







# ifndef _LIBSVM_H
#define _LIBSVM_H
#define LIBSVM_VERSION 320
#ifdef __cplusplus
extern "C" {//支持c与c++混合编程
#endif
extern int libsvm_version;
struct svm_node //存储单个特征向量
{
int index; //特征的维数
double value; //特征的数值
};
struct svm_problem //存储本次参加运算的参数
{
int all ; //数据的总数
double *p; //指向数据分类类别的指针
svm_node **x; //指向存储内容为指针的指针
};
enum { C_SVC, NU_SVC, ONE_CLASS, EPSILON_SVR, NU_SVR }; //定义枚举类型表示选用SVM的类别
enum { LINEAR, POLY, RBF, SIGMOID, PRECOMPUTED }; //定义枚举类型表示所选取的核函数类型
struct svm_parameter
{
int svm_type;//定义svm分类类型
int kernel_type;//定义核函数类型
int degree;//核函数的指数
double gamma;
double coef0;
/* training parameter*/
double cache_size;//训练所需的内存
double eps;
double C;//惩罚因子
int nr_weight;//
int *weight_lable;//权重的数目
double* weight;//权重
double nu;
double p;
int shrinking;//是否压缩
int probability;//是否做概率估计
}
//svm_model
struct svm_model
{
struct svm_parameter param;//训练参数
int nr_class;//类别数
int l;//支持向量数
struct svm_node **SV; /*保存支持向量的指针,至于支持向量的内容,如果是从文件中读取,内容会
额外保留;如果是直接训练得来,则保留在原来的训练集中。如果训练完成后需要预报,原来的
训练集内存不可以释放。*/
double *rho;//判别函数的alpha
double *probA;
double *probB;
int *sv_indices;
//classification use
int *lable;
int *nSV;
int free_sv;
};
struct svm_model *svm_train(const struct svm_self *prob,const svm_parameter *param);//定义svm训练函数
void svm_cross_validation(const struct svm_problem *prob, const struct svm_parameter *param, int nr_fold, double *target);//交差验证函数
int svm_save_model(const char *model_file_name, const struct svm_model *model);//保存训练好的数据函数
struct svm_model *svm_load_model(const char *model_file_name);//将训练好的模型读取到内存中
int svm_get_svm_type(const struct svm_model *model);//得到svm类型的函数
int svm_get_nr_class(const struct svm_model *model);//得到数据的类别数函数
void svm_get_labels(const struct svm_model *model, int *label);//得到数据的类别标号
void svm_get_sv_indices(const struct svm_model *model, int *sv_indices);
int svm_get_nr_sv(const struct svm_model *model);
double svm_get_svr_probability(const struct svm_model *model);
double svm_predict_values(const struct svm_model *model, const struct svm_node *x, double* dec_values);//用训练好的模型预测数据类别,并保存到数组
double svm_predict(const struct svm_model *model, const struct svm_node *x);//预测某一样本的函数
double svm_predict_probability(const struct svm_model *model, const struct svm_node *x, double* prob_estimates);
void svm_free_model_content(struct svm_model *model_ptr);//清除训练模型,释放资源
void svm_free_and_destroy_model(struct svm_model **model_ptr_ptr);
void svm_destroy_param(struct svm_parameter *param);
const char *svm_check_parameter(const struct svm_problem *prob, const struct svm_parameter *param);
int svm_check_probability_model(const struct svm_model *model);
void svm_set_print_string_function(void (*print_func)(const char *));
#ifdef __cplusplus
}
#endif
#endif /* _LIBSVM_H */
现在开始看一看libsvm的头文件svm.h
svm.h中主要是定义了4个结构体,分别是svm_node、svm_problem、svm_parameter、svm_model,然后就是19个函数的声明,函数的声明我就不先讲了,等到在svm.cpp中碰到后再细说。下面来看一看这几个结构体:
struct svm_node { int index; double value; };
