







- 单机数据库
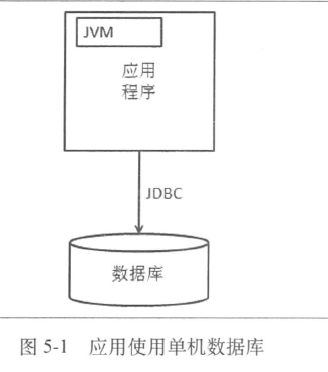
数据库减压:
- 硬件升级(简单粗暴、效果明显、很快进入瓶颈,解决不了)
- 其他三思路:
- 优化应用(是否给了数据库不必要的压力)
- 是否有其他办法减轻数据库的压力(引入缓存、搜索引擎)
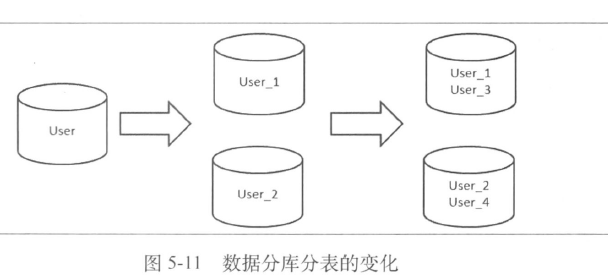
- 把数据库的数据和访问分布多台机器上
- 垂直拆分(不同业务单元拆分到不同的库里)
- 带来影响:
- 单机ACID 变得复杂
- Jion操作变得困难
- 靠外键约束场景受影响
- 带来影响:
- 水平拆分(按照一定规则,把统一业务单元数据拆分到不同库里面)
- 带来影响:
- 单机ACID 变得复杂
- Jion操作变得困难
- 靠外键约束场景受影响
- 单库的自增id 唯一序列受影响
- 单个逻辑意义上表的查询要跨库
- 带来影响:
- 垂直拆分(不同业务单元拆分到不同的库里)
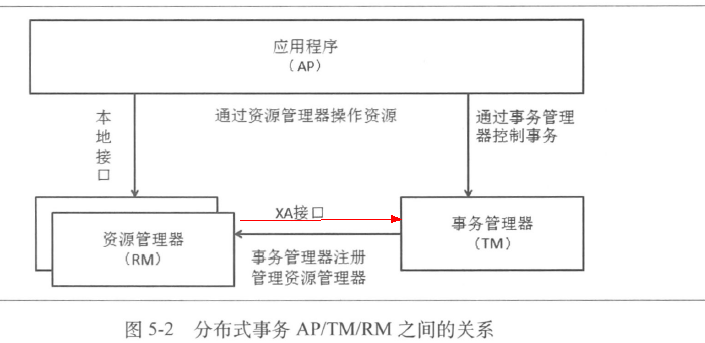
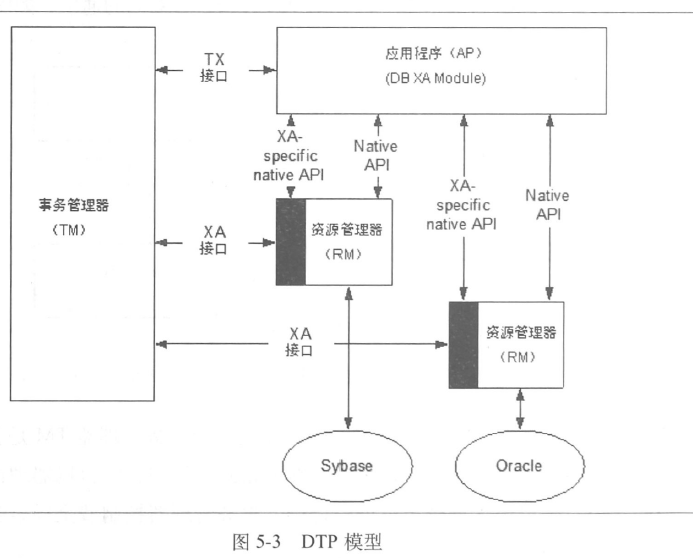
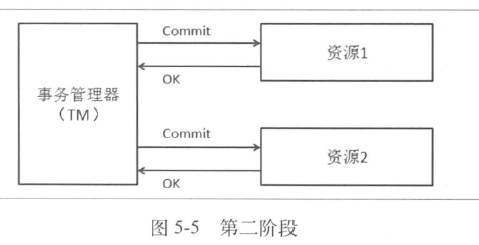
分布式事务x/open DTP模型
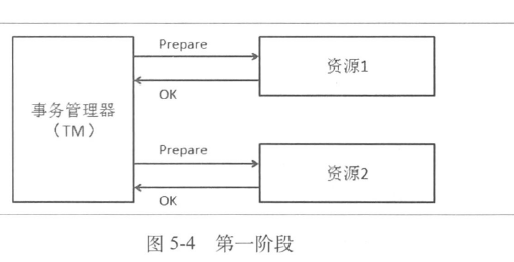
