







背景
神经网络硬件是计算机体系结构、人工智能和神经科学等多学科深度融合、交叉的一个领域,是利用专门的硬件电路对神经网络算法进行处理。二十世纪八九十年代,国内外曾掀起一阵研究神经网络硬件的热潮。但是由于整个智能领域的研究陷入低潮,神经网络硬件的研究也趋于停滞。近年来,计算机体系结构、人工智能应用出现了一些新的趋势,神经网络硬件加速器又重新回到工业界和学术界的视野。
计算机体系结构:暗硅
自计算机诞生以来,性能不断提升的处理器芯片使人类处理和计算大规模数据的能力不断增强,强大的计算能力也推动着其他学科的不断发展,反过来各个学科也促使人类不断追求更加强大的计算能力。
处理器芯片厂商一直以来都是通过更高的主频来提升计算机性能。根据摩尔定律,处理器芯片上的晶体管数量和峰值功耗都在不断增加。由于时钟频率的提高和泄漏电流的增加,需要提高驱动电压来快速识别晶体管的状态。驱动电压与时钟频率有一定的正比关系,根据晶体管的功耗估算公式,可以得出,功耗的增加大大超过了性能的提升。根据英特尔公司的研究报告![[1]](http://static.oschina.net/uploads/img/201507/15162918_4AKQ.gif "[1]") ,3%的功耗只能带来1%性能的提升,这种代价过于昂贵。功耗的提升和处理器芯片有限的封装散热能力也有突出的矛盾。受限于封装功耗,大部分的晶体管无法同时全速工作,出现“暗硅(dark silicon)”[23, 66]。目前晶体管工艺仍有发展空间,随着三维堆叠(3D-stack)技术的发展,可以预见芯片的集成度仍将提升,功耗密度(powerdensity)将使散热问题更加突出。
,3%的功耗只能带来1%性能的提升,这种代价过于昂贵。功耗的提升和处理器芯片有限的封装散热能力也有突出的矛盾。受限于封装功耗,大部分的晶体管无法同时全速工作,出现“暗硅(dark silicon)”[23, 66]。目前晶体管工艺仍有发展空间,随着三维堆叠(3D-stack)技术的发展,可以预见芯片的集成度仍将提升,功耗密度(powerdensity)将使散热问题更加突出。
目前工业界和学术界的共识是:体系结构需要用“暗硅”实现加速器——针对特定应用或算法而定制的硬件电路![[9]](http://static.oschina.net/uploads/img/201507/15162918_URRG.gif "[9]") 。从移动通信终端到数据中心,加速器是提升性能和能效的最有效手段。有研究表明,加速器能够使一些应用的能效提升50~1000倍[29]。神经网络硬件加速器又重新成为体系结构研究的重要内容。
。从移动通信终端到数据中心,加速器是提升性能和能效的最有效手段。有研究表明,加速器能够使一些应用的能效提升50~1000倍[29]。神经网络硬件加速器又重新成为体系结构研究的重要内容。
人工智能:深度学习技术
神经网络的研究分为生物启发的神经网络(bio-inspired neural network)和人工神经网络(artificialneural network)两类。前者由神经生物学家关注,用于建立一种合适的模型(从生物学而来)来帮助理解神经网络和大脑是如何工作的,比较有代表性的是脉冲神经网络(spiking neural network)[45]。最近,IBM在《自然》(Nature)上发表了他们的成果——TrueNorth[48],高通公司也宣布生物启发的神经网络芯片Zeroth处理器[38]的消息。这些模型都采用了更加接近生物学的模型,并且已经有一些实际应用的场景。
人工神经网络是机器学习方法的一种,其起源要追溯到1943年麦卡洛克(McCulloch)和皮茨(Pitts)的工作[46]。他们设计的神经元模型构成的网络原则上可以计算任何函数。1949年赫布(Hebb)的工作阐述了突触修正的生理学模型。1958年罗森布拉特(Rosenblatt)第一个提出了感知器作为有监督学习的模型,80年代霍普菲尔德(Hopfield)发表了一篇引起巨大争论的论文[31],也推动了神经网络研究的高速发展。最近本希奥(Bengio)、欣顿(Hinton)等人提出的深度学习 [39]在许多应用程序上(如网页搜索、图像分析、语音识别等)表现出良好的特性,激起了人们的极大热情,再次推动了神经网络研究的发展。深度神经网络(Deep Neural Network, DNN)和卷积神经网络(ConvolutionalNeural Network, CNN)[40]相继引起人们的极大兴趣。
应用:日益重要的智能应用
随着技术的发展,应用发生了重大的变化,比如并行计算过去常常被狭隘地理解为科学计算,但近年来出现的一些复杂的云服务应用和移动终端上的智能处理应用,如音乐和语音识别(如Shazam和Siri)、图像/视频分析(图像/视频的自动文本标记,如Picasa和Flickr)、在线导航(如谷歌、必应和百度地图)等,对计算能力和能效提出了很高的要求。2005年,英特尔将其归纳为RMS(recognition-mining-synthesis,识别-发掘-综合)应用[21],如人脸识别、数据挖掘、图像合成等。其后英特尔联合普林斯顿大学推出了并行基准测试程序集PARSEC![[8]](http://static.oschina.net/uploads/img/201507/15162918_Hbdx.gif "[8]") ,其中大部分是RMS类应用。大部分RMS应用均基于分类、聚合、近似或优化算法。随着智能应用地位的日益提升,能显著提升智能处理速度、降低智能处理能耗的神经网络处理器自然成为业界关注的焦点。