这个结构体用于存储单一向量中的单个特征。例如:向量x1={0.002,0.345,4.000,5.677},则用svm_node来存储就是使用一个包含5个svm_node的数组来存储这个4维向量,内存中的表示如下:

struct svm_problem { int l; //记录样本总数 double *y;//指向样本所属类别的数组 struct svm_node **x;//指向一个存储内容为指针的数组 };
这个结构体用于存储本次参加运算的所有样本及其所属类别,一个示意图如下(其中最右边的4个长方格如同上图中的表格):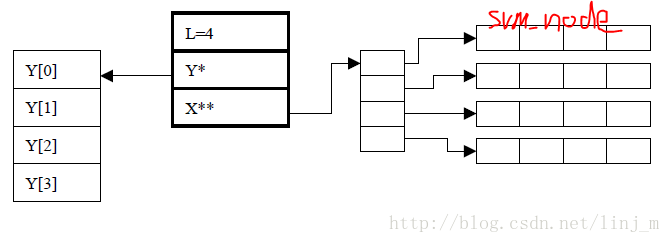
struct svm_parameter
{
int svm_type;//定义svm分类类型
int kernel_type;//定义核函数类型
int degree;//核函数的指数
double gamma;
double coef0;
/* training parameter*/
double cache_size;//训练所需的内存
double eps;
double C;//惩罚因子
int nr_weight;//
int *weight_lable;//权重的数目
double* weight;//权重
double nu;
double p;
int shrinking;//是否压缩
int probability;//是否做概率估计
}这个结构体用于存储svm的各个参数,知道就行。
struct svm_model
{
struct svm_parameter param;//训练参数
int nr_class;//类别数
int l;//支持向量数
struct svm_node **SV; /*保存支持向量的指针,至于支持向量的内容,如果是从文件中读取,内容会
额外保留;如果是直接训练得来,则保留在原来的训练集中。如果训练完成后需要预报,原来的
训练集内存不可以释放。*/
double *rho;//判别函数的alpha
double *probA;
double *probB;
int *sv_indices;
//classification use
int *lable;
int *nSV;
int free_sv;
};
这个函数体用于保存训练后的训练模型model,在predict中要用到。
=======================================
关于extern “C”的解析
在阅读svm.h时发现了如下一段代码:
#ifndef _LIBSVM_H #define _LIBSVM_H #define LIBSVM_VERSION 317 #ifdef __cplusplus extern "C" { #endif
显然,前3行代码是为了防止头文件被重复引用,那么5-6行是什么意思呢?
某企业曾经给出如下的一道面试题:为什么标准头文件都有类似以下的结构?
#ifndef __INCvxWorksh #define __INCvxWorksh #ifdef __cplusplus extern "C" { #endif /*...*/ #ifdef __cplusplus } #endif #endif /* __INCvxWorksh */
分析
显然,头文件中的编译宏“#ifndef __INCvxWorksh、#define __INCvxWorksh、#endif” 的作用是防止该头文件被重复引用。
那么
#ifdef __cplusplus extern "C" { #endif #ifdef __cplusplus } #endif
的作用又是什么呢?
extern "C" 包含双重含义,从字面上即可得到:首先,被它修饰的目标是“extern”的;其次,被它修饰的目标是“C”的。让我们来详细解读这两重含义。
被extern "C"限定的函数或变量是extern类型的;extern是C/C++语言中表明函数和全局变量作用范围(可见性)的关键字,该关键字告诉编译器,其声明的函数和变量可以在本模块或其它模块中使用。记住,下列语句:extern int a;仅仅是一个变量的声明,其并不是在定义变量a,并未为a分配内存空间。变量a在所有模块中作为一种全局变量只能被定义一次,否则会出现连接错误。通常,在模块的头文件中对本模块提供给其它模块引用的函数和全局变量以关键字extern声明。例如,如果模块B欲引用该模块A中定义的全局变量和函数时只需包含模块A的头文件即可。这样,模块B中调用模块A中的函数时,在编译阶段,模块B虽然找不到该函数,但是并不会报错;它会在连接阶段中从模块A编译生成的目标代码中找到此函数。
与extern对应的关键字是static,被它修饰的全局变量和函数只能在本模块中使用。因此,一个函数或变量只可能被本模块使用时,其不可能被extern “C”修饰。
被extern "C"修饰的变量和函数是按照C语言方式编译和连接的;
未加extern “C”声明时的编译方式
首先看看C++中对类似C的函数是怎样编译的。作为一种面向对象的语言,C++支持函数重载,而过程式语言C则不支持。函数被C++编译后在符号库中的名字与C语言的不同。例如,假设某个函数的原型为:
- void foo( int x, int y );
该函数被C编译器编译后在符号库中的名字为_foo,而C++编译器则会产生像_foo_int_int之类的名字(不同的编译器可能生成的名字不同,但是都采用了相同的机制,生成的新名字称为“mangled name”)。_foo_int_int这样的名字包含了函数名、函数参数数量及类型信息,C++就是靠这种机制来实现函数重载的。例如,在C++中,函数void foo( int x, int y )与void foo( int x, float y )编译生成的符号是不相同的,后者为_foo_int_float。同样地,C++中的变量除支持局部变量外,还支持类成员变量和全局变量。用户所编写程序的类成员变量可能与全局变量同名,我们以"."来区分。而本质上,编译器在进行编译时,与函数的处理相似,也为类中的变量取了一个独一无二的名字,这个名字与用户程序中同名的全局变量名字不同。
未加extern "C"声明时的连接方式
假设在C++中,模块A的头文件如下:
// 模块A头文件 moduleA.h #ifndef MODULE_A_H #define MODULE_A_H int foo( int x, int y ); #endif
在模块B中引用该函数:
// 模块B实现文件 moduleB.cpp #include "moduleA.h" foo(2,3);
实际上,在连接阶段,连接器会从模块A生成的目标文件moduleA.obj中寻找_foo_int_int这样的符号!
