







开篇:
对于数据结构及算法的学习在17年时就已经在博客中开了专栏:

但是!!!感觉学得有点零散,有c版本的,也有java版本的,没成体系,当然其效果也并没达到自己满意的效果,基于此,这里准备重新开个专栏:

准备从0开始构建一个Java版本对于算法与数据结构的学习体系,重点是要“系统”,正好也对于之前所学的算法进行一个重新梳理,并且再将自己的算法功底拔高一下,说实话算法的学习是比较枯燥的,但是它的作用也不言而喻,枯燥在重要性面前是可以咬牙坚持的,然而要想达到拔高的效果那只能一点点从基础知识的夯实再到找到写算法的感觉,最后再来学一些高级的算法,整个过程离不开四个字:“践踏实地”,另外学习它也不能过猛,周期性的一点点来学于我而言是比较舒服的,所以下面全新开启算法之旅啦~~
环境说明:
jdk的版本:
既然是用到Java语言来学习,JDK的版本这里也稍加说明一下,只提一下版本,其它的安装啥的就不过多说明了,网上一大把,这里使用的是使用量最大的JDK8这个版本,而它的小版本呢,先来看一下目前官方是定位到了哪个号:

但是!!!这里不用最新的,而是用Java SE 8u251,为啥?因为跟课程保持同步,而对于它的下载包,可以直接google既可:
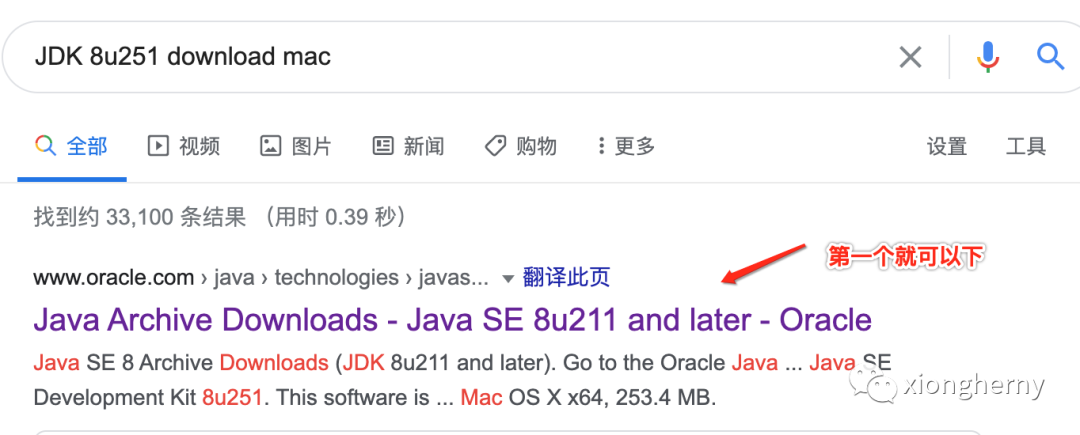

