






1. 基本查询语句
SELECT属性列表FROM表名和视图列表[WHERE 条件1]
[GROUP BY 属性名1 [HAVING 条件2]][ORDER BY 属性名2 [ASC | DESC]]
2. 单表查询
建立表如下:
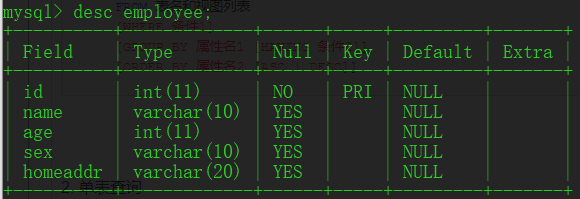
(1)列出所有字段、部分字段
可以在select后列出所有字段,可以自定义显示顺序;可以列出部分字段显示
用 * 符号表示所有字段
(2)where条件
查询条件:

AND优先级高于OR
①like '字符串'
可使用完整字符串、%、_ 通配符
%:代表任意长度的字符串
_:表示单个任意字符
(3)查询结果不重复
SELECT DISTINCT 属性名
对于有重复值的该字段,消除重复值。
(4)分组查询
①单独使用GROUP BY 分组
只显示一个分组的一条记录
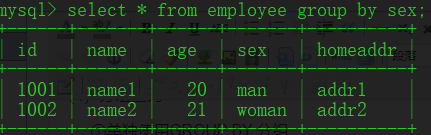
②GROUP BY 与 GROUP_CONCAT() 函数一起使用
将每个分组中该函数指定的字段值都显示出来
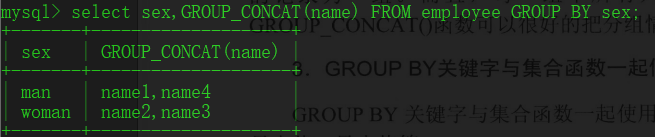
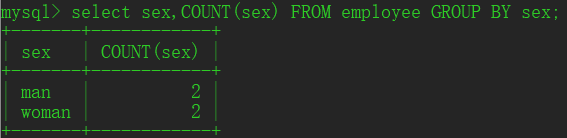
③GROUP BY与集合函数一起使用
计算每个分组中记录数:
SELECT sex,COUNT(sex) FROM employee GROUP BY sex;
求各分组中age最大、最小的:
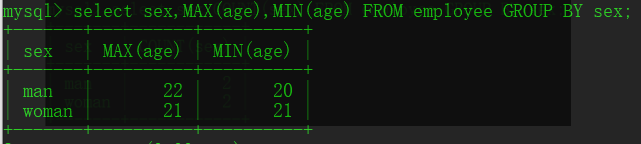
常用集合函数:COUNT() MAX() MIN() SUM() AVG()
④GROUP 与 HAVING 一起使用
HAVING后跟条件表达式
【WHERE用于表或视图,而HAVING用于分组后的记录】
(5)按多个字段分组
GROUP BY 字段1,字段2
先按字段1分组,遇到字段1相等的再将字段1相等的记录按字段2分组
(6)GROUP BY 与 WITH ROLLUP
使用WITH ROLLUP,会在所有记录的最后加上一条记录,该记录是上面所有记录的总和

(7)使用LIMIT限制查询结果数量
① LIMIT 记录数
② LIMIT 初始位置,记录数
查询到的第一条记录位置是0
3. 多表连接查询
(1)内连接
两个表为例:当两个表中有意义相同的字段时,该字段值相等就查询出该记录
SELECT 属性名列表 FROM 表1,表2 WHERE 表1.属性a=表2.属性b;
SELECT 属性列表 FROM 表1 inner join 表2 ON 表1.属性a=表2.属性b;
(2)外连接
①左连接
SELECT 属性名列表 FROM 表1 LEFT JOIN 表2 ON 表1.属性a=表2.属性b;
查询出表1所有记录,而表2中匹配的记录
②右连接
SELECT 属性名列表 FROM 表1 RIGHT JOIN 表2 ON 表1.属性a=表2.属性b;
查询出表2所有记录,而表1匹配的记录
(3)自连接
例:一个员工表,存储了员工本身的id、name以及他上级的id(员工表包括了所有人,包括各级上级)
表的内容:
id name boss_id1 name1 3
2 name2 3
3 name3 4
4 name4 null
自连接查询:
SELECT t1.id,t1.name,t2.id,t2.name FROM table1 t1,table1 t2 WHERE t1.boss_id = t2.id;
结果:
id name id(1) name(1)1 name1 3name32 name2 3name33 name3 4 name4
这样就可以看出1的上级是3;2的上级是3;3的上级是4;而4没有上级
4. 子查询
查询语句的嵌套
①IN、NOT IN
SELECT 属性名列表 FROM 表1 WHERE 字段a IN (SELECT 字段b FROM 表2);
②ANY
ANY表示满足内层查询结果任何一个,就可以通过该条件执行外层查询语句
③ALL
表示只有满足内层查询的所有结果,才对其执行外层查询语句
④EXISTS
内层查询不返回查询的记录,而是返回真值、假值
5. 合并查询结果
UNION:将所有查询结果合并到一起,去掉多个SELECT得到的相同的记录
UNION ALL:不去除相同的记录
6. 表、字段取别名
表别名是为了在指定表的字段时便于书写
字段别名作为返回结果,而不是显示字段名
SELECT a.id XID,a.name XNAME FROM longnametable a;
7. 使用正则查询
格式: 属性名 REGEXP '匹配方式'
常用模式字符:
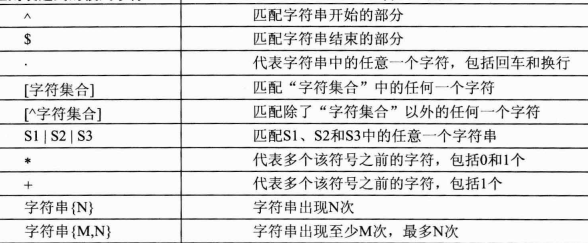
LIKE和正则:
LIKE 在列值中匹配整个文本
REGEXP匹配部分















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









