






本节研究应用层缓冲Buffer的实现;
应用层缓冲
说明几点:
(1)在非堵塞式网络编程中,应用层缓冲是必须的;应用层发送缓冲是必须的。如果TCP在发送20KB数据,还此时内核此连接的发送缓存仅仅有10KB。那么还未写入的10KB数据,我们应该缓冲到outputbuffer,而且注冊POLLOUT事件,等到内核此连接的发送缓存有空暇时。继续写入;等到outputbuffer中的数据写完,应该取消关注POLLOUT事件。
(2)应用层接收缓冲是必须的,TCP连接内核接收缓存可能并不完整的接收数据包,如果对方发送的完整消息为20KB,此时读取的数据为10KB,并不构成一个完整的消息,我们是不是应该在inputbuffer中缓存这些10KB数据,等到下次再读数据后,再继续推断是否构成一个完整的20KB数据;
(3)应用层发送缓存和接收缓存採用stl中的vector来实现,vector能够动态增长,为了应对增长时迭代器失效的情况,只保存指向的读写索引, size_t _readIndex,size_t _writeIndex;当_readIndex超过一定的数据位移后将会移动数据至开头处,这样能够增大数据可写的大小;
缓存示意图例如以下:
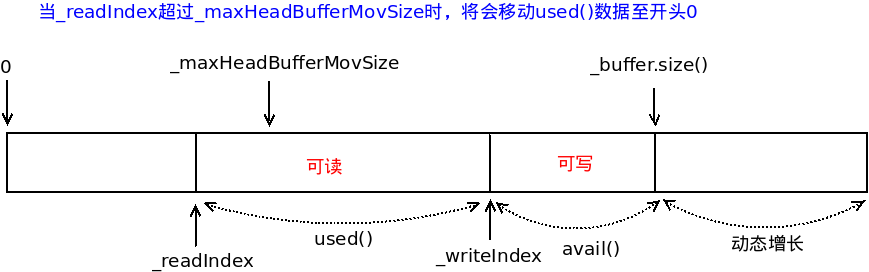
应用层发送缓冲示意图例如以下:
说明几点
(1)初始状态:发送缓冲还有30KB数据,此时TCP连接应该关注POLLOUT事件,将连接可读的数据write到内核的发送缓冲;当然用户也能够继续写入。
(2)用户继续写入20KB数据,可是为了不改变发送数据的顺序。此时数据仅仅能放入到未发送数据的后面,注意,用户写入数据和内核将可读数据写入到发送缓冲中不可能同一时候发生,由于它们都在TCP连接所属的IO线程中串行运行的;
(3)POLLOUT事件发生。内核发送缓存如果有了35KB数据可写,那么应用层发送缓冲中将有35KB数据被写入;
(4)用户下一次写入数据,当发送缓存的大小不能容纳用户写的数据时,首先推断_readIndex是否已经大于_maxHeadBufferMovSize(默觉得100字节)。那么就要将发送缓存的数据移动到开头处,这样会增大可写缓冲的大小;假设仍不能不能容纳用户写的数据,此时就将_buffer继续增长(大小为用户可写数据的大小*2)。

应用层接收缓冲示意图例如以下:
说明几点
(1)初始状态:接收缓冲还有30KB数据,此时TCP连接若还关注POLLIN事件。仍有可能将内核的接收缓存读取数据到接收缓存;当然用户也能够继续读取数据来处理;
(3)POLLIN事件继续发生。继续读取内核接收缓存的20KB放入到应用层的接收缓冲中;
(3)用户读取35KB数据来处理详细的业务逻辑;注意,用户读取数据和内核写入到应用层接收缓冲中不可能同一时候发生,由于它们都在TCP连接所属的IO线程中串行运行;
(4)POLLIN事件继续发生时,当接收缓存的大小不能容纳连接能够写入的数据时,首先推断_readIndex是否已经大于_maxHeadBufferMovSize(默觉得100字节)。那么就要将接收缓存的数据移动到开头处,这样会增大连接可写缓冲的大小。假设仍不能不能容纳连接可写的数据,此时就将_buffer继续增长(大小为连接可写数据的大小*2);

