







一、SequoiaDB巨杉数据库大对象块存储操作指南
SequoiaDB提供基于shell的命令行界面,以及C、C++、Java、Python、PHP、Nodejs等驱动访问原生LOB API。同时,SequoiaDB提供访问协议的CM API Java接口。本文将会就命令行、C++、Java以及CM API接口进行详细描述。
5.1 命令行
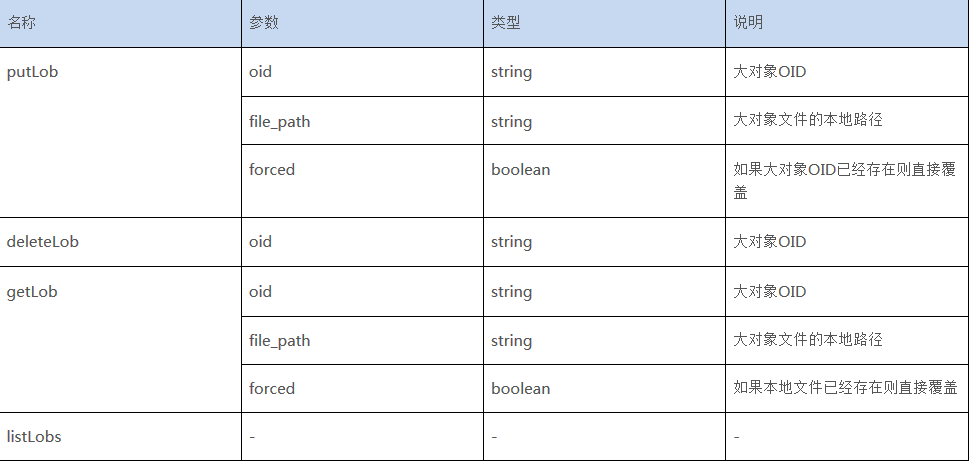
表1:命令行操作指令
样例:
> db.foo.bar.putLob('/opt/sequoiadb/standalone/diaglog/sdbdiag.log')
579f55b7389d2aef0a000000
Takes 0.166125s.
> db.foo.bar.listLobs()
{
"Size": 29342,
"Oid": {
"$oid": "579f55b7389d2aef0a000000"
},
"CreateTime": {
"$timestamp": "2016-08-01-21.59.19.939000"
},
"Available": true
}
Return 1 row(s).
Takes 0.6703s.
> db.foo.bar.getLob('579f55b7389d2aef0a000000', '/opt/sequoiadb/standalone/test.log')
{
"LobSize": 29342,
"CreateTime": {
