要通过网络传输到map任务节点,与使用本地数据运行整个map任务相比,这种方法显然效率更低。
此外,应该注意map任务应该将结果存入本地硬盘,而不是HDFS系统。因为它产生的只是中间结果。















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