然后点击时,oracle现在要求登录才能下。。
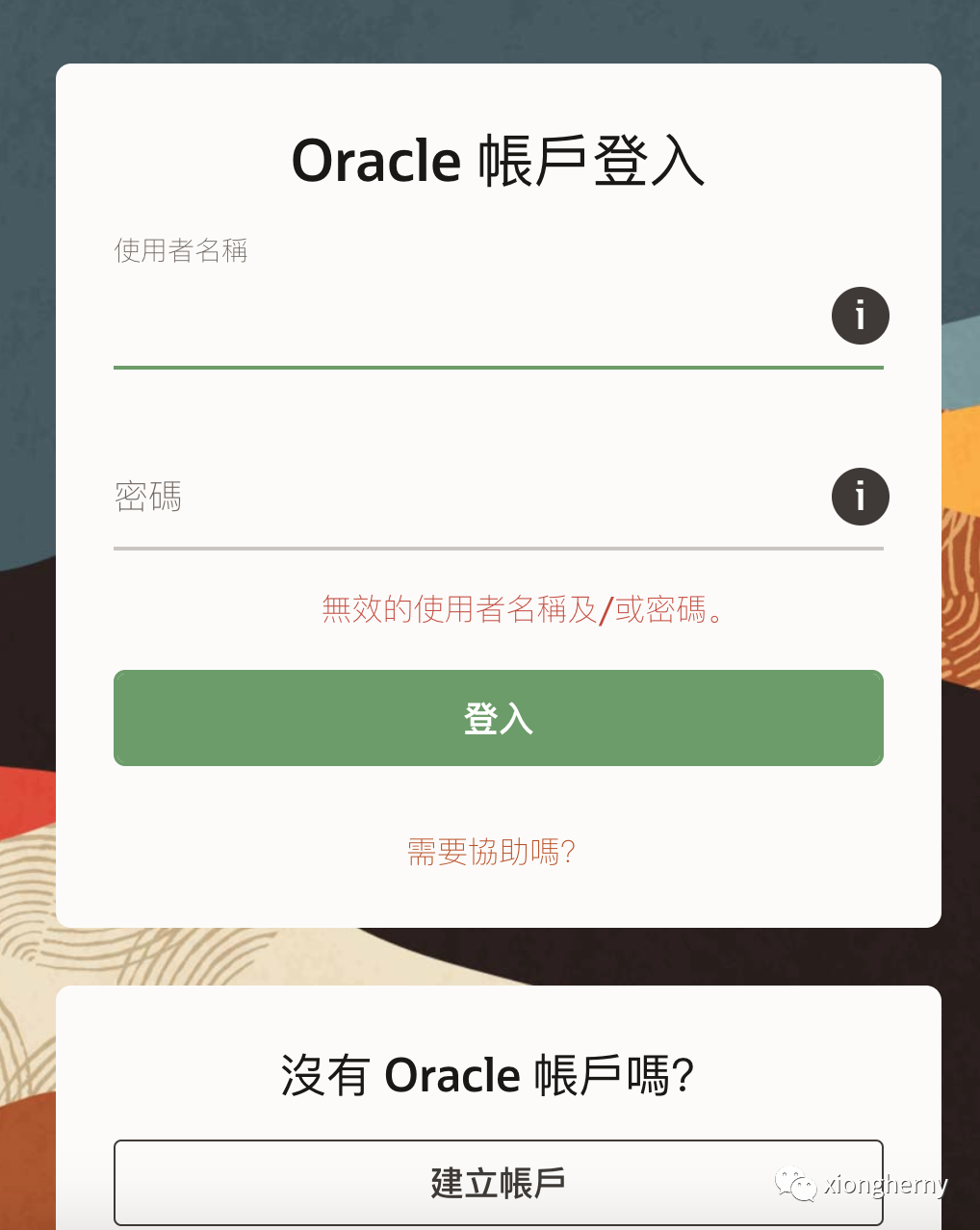
发现我木有账号。。那创建一个呗,然后再登录,下载就走起了:
当然我司的渣网下了我半天,按向导一步步安装既可,注意!!这里不需要一定得修改JAVA_HOME来指向这个版本,毕竟这个版本下下来仅为了学习,因为IDE在创建工程时可以动态来指定需要本地的哪个JDK版本,到时我们创建工程指定既可。安装成功后,则会在此目录多一个对应的版本,看下我本机安装的好多。。

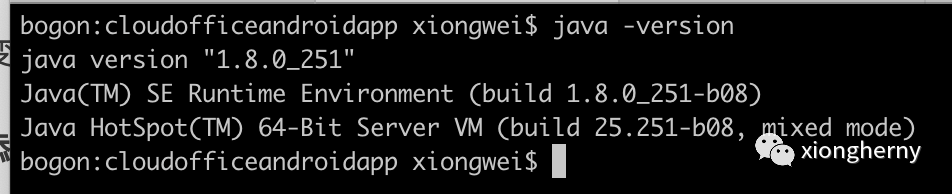
然后目前我电脑也已经使用此版本了:
使用的IDE:
对于Java的IDE,不用说,都是它了:
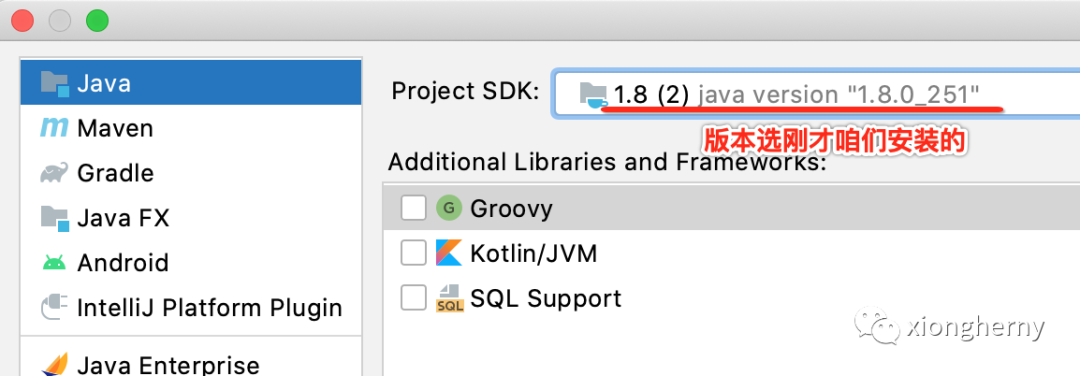
然后在创建工程时重点就是选择一下JDK的版本为刚才咱们安装的既可:
什么是算法:
呃,看到这标题貌似太文绉绉了,但是!!!这里还是将其列出来,为啥?为了能成“体系”,而且多看一眼理论其实也没啥坏事,反而根据自己这么多年学习技术的心得来看,理论+实战才是夯实技术的最佳学习法,当然这是于我这种比较笨的人来说,所以不能对简单的概念说no,下面当一个PPT过一下既可:
一句来来描述:“算法是一系列解决问题的,清晰,可执行的计算机指令”。然后算法它有五大特性:
有限性:
一个算法不应该是无限循环的,而应该是在有限的时间内能够执行完,但是这个“有限性”的时间不一定非常短,有可能是比较长的。确定性:不会产生二义性
它的本质就是描述其算法的计算机指令都是清晰且含义唯一的,比如一个不确定性的例子,就是有一堆数据它时表示一个班集所有同学不同科目的考试成绩,而在设计某个算法时有一个指令是“拿出成绩最高的那个学生”,那么这个算法就具有不确认性,为啥?因为成绩最高是语文还是数学呢?
但是!!!这个确定性并不是指算法不同的输入其输出也是相同的,举个随机算法为例输入可能是同一个但是其输出会是不同的。可行性:
比如说设计一个算法,其中算法的有一个指令是“拿出最大的质数”,这个指令就具有不可行性了,因为质数是有无穷个的,
以上三种特性其实就是说一个算法并非只是口头说明,最终一定是可以落地的代码的。输入:
这个要跟函数的输入区分开,这里是一个更加泛的概念,其实就是算法要操纵的对象就可以说是算法的输入, 而具体表现到程序中,一个算法操作的对象可能定义在一个类中,可能是一个成员变量并非是函数的参数都算是算法的输入。或者有可能算法操纵的对象隐藏在语义当中,比如设计一个算法:生成0这个数字,在函数设计中直接返回0既可,而这个0其实也叫做算法的输入。输出:
同理,如果一个函数是一个void,并不代表该算法木有输出,比如说在屏幕中绘制了一个圆,很有可能这个绘制函数木有返回值,但是绘制是一个算法,它的输出就是绘制了一个圆;再比如一个算法就是休眠x分钟,其中x是一个输入,这个函数是一个void没有返回值的,但是这个算法是有输出的,其输出就是程序休眠了x分钟。所以对于算法的输入与输出都需要站在一个更加抽象的角度来看待它,而不能以函数的方法参数及返回值来看待算法的输入与输出。
最简单的算法:线性查找法:
接下来则从一个最简单的算法学起,也就是如题线性查找法,这种算法其实在实际中会经常使用,比如:在一沓试卷中,找到属于自己的那张试卷,这不简单,一张张进行查找呗,如下:

这就是典型的线性查找法,回到程序场景中,比如在data数组中查找16这个数字,而此data的形态为:
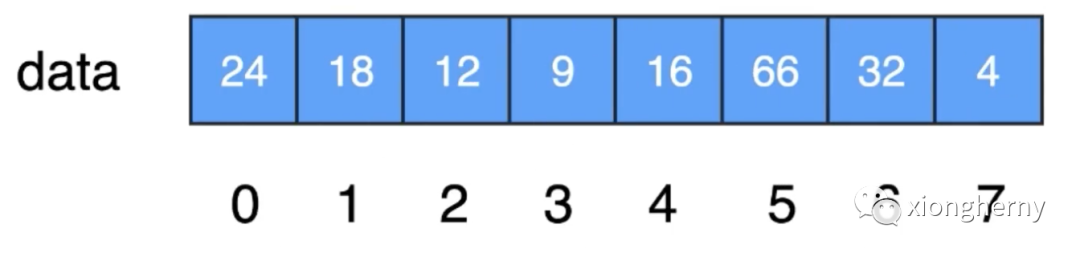
而对于数组的查找so easy,直接拿个下标进行一一查找:
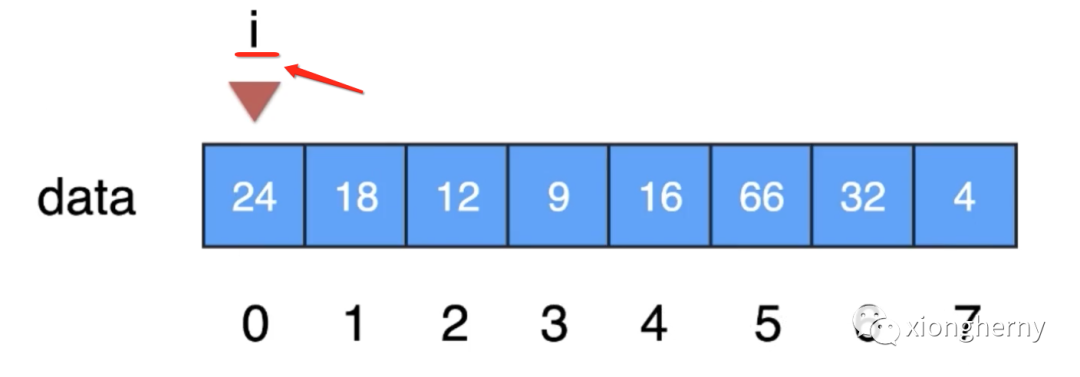
这块的查找代码其实已经非常熟了,但是这里还是以算法的角度把自己当小白从头来一下,发现此时24不是要找到数字,此时下标i++,形态就变为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