- 2PC(两阶段正常提交)
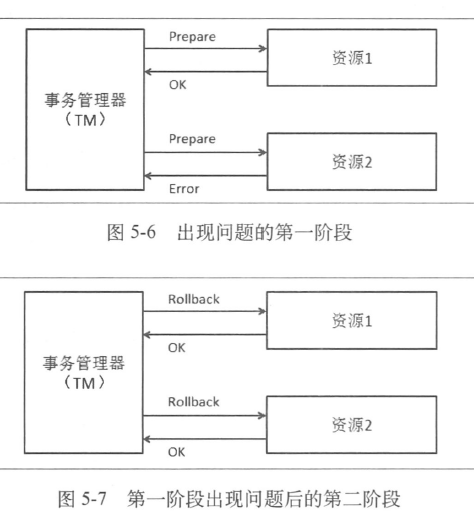
- 2PC(回滚情况)
CAP理论:
- 一致性
- 可用性
- 分区容错性

BASE理论:

- 选择AP 对于C ,确保最终一致性就好
Paxos 协议:
- 比两阶段更加轻量级的一致性协议
- 分布式系统中,节点之间信息交换有两种方式:
- 共享内存
- 信息投递
- 分布式系统中,信息投递会发生很多意外:网络问题、进程挂掉、反应很慢、进程重启、机器挂掉等
- 不存在拜占庭将军问题(即:通信环境不可靠)
- 本人已有博客专门讨论该问题,不做赘述
集群内数据一致性算法:
Quorum算法(权衡分布式系统中数据一致性和可用性的)

- W+R>N 强一致性
- W+R<=N最终一致性
Vector Lock算法
- 对同一份数据的修改,每次都加上<修改者,版本号>
- 比如:能看书Dave 的建议版本2最新


多机 Sequence 问题与处理
- 单机序列不是问题,分库分表后成为问题
- 连续性
- 唯一性
- 单考虑唯一性,UUID
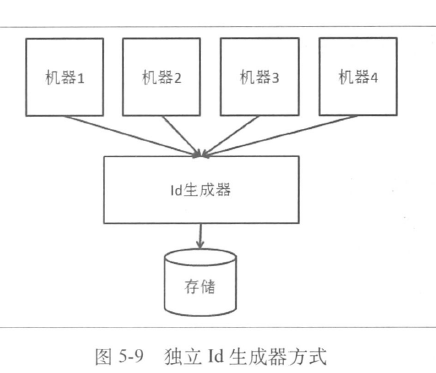
- 分布式系统中,可以考虑做一个独立的系统来完成该工作(ID生成器)
- 存在问题需要解决:
- 性能问题
- 每次远程取id 会有资源消耗(改进:每次取一段id,缓存到本地;但是取了后不用会照成浪费)
