








和美大“家”

作者 | Wuxiang
编辑 | 品牌部
前 言
信息检索的核心问题就是在文档集中为用户检索最相关的子文档集,依靠排序算法对检索结果按照相关性进行排序,排序后的结果作为对用户所提出查询的回应。本文主要介绍搜素引擎Elasticsearch中全文检索相关性调整实战。
相关性算法
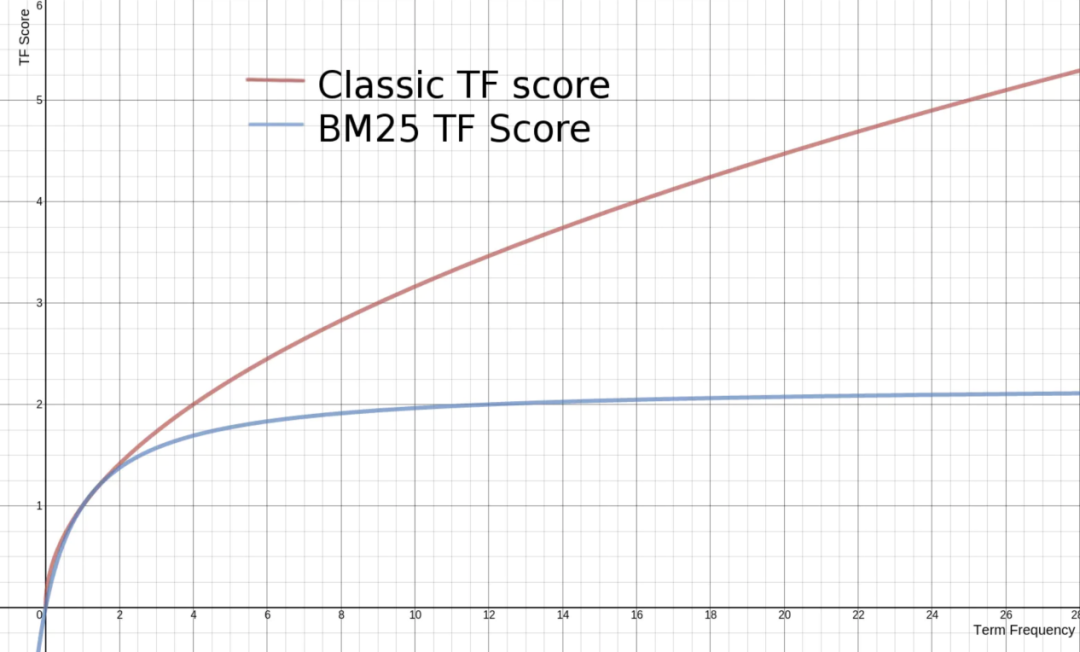
Elasticsearch在ES5版本之前默认使用经典的TF/IDF相关性算法,ES5之后默认使用基于概率模型的BM25(Best Match 25)相关性算法。和TF/IDF相比在BM25中词频对相关性评分的影响降低了,当TF无限增加时,BM25算法会趋于一个数值,如下图,ES提供了一种非常好的方式,实现了可插拔式的配置,允许我们控制每个字段的相关性算法。在 Mappings 设置阶段,我们可以调整 similarity 的参数并给不同的字段设置不同的 similarity 来达到调整相关性算法的目的。ES 提供了几种可用的 similarity,本文主要讨论BM25。
此处放上BM25算法公式,便于接下来对调整相关性实战结果的理解
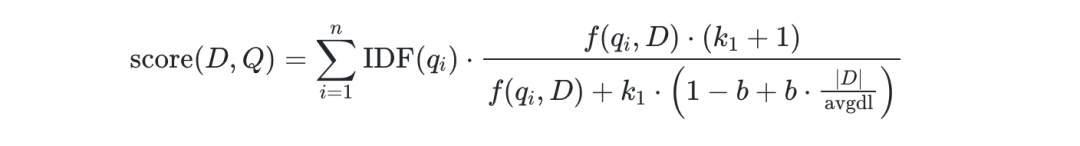
score(D,Q):这个公式最终的结果,Q表示query,D表示doc,表示一个query对一个doc的最终的总得分;
IDF(qi):idf算法对一个term的值;
f(xxx)/xxx:这一大串公式,即tf norm的计算公式;
∑ 求和符号:idf和tf norm结果相乘,最后求和;
其中k1 默认值是1.2, 数值越小,饱和度越高,b默认值是0.75(取之范围 0~1),0代表禁用Normalization。
调整相关性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7984
7984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