"$timestamp": "2016-08-01-21.59.19.939000"
}
}
Takes 0.910s.5.2 C++
sdbclient::sdbCollection类:
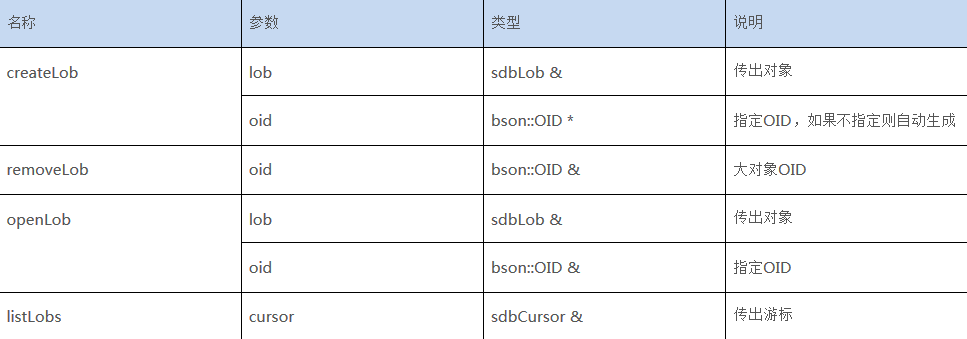
表2:sdbCollection类中LOB相关函数
sdbclient::sdbLob类:
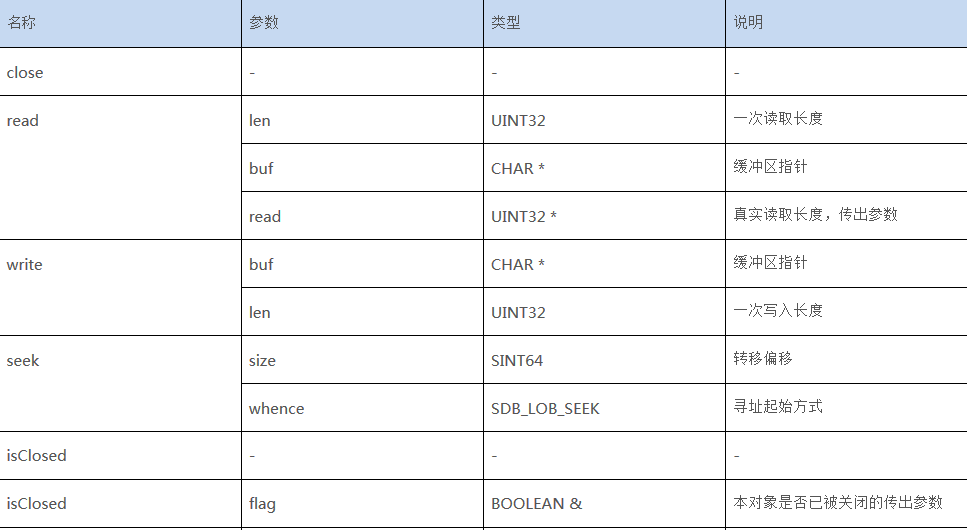
表3:sdbLob类中的相关函数
样例代码可以参考安装目录下samples/CPP/lob.cpp文件。
5.3 Java
com.sequoiadb.base.DBCollection类:
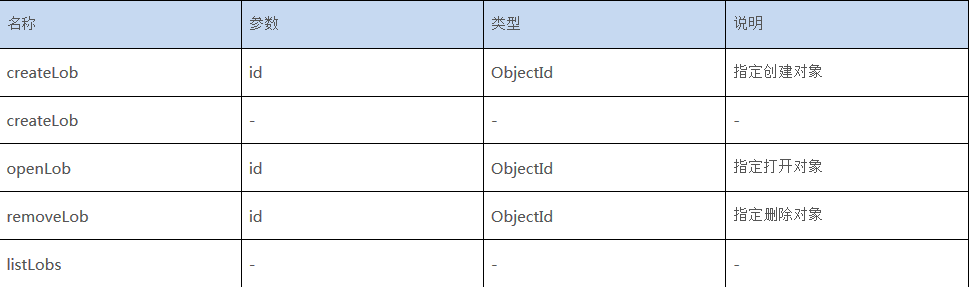
表4:DBCollection类中LOB相关函数
com.sequoiadb.base.DBLob类:
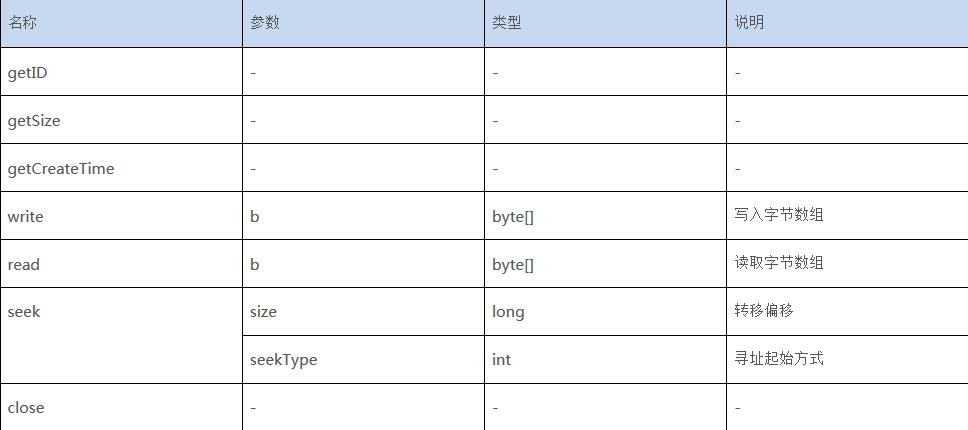
表5:DBLob类中的相关函数
样例代码可以参考安装目录下samples/Java/com/sequoiadb/samples/Lob.java文件。
5.4 CM API
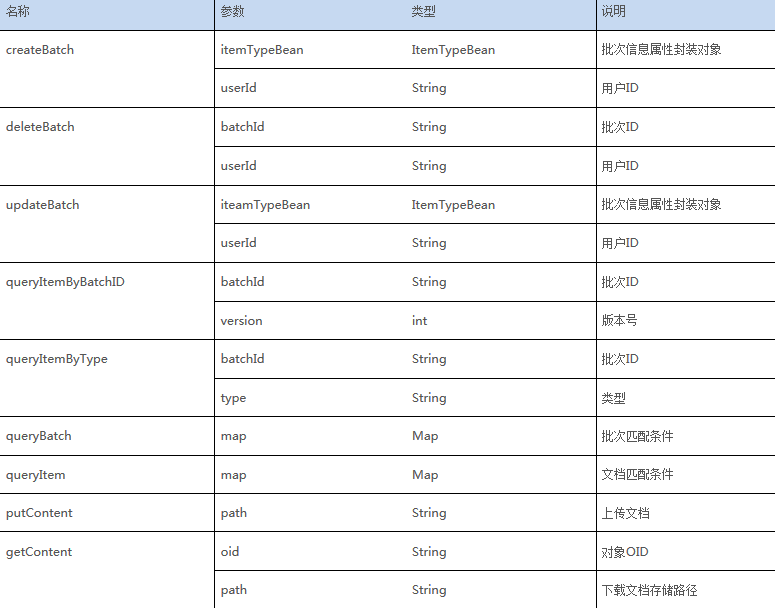
表6:CM API中的相关函数
六、性能指标
6.1 系统配置
本文测试使用3台物理机作为服务器与1台物理机作为客户端。客户端使用C程序与服务端直连,使用LOB API进行读写访问操作。