- 生成器稳定性问题
- id 生成器作为一个无状态集群,其可用性要靠整个集群来保证
- 存储的问题
- 选择空间大,需要根据不同类型对应不同的容灾方案
- 性能问题
- 存在问题需要解决:
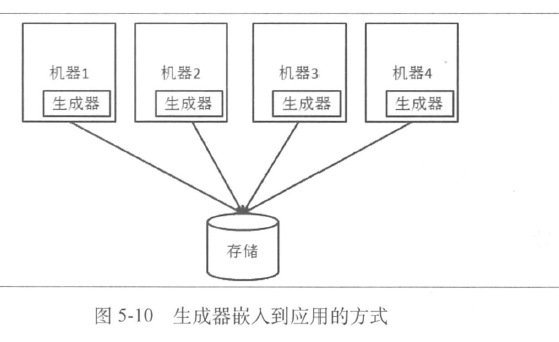
- 改进:省掉单独的id 生成器,这样数据可能不是严格的顺序增长的,需要额外的管理
应对多机的数据查询:
- 跨库join:
- 在应用层,把原来join 操作分成多个数据库操作
- 对常用数据进行冗余,变跨库为单表
- 借助外部系统解决一些跨库问题,比如:搜索引擎
- 外键约束
- 比较难解决,不能完全依靠数据库本身,需要应用程序的合作
跨库查询问题及解决:
- 具体要参看如何分库分表的
- 排序
- 各路先排好序、再多路归并排序
- 函数处理
- 求平均值
- 多数据源求和后,再算平均值
- 非排序分页
- 同等步长
- 数字代表所在页数
- 数字代表所在页数
- 同等比例
- 数字代表所在页数
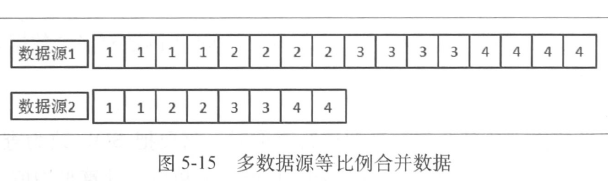
- 同等步长
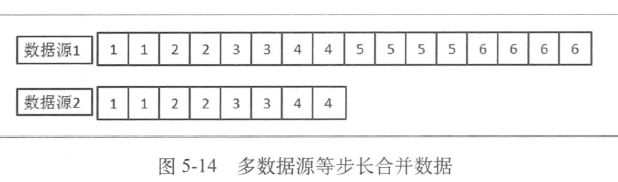
- 排序后分页
- 各个数据源排序,归并
- 大型系统请尽量避免
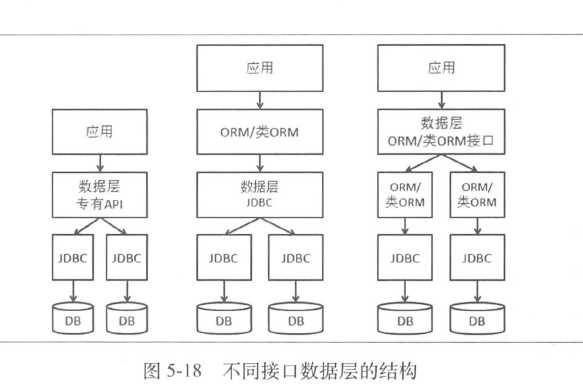