加extern "C"声明后的编译和连接方式
加extern "C"声明后,模块A的头文件变为:
// 模块A头文件 moduleA.h #ifndef MODULE_A_H #define MODULE_A_H extern "C" int foo( int x, int y ); #endif
在模块B的实现文件中仍然调用foo( 2,3 ),其结果是:
(1)模块A编译生成foo的目标代码时,没有对其名字进行特殊处理,采用了C语言的方式;
(2)连接器在为模块B的目标代码寻找foo(2,3)调用时,寻找的是未经修改的符号名_foo。
所以,可以用一句话概括extern “C”这个声明的真实目的:实现C++与C及其它语言的混合编程。
extern "C"的惯用法
(1)在C++中引用C语言中的函数和变量,在包含C语言头文件(假设为cExample.h)时,需进行下列处理:
extern "C" { #include "cExample.h" }
而在C语言的头文件中,对其外部函数只能指定为extern类型,C语言中不支持extern "C"声明,在.c文件中包含了extern "C"时会出现编译语法错误。笔者编写的C++引用C函数例子工程中包含的三个文件的源代码如下:
/* c语言头文件:cExample.h */ #ifndef C_EXAMPLE_H #define C_EXAMPLE_H extern int add(int x,int y); #endif /* c语言实现文件:cExample.c */ #include "cExample.h" int add( int x, int y ) { return x + y; } // c++实现文件,调用add:cppFile.cpp extern "C" { #include "cExample.h" } int main(int argc, char* argv[]) { add(2,3); return 0; }
如果C++调用一个C语言编写的.DLL时,当包括.DLL的头文件或声明接口函数时,应加extern "C" { }。
(2)在C中引用C++语言中的函数和变量时,C++的头文件需添加extern "C",但是在C语言中不能直接引用声明了extern "C"的该头文件,应该仅将C文件中将C++中定义的extern "C"函数声明为extern类型。
笔者编写的C引用C++函数例子工程中包含的三个文件的源代码如下:
//C++头文件 cppExample.h #ifndef CPP_EXAMPLE_H #define CPP_EXAMPLE_H extern "C" int add( int x, int y ); #endif //C++实现文件 cppExample.cpp #include "cppExample.h" int add( int x, int y ) { return x + y; } /* C实现文件 cFile.c /* 这样会编译出错:#include "cExample.h" */ extern int add( int x, int y ); int main( int argc, char* argv[] ) { add( 2, 3 ); return 0; }
上面关于extern C的解析转载自:C++中extern “C”含义深层探索
其他关于extern C 的知识可参见博文:
- #ifndef _HELLO_H_
- #define _HELLO_H_
- #ifdef __cplusplus
- #define extern "C" {
- #endif
- //Your code
- #ifdef __cplusplus
- #define }
- #endif
- #endif /*_HELLO_H*/
- 外层的“#ifndef _HELLO_H_”是为了防止本文件被重复include。
- 内层的“#ifdef __cplusplus”是为了解决c 和c的名字匹配问题。
C 支持函数重载,c语言不支持函数重载。函数被c 编译后在库里面的名字与c语言不同。
假设某个函数的原型为:
void foo( int x, int y );
该函数被C编译器编译后在符号库中的名字为_foo,而C 编译器则会产生像_foo_int_int之类的名字(不同的编译器可能生成的名字不同,但是都采用了相同的机制,生成的新名字称为“mangled name”)。
_foo_int_int这样的名字包含了函数名、函数参数数量及类型信息,C 就是靠这种机制来实现函数重载的。















 5539
5539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