Buffer
buffer声明
class Buffer final
{
public:
Buffer() :
_readIndex(0),
_writeIndex(0)
{
_buffer.resize(_normalBufferSize);
}
void resize(size_t len) {
_buffer.resize(len);
}
void appendInt32(int32_t value)
{
value = endian::hostToNet32(value);
append(&value, sizeof value);
}
void appendInt16(int16_t value)
{
value = endian::hostToNet16(value);
append(&value, sizeof value);
}
void appendInt8(int8_t value)
{
append(&value, sizeof value);
}
void append(const void* buf, size_t len)
{
if (len > avail())
{
_expand(len);
}
::memcpy(_beginWrite(), buf, len);
_writeIndex += len;
}
std::string retrieveAllAsString()
{
std::string s(beginRead(), used());
setReadIndex(used());
return s;
}
std::string retrieveString(size_t len)
{
if (len > used())
len = used();
std::string s(beginRead(), len);
setReadIndex(len);
return s;
}
uint32_t retrieveInt32()
{
uint32_t value;
retrieve(&value, sizeof value);
return endian::netToHost32(value);
}
uint16_t retrieveInt16()
{
uint16_t value;
retrieve(&value, sizeof value);
return endian::netToHost16(value);
}
uint8_t retrieveInt8()
{
uint8_t value;
retrieve(&value, sizeof value);
return value;
}
uint32_t peekInt32()
{
uint32_t value;
peek(&value, sizeof value);
return endian::netToHost32(value);
}
size_t retrieve(void* buf, size_t len)
{
if (len > used())
len = used();
::memcpy(buf, beginRead(), len);
_readIndex += len;
return len;
}
size_t peek(void* buf, size_t len)
{
if (len > used())
len = used();
::memcpy(buf, beginRead(), len);
return len;
}
size_t avail() const
{
assert(_buffer.size() >= _writeIndex);
return _buffer.size() - _writeIndex;
}
size_t used() const
{
assert(_writeIndex >= _readIndex);
return _writeIndex - _readIndex;
}
ssize_t readFd(int connfd);
const char* beginRead() const
{
return _begin() + _readIndex;
}
char* beginRead()
{
return _begin() + _readIndex;
}
void setReadIndex(size_t len)
{
_readIndex += len;
}
size_t readIndex() const {
return _readIndex;
}
size_t writeIndex() const {
return _writeIndex;
}
void reset() {
_readIndex = 0;
_writeIndex = 0;
}
private:
void _setWriteIndex(size_t len)
{
_writeIndex += len;
}
void _expand(size_t len)
{
assert(_writeIndex >= _readIndex);
if (_readIndex > _maxHeadBufferMovSize)
{
::memcpy(_begin(), beginRead(), used());
_writeIndex = used();
_readIndex = 0;
}
if (len > avail())
{
_buffer.resize(_buffer.size() + len);
}
}
const char* _begin() const
{
return &(*_buffer.begin());
}
char* _begin()
{
return &(*_buffer.begin());
}
const char* _beginWrite() const
{
return _begin() + _writeIndex;
}
char* _beginWrite()
{
return _begin() + _writeIndex;
}
size_t _readIndex;
size_t _writeIndex;
std::vector<char> _buffer;
static const size_t _maxHeadBufferMovSize = 20;
static const size_t _normalBufferSize = 20;
};(1)append系列函数为写数据到缓冲中。此时有可能会运行_expand(size_t len),来调整_readIndex。超过_maxHeadBufferMovSize后将会移动数据至开头处,这样能够增大数据可写的大小。
(2)retrieve系列函数为从缓冲中读取相关数据来处理详细业务逻辑;主要用于接收缓冲的处理;对于发送缓冲,是直接正对发送缓存本身的_readIndex来处理的;
(3)peek系列函数不过看看缓冲池的数据,并不改变缓冲池的不论什么状态。
连接读函数
ssize_t Buffer::readFd(int connfd)
{
char extraBuf[64 * 1024]; //use memory in function stack
int remain = avail();
struct iovec iov[2];
iov[0].iov_base = _beginWrite();
iov[0].iov_len = remain;
iov[1].iov_base = extraBuf;
iov[1].iov_len = sizeof extraBuf;
ssize_t len = sockets::readv(connfd, iov, 2); //len can be 0 or -1
if (len > remain)
{
_setWriteIndex(remain);
append(extraBuf, len - remain);
}
else if (len > 0)
{
_setWriteIndex(len);
}
return len;
}(1)读数据时,我们并不知道读取的数据为多大大小,如果盲目扩大应用层接收缓冲池的可写区域的大小,可能内核的接收缓存仅仅有少量数据。我们充分利用栈上的64KB缓存,利用readv函数,将内核的接收缓存分别读取到两块内存上(第一块为应用层接收缓存。第二块为栈上的64KB内存),当第二块(栈上的64KB内存)内存上有数据时,我们再将这些栈上读取的数据放入到应用层的接收缓存中;
















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