服务端
CPU:Intel® Xeon® CPU E5-2420 0 @1.90GHZ(6core *2) (一台物理机)
CPU:Intel® Xeon® CPU E5-2620 V2@ 2.10GHZ (6core *2) (二台物理机)
MEMORY:48
DISK: 2T/6块
客户端
CPU:Intel® Xeon® CPU E5-2420 0 @1.90GHZ(6core *2) (一台物理机)
MEMORY:48
DISK: 2T/6块
集群部署方式为6分区3副本,三台机器构成高可用集群,网络为千兆网,协调节点与编目节点分别部署在3台服务器上。数据节点分布见表3,其中红色部分代表该分区的主节点,黑色为从节点。
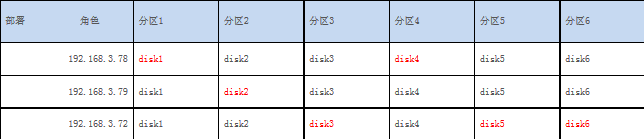
表7:数据节点分布
6.2 写操作测试
文件系统的配置分别使用两种方式:打开DIO以及用普通文件系统缓存方式。
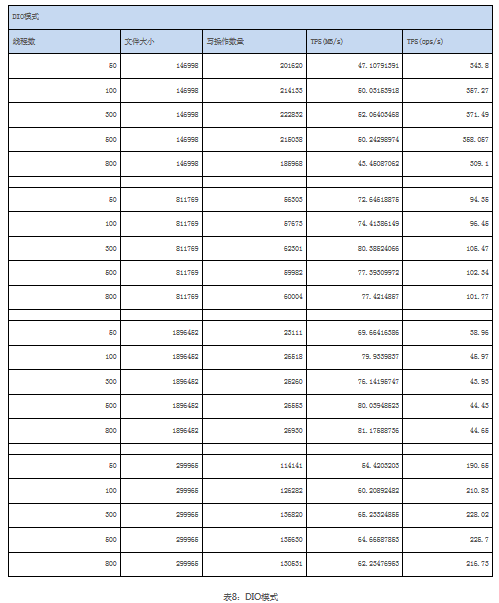
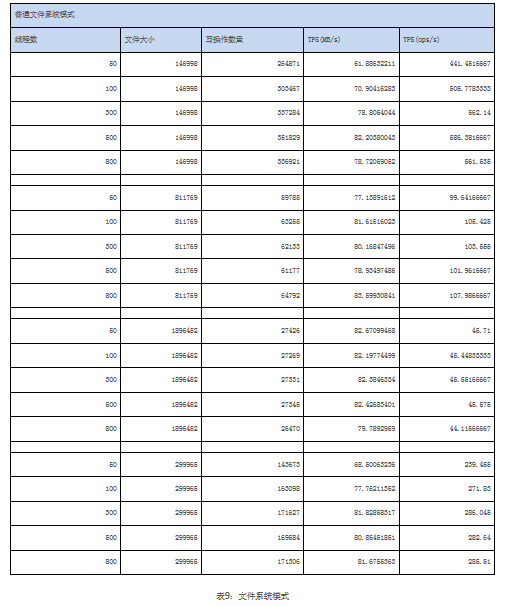
可以看到,打开DIO与普通文件系统缓存相比,性能确实存在一定下降。在三台服务器的情况下,尺寸较小的文件在DIO打开的情况下显示出与普通文件系统缓存更大的差异。当文件尺寸平均达到1-2MB左右后,使用DIO与普通文件系统的差异几乎可以忽略不计。图1显示了启用与关闭DIO的情况下,在800线程并发中整个集群的吞吐量(MB/s)。