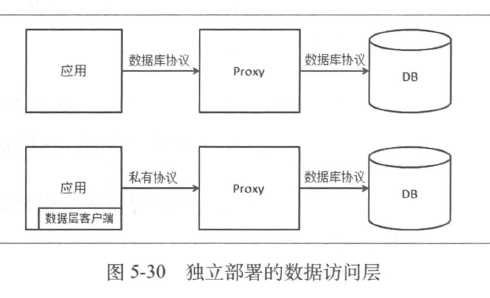
数据访问层,简称数据层:
- 数据读写的抽象层
- 对外提供访问层方式:
- 第一种:为用户提供专有API(不推荐,通用性很差),即便采用也要提供通用方式
- 第二种:通用方式,Java提供JDBC
- 还有一种,基于ORM类或ORM接口的形式(myBatis、hibernate、springJDBC)
- 合并排序查询场景下,取一页4条数据,需要在每一个数据源取4条作比较,取出排在最前面的4条
- 主要是要考虑极端情况,有可能某一数据源的4条数据就是要的4条
- JDBC 的方式实现
- 使用jdbc 的方式,可以设置每次取回的数据,做链式排序,分多次查询取回(要考虑网络平衡)
按照数据流程的顺序,看数据层设计
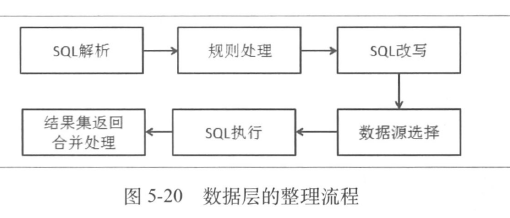
- 规则处理
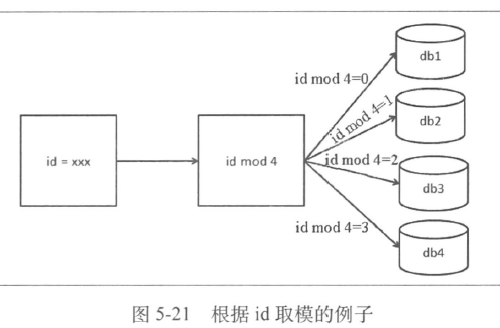
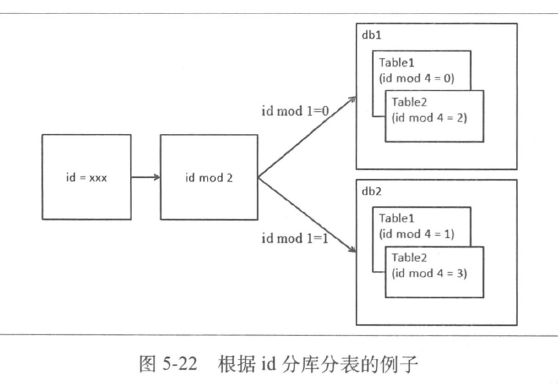
- 一致性哈希算法
- 把节点对应的hash 值变成一个范围
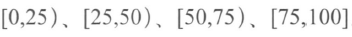
- 减去一个节点(范围),变成:
- 第一和第四管理的数据没影响,第三也没影响,把第二映射到第三就好
