






本人使用的python3.6.2版本的:

初次使用报了一堆错,具体如下:
1.pip install Pillow会报超时:
解决方案:需要加上超时控制:pip --default-timeout=100 install -U Pillow
2.pip install BeautifulSoup报print的错:
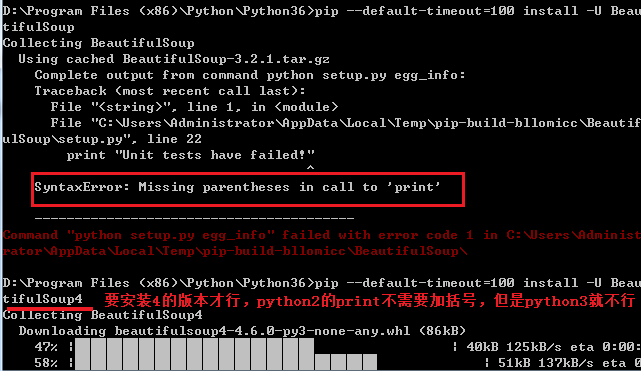
解决方案:加上版本:pip install BeautifulSoup4即可
3.使用BeautifulSoup(r,'xml')报错:
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?

解决办法:(转载的)
几经周折才知道是bs4调用了python自带的html解析器,我用的mac,默认安装的是python2,所以内置的解释器也是捆绑在python2上,而我学习的时候又自己安装了python3,开发环境也是python3的,貌似是没有html解释器,所以会报错。
问题找到了,那么怎么解决呢?对,在python3也装一个html解析器就好了,那么怎么安装呢?查阅资料获悉:一般pip和pip2对应的是python2.x,pip3对应的是python3.x的版本,python2和python3的模块是独立的,不能混用,混用会出问题。所以命令行通过python3的pip:pip3 安装解析器:
$ pip3 install lxml
3.8M,稍等片刻即可
再次运行项目,完美解决,特此记录
4.在 Python 下引用 Selenium 包开发时,刚开始测试 WebDriver 的功能直接就甩出了一个错误消息然后就中断了,错误消息: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/ch
第一个解决方法:
你去下载一个chromedriver然后放在指定文件夹并且加入PATH环境变量。结果是,我把chromedriver放进了chrome的文件夹,并且把那个文件夹加入了环境变量,然后不能用。
第二种解决方法:
直接把chromedriver.exe放到你运行.py程序的下面(也就是工作目录下)。就可以了。
参考的网址:http://blog.csdn.net/hacklyc/article/details/65445722
5.python输出csv文件乱码:
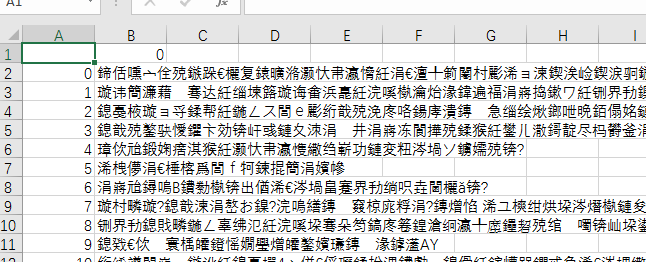
代码如下:
import requests
r = requests.get('https://book.douban.com/subject/1084336/comments/').text
from bs4 import BeautifulSoup
soup = BeautifulSoup(r, 'lxml')
pattern = soup.find_all('p', 'comment-content')
for item in pattern:
print(item.string)
import pandas
comments = []
for item in pattern:
comments.append(item.string)
df = pandas.DataFrame(comments)
df.to_csv('comments.csv')
解决办法:在代码最后一句加上encoding
df.to_csv('comments.csv',encoding='utf_8_sig')















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









