






这是一个山科大的同学给我的一个问题,向我询问一下思路,对于数学建模,我没太多的了解,所以只能用计算机程序的方法来解答。
这是具体的问题:
这个问题来自 DNA序列的k-mer index问题。
给定一个DNA序列,这个系列只含有4个字母ATCG,如 S =“CTGTACTGTAT”。给定一个整数值k,从S的第一个位置开始,取一连续k个字母的短串,称之为k-mer(如k= 5,则此短串为CTGTA), 然后从S的第二个位置, 取另一k-mer(如k= 5,则此短串为TGTAC),这样直至S的末端,就得一个集合,包含全部k-mer 。 如对序列S来说,所有5-mer为
{CTGTA,TGTAC,GTACT,TACTG,ACTGT,CTGTA,TGTAT}
通常这些k-mer需一种数据索引方法,可被后面的操作快速访问。例如,对5-mer来说,当查询CTGTA,通过这种数据索引方法,可返回其在DNA序列S中的位置为{1,6}。
问题
现在以文件形式给定 100万个 DNA序列,序列编号为1-1000000,每个基因序列长度为100 。
(1)要求对给定k, 给出并实现一种数据索引方法,可返回任意一个k-mer所在的DNA序列编号和相应序列中出现的位置。每次建立索引,只需支持一个k值即可,不需要支持全部k值。
(2)要求索引一旦建立,查询速度尽量快,所用内存尽量小。
(3)给出建立索引所用的计算复杂度,和空间复杂度分析。
(4)给出使用索引查询的计算复杂度,和空间复杂度分析。
(5)假设内存限制为8G,分析所设计索引方法所能支持的最大k值和相应数据查询效率。
(6)按重要性由高到低排列,将依据以下几点,来评价索引方法性能
· 索引查询速度
· 索引内存使用
· 8G内存下,所能支持的k值范围
· 建立索引时间
要想做出来一个索引,就必须知道子序列的位置,要求对子序列编号。
其实还有两个70多M的文档,以.fa结尾,
经过百度查了一下,fa的文件是一个数据文件。全名是:FASTA Formatted Sequence File。
它属于生物信息学中数据文件格式,是一种基于文本用于表示核苷酸序列或氨基酸序列的格式。在这种格式中碱基对或氨基酸用单个字母来编码,且允许在序列前添加序列名及注释。
试着用记事本打开了一下,结果直接卡住了。
那么,这些应该是需要读取的数据了。我们利用二进制方式进行读取。
70多M,1000000个100位的碱基序列,要求在8G内存下建立索引。
既然是建立一个索引,那么对于给定的一个子序列,用字符串的方式来查找,真的很费时间,所以,我建立了一种规定,即:
将A替换成1;
将T替换成2;
将C替换成3;
将G替换成4。
我们可以这样定义代码:
//这是目前只是数字值转化的代码:
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
int getnum(int,int);
char s[100];
int a[100];//保存数值的数组
int numall=0;
int main()
{
int len,k;//len:求出有多少个序列 k:k个字符串
int i,j;
gets(s);
cin>>k;//输入整数值k
len=strlen(s);//获取序列的长度
for (i=0,j=0; i<(len-k+1); i++,j++)
{
a[i]=getnum(i,k);
cout<<a[i]<<endl;
}
}
int getnum(int n,int k)//获取单个序列的数字值,并将结果保存在a数组中
{
int numb,l,m=0;
l=n;
numall=0;
for (; n<k+l; n++,m++)
{
numb=1;
for (int i=0; i<k-m-1; i++)
numb=numb*10;
if (s[n]=='A')
numb*=1;
else if (s[n]=='T')
numb*=2;
else if (s[n]=='C')
numb*=3;
else if (s[n]=='G')
numb*=4;
numall+=numb;
}
return numall;
}我们将例题中的碱基序列输入进去:
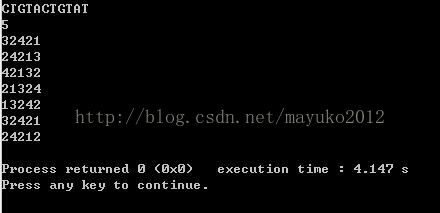
这样,进行数字进行查找,在代码上也会比较方便一些。
另一个是索引的建立,既然查找,我们首先想到的是从头到位一个一个的进行对比,符合了,找到了。
但是,在内存限制下,1000000个序列对于计算机也有些困难。
按照我们的思想,首先进行排序。
冒泡?选择?木桶排序?那个比较好?其实我也在忧郁,其实,最先想到的还是冒泡排序,所以,我们可以选择冒泡排序。
要记住,题目要求还有获得具体的位置,所以我们应该用一个另外一个数组和原数组做对应,也就是进行编号。
排序完成,编号数组不能变,原数组的规则是从小到大。
给定一个子序列,我们利用二分法获得具体位置,再找到编号,从而获得它在原数组的位置。
最后根据规则反译序列。
所有的流程,大概是这样子:

纯属个人见解,如有错误之处还望改正。
@ Mayuko














 4149
4149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