- 增加一个节点道理类似
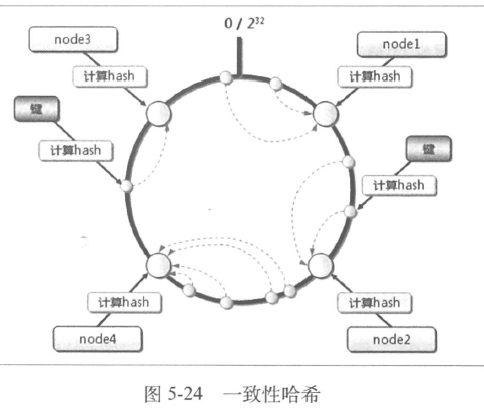
- 增加节点时,只有一个节点受影响,增加节点和受影响节点负载明显低于其他
- 减少节点反之
虚拟节点对一致性hash 进行改进
- 4个物理节点变成多个虚拟节点,增加一个物理节点就会增加相应的多个虚拟节点
- 这些插入的虚拟节点均匀分配到5个物理节点上
映射表与规则自定义计算
- 一般用于热点数据的特殊处理
自定义规则计算是最灵活的方式
########################
分库分表没有统一的规则
- 原则是分库后尽量避免跨库查询
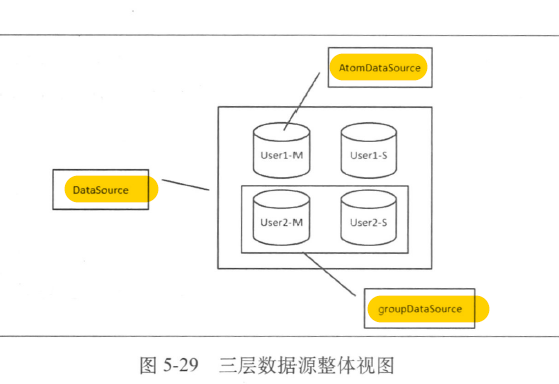
数据源管理多个分库
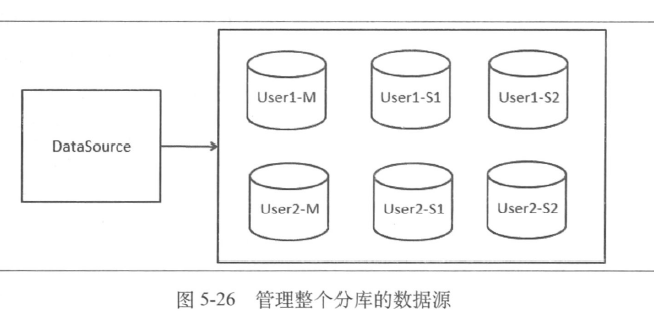
- spring 配置多个数据源
- 可以考虑在配置管理中心统一配置

- 数据源分组
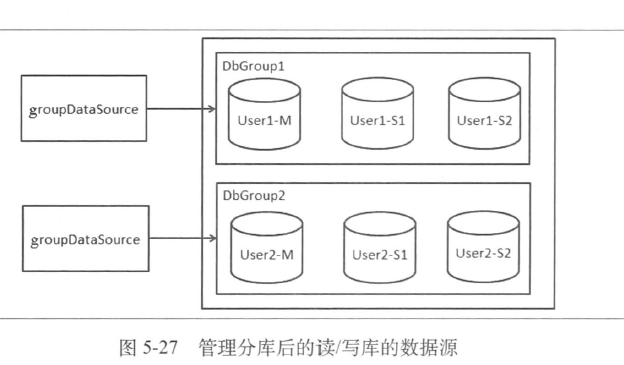
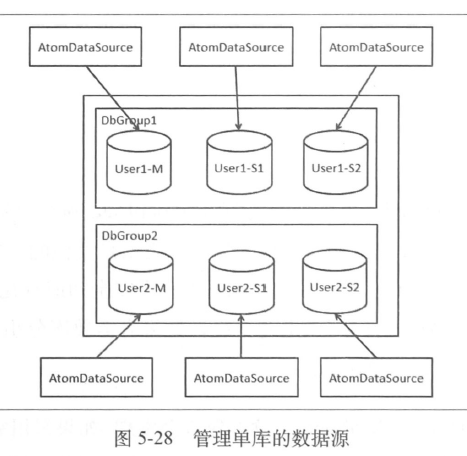
- 管理单库的数据源
- 可以把单个数据源配置集中起来统一存储
- 机房迁移改ip非常方便
- 禁止某些sql的执行等
- 三层数据源整体视图
- 独立部署的数据访问层
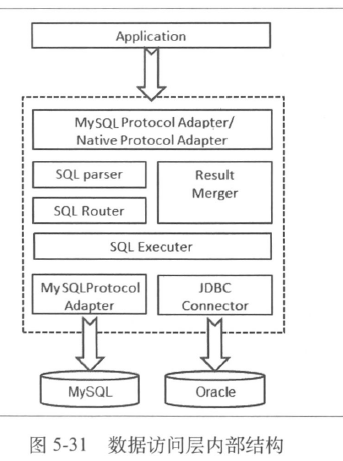