图4:写操作吞吐量对比
6.3 读操作测试
不同于写操作,SequoiaDB LOB机制在读操作中受DIO的影响较小。
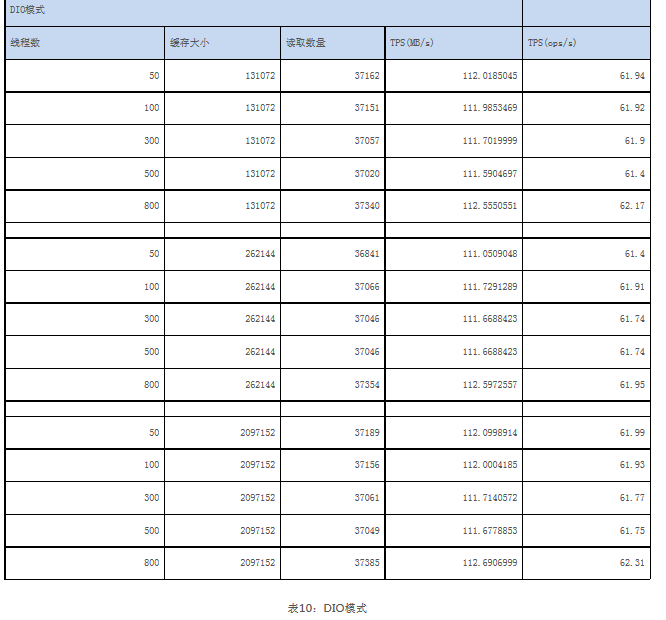
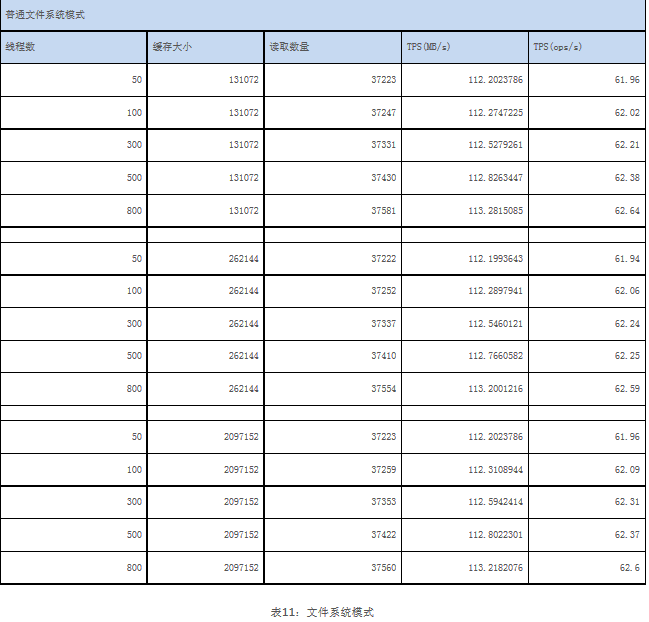
在文件读取的过程当中,因为绝大部分读取都是顺序I/O,因此是否打开文件系统缓存基本对性能不构成影响。从性能读数可以看出,SequoiaDB LOB读取时每次读取的缓存大小对于读取性能基本上不构成太大的影响。
测试中吞吐量上限基本达到客户端千兆网瓶颈,因此通过增加网络带宽依然有可以提升的空间。
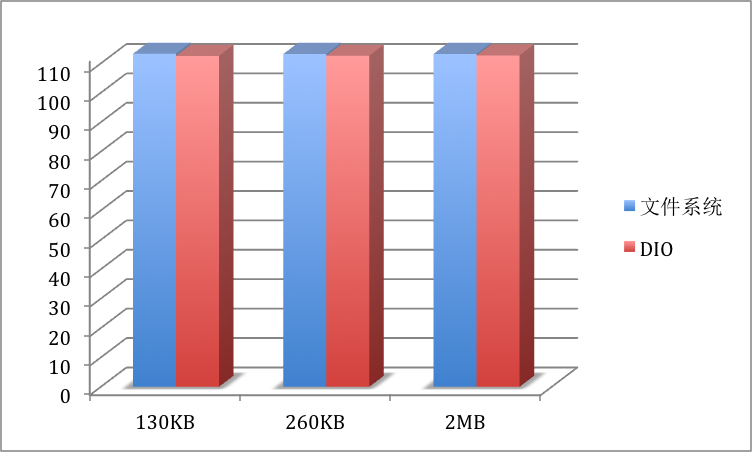
图5:读操作吞吐量对比
七、结论
SequoiaDB的大对象机制主要为用户存储海量中小型文件所设计。通过配置pagesize大小,SequoiaDB在存储100KB到100MB区间内的文件性能与磁盘开销比例最优,因此针对各个企业的票据、扫描件、合同件、照片、小视频、音频等文件最为适用。
总体来看,使用SequoiaDB替代传统ECM,为企业存储海量中小型文件不单能够大大降低企业的总体拥有成本,还能够大幅度提升数据访问层面的吞吐量,并从开发、运维、管理等各个层面大幅度降低使用难度,帮助企业更快地在企业内容管理系统上落地。
















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









