







一、软件准备
1. jdk-7u80-linux-x64.tar.gz2. hadoop-2.6.4.tar.gz
3. ssh客户端(必须安装 ssh 且必须运行 sshd 以便使用 Hadoop 脚本来管理远程的 Hadoop 守护进程, Mac自带有 ssh 客户端)
二、JDK安装配置
1. 下载解压 jdk-7u80-linux-x64.tar.gz。2. 配置环境变量, 编辑 .bash_profile 文件,在文件末尾添加以下内容:
# Java Env
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.7.0_80.jdk/Contents/Home
export JRE_HOME=/Library/Java/JavaVirtualMachines/jdk1.7.0_80.jdk/Contents/Home/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib4. 输入 java -version 可以看到成功安装的JDK版本信息。

三、Hadoop安装配置
2. 修改 .bash_profile 文件配置 Hadoop 环境变量,在文件末尾添加以下内容:
# Hadoop Env
export HADOOP_HOME=/Users/jackiehff/Software/hadoop-2.6.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin保存后,运行 source .bash_profile, 使 Hadoop 环境变量立即生效。
3. 修改 Hadoop 环境变量配置文件 etc/hadoop/hadoop-env.sh,在文件末尾添加以下内容:
# The java implementation to use.
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.7.0_80.jdk/Contents/Home
export HADOOP_PREFIX=/Users/jackiehff/Software/hadoop-2.6.4 
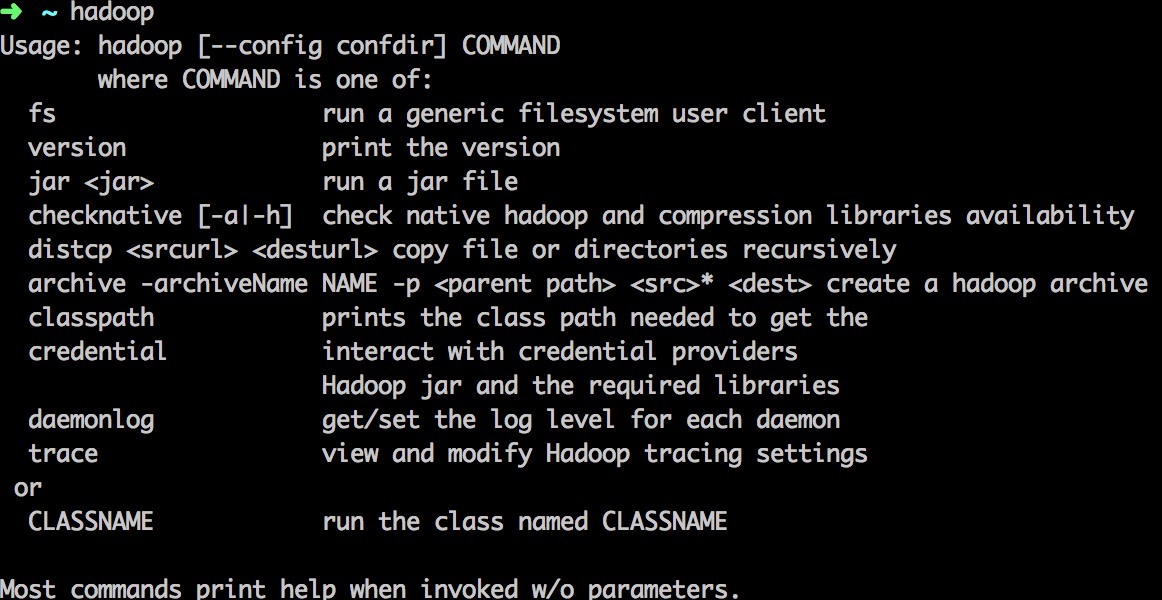
5. 输入 hadoop 可以看到 hadoop 命令使用方法。
四、单机模式操作
Hadoop默认配置运行于非分布式模式中,即作为单个的 Java 进程运行,这样调试起来会很方便。下面运行一下自带的 WordCount 程序。
mkdir input
cp etc/hadoop/*.xml input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output
'dfs[a-z.]+'运行过程大致如下:

查看运行结果
cat outut/* 
五、伪分布式模式操作
1、配置ssh
因为伪分布模式下,即使所有节点都在一台机器上,Hadoop 也需要通过 ssh 登录,这一步的目的是配置本机无密码 ssh 登录。
验证是否可以不需要密码 ssh 到 localhost。
ssh localhost如果不行,执行如下命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 
2、修改Hadoop配置文件
伪分布式模式主要涉及以下配置信息:
(1) 修改 Hadoop 的核心配置文件 core-site.xml, 主要是配置 HDFS 的地址和端口号。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/jackiehff/Software/hadoop-2.6.4/tmp</value>
</property>
</configuration>(2) 修改 Hadoop 中 HDFS 的配置文件 hdfs-site.xml, 主要是配置数据副本。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>(3) 修改 Hadoop 中 MapReduce 配置文件 mapred-site.xml, 主要是配置 MapReduce 框架名称。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(4) 修改 Hadoop 中 YARN 的配置文件 yarn-site.xml,主要用于指定 shuffle server。
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>3 、执行
(1) 格式化文件系统
hdfs namenode -formatstart-dfs.sh输出结果如下:
16/04/11 21:38:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /Users/jackiehff/Software/hadoop-2.6.4/logs/hadoop-jackiehff-namenode-jackiehff.local.out
localhost: starting datanode, logging to /Users/jackiehff/Software/hadoop-2.6.4/logs/hadoop-jackiehff-datanode-jackiehff.local.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /Users/jackiehff/Software/hadoop-2.6.4/logs/hadoop-jackiehff-secondarynamenode-jackiehff.local.out
16/04/11 21:39:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 
可以看到 HDFS 启动成功。
(3) 浏览器访问 NameNode ,地址: http://localhost:50070/。

(4) 启动 ResourceManager 和 NodeManager 进程
start-yarn.shstarting yarn daemons
starting resourcemanager, logging to /Users/jackiehff/Software/hadoop-2.6.4/logs/yarn-jackiehff-resourcemanager-jackiehff.local.out
localhost: starting nodemanager, logging to /Users/jackiehff/Software/hadoop-2.6.4/logs/yarn-jackiehff-nodemanager-jackiehff.local.out 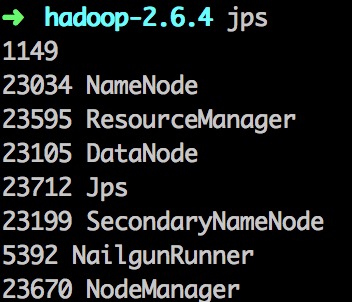
可以看到 NodeManager 和 ResourceManager 启动成功。
(5) 浏览器访问 ResourceManager, 地址: http://localhost:8088/。

(6) 创建执行MapReduce 任务所需的HDFS 目录。
hdfs dfs -mkdir /inputhdfs dfs -put etc/hadoop/* /inputhadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep /input output dfs'[a-z.]+'hdfs dfs -cat output/* 
可以在浏览器中查看相关 Job。

(9) 停止 HDFS。
stop-dfs.shstop-yarn.sh














 173
173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