- 读写分离带来的挑战
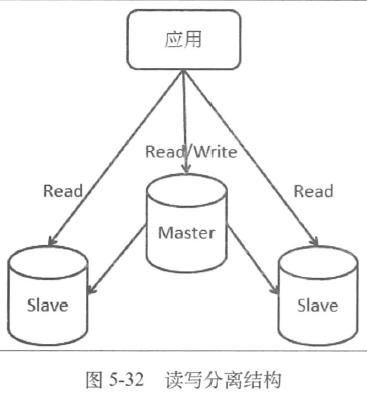
- 主库从库非对称场景
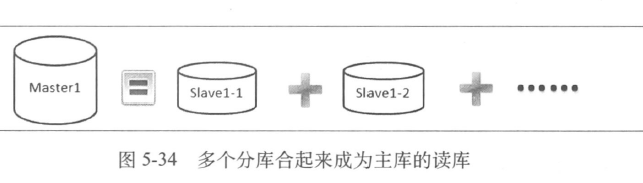
- 获得消息后开始进行数据的复制(行复制)
- 不优雅,优雅的方式应该采用基于数据库日志进行数据复制
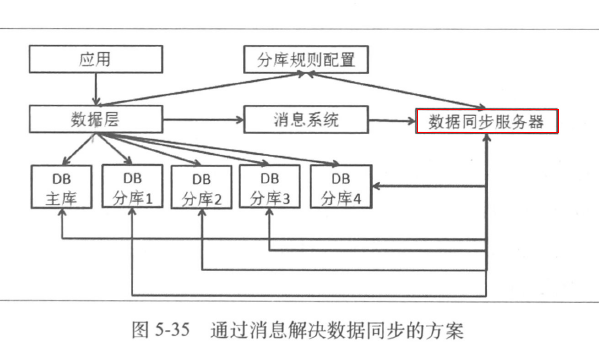
- 数据库复制在读写分离中是比较关键的任务
- 也有非对称场景:
- 主从不是镜像关系
- 主从采用不同库
- 也有非对称场景:
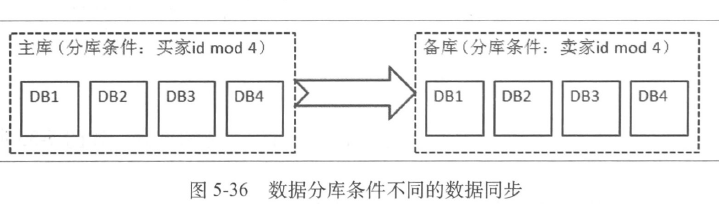
- 数据变更平台
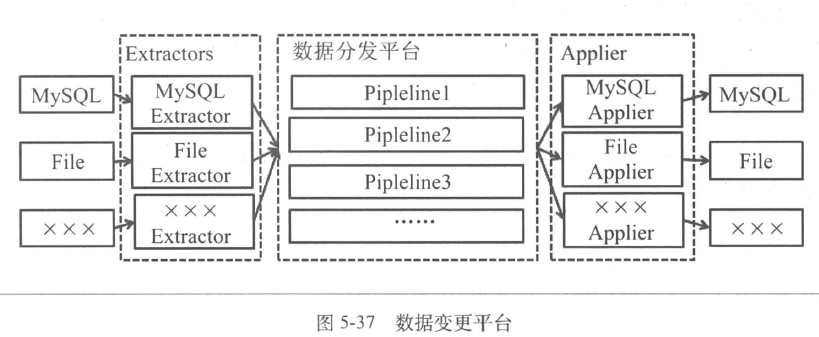
- 数据平滑迁移
- 扩容、缩容不能接受长时间停机:
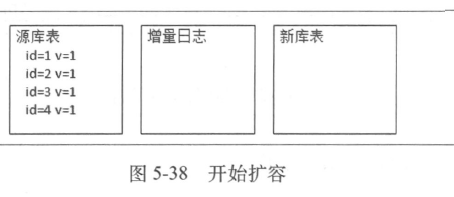
- 平滑迁移
- 最大挑战:迁移过程中又会有数据变化
- 可以考虑方案:
- 在开始进行数据迁移时,记录增量的日志,迁移结束后再对增量的变化进行处理
- 最后被迁移数据的写暂停,保证增量数据处理完毕,再放开
- 平滑迁移
- 扩容、缩容不能接受长时间停机:

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