,其中大部分是RMS类应用。大部分RMS应用均基于分类、聚合、近似或优化算法。随着智能应用地位的日益提升,能显著提升智能处理速度、降低智能处理能耗的神经网络处理器自然成为业界关注的焦点。
神经网络硬件发展现状
随着新的神经网络模型的不断提出,硬件设计技术的不断更新,神经网络硬件也越来越难以单纯的标准划分出具有实际意义的分类。从弗林(Flynn)[27]
在1972年提出的单指令流单数据流(SISD)、单指令流多数据流(SIMD)、多指令流单数据流(MISD)、多指令流多数据流(MIMD)的分类方法,到保罗(Paolo Ienne)[32] 在1995年提出的基于灵活性和性能进行串并行的分类方案,伊斯克·阿贝(Isik Aybay)在1996年提出的多属性分类(片上/片外、数字/模拟/
混合等)方案![[6]](http://static.oschina.net/uploads/img/201507/15162918_UyGZ.gif "[6]") ,再到伊布杜詹恩(Izeboudjen)在2014年提出的更加偏向体系结构的分类方案[33],研究人员一直在努力将现有的神经网络硬件纳入一个清晰的体系。迪亚斯(Dias)在2004年总结了之前多年商业化的硬件神经网络[18]。米斯拉(Misra)等人在2010年调研了从20世纪90年代起近20年的硬件神经网络[49]。
,再到伊布杜詹恩(Izeboudjen)在2014年提出的更加偏向体系结构的分类方案[33],研究人员一直在努力将现有的神经网络硬件纳入一个清晰的体系。迪亚斯(Dias)在2004年总结了之前多年商业化的硬件神经网络[18]。米斯拉(Misra)等人在2010年调研了从20世纪90年代起近20年的硬件神经网络[49]。
在本文中,我们的目的不是探讨如何将神经网络硬件分类,而是展示神经网络硬件在近几年的发展成果。
面向机器学习的人工神经网络硬件
以机器学习相关任务为加速目的的研究多集中在多层感知器(Multilayer Perceptron, MLP)、深度神经网络、卷积神经网络。这三种网络具有相似的结构,在很多场景下具有很好的精度表现,应用也极为广泛。多层感知器的每一层都基本相同,将输入和相应权值相乘的结果相加,通过激活函数(如sigmoid(x)和tanh(x))后,从最后一层获得输出结果。典型的深度神经网络和卷积神经网络具有卷积层、降采样层(pooling)和分类层。最近又提出了归一化层,常见的有局部对比度归一化(LocalContrast Normalization, LCN)[34]和局部响应归一化(LocalResponse Normalization, LRN)[37]。近几年的发展趋势是网络(尤其是深度学习所用到的神经网络)越来越大,模型中的参数越来越多,数据也越来越多。
CPU
这里当属谷歌的深度学习模型最有影响力。谷歌2012年左右在非常大的图像数据集上训练深度学习模型[65]。该模型具有10亿个神经元连接,数据集采用从网络上下载的1000万幅200×200大小的图片,在1000台16个核的机器上训练了3天。该模型在ImageNet数据集上识别22000个物体的准确率达到15.8%。
GPU
图形处理器(GPU)能够提供强大并行计算能力的特性,这使其成为神经网络硬件加速平台的首选。欧(Oh)等人[52]早在2004年就已经通过将点积转化为矩阵操作,用以在GPU上加速神经网络。科茨(Coates)等人[15]的论文提出,GPU可以加速到90倍以上。GPU的流行促使出现了大量深度学习的软件框架,包括Caffe[35]、Theano![[7]](http://static.oschina.net/uploads/img/201507/15162918_2xbl.gif "[7]") 、Torch
、Torch![[3]](http://static.oschina.net/uploads/img/201507/15162918_kWBs.gif "[3]") 、Cuda-convnet
、Cuda-convnet![[4]](http://static.oschina.net/uploads/img/201507/15162918_qg3S.gif "[4]") 。而英伟达公司(NVIDIA)也推出了自己的深度学习库来配合以上各种框架
。而英伟达公司(NVIDIA)也推出了自己的深度学习库来配合以上各种框架![[2]](http://static.oschina.net/uploads/img/201507/15162918_raMo.gif "[2]") ,最大可以加速30%。百度公司目前已构建了世界上规模最大的人工神经网络模型。
,最大可以加速30%。百度公司目前已构建了世界上规模最大的人工神经网络模型。
FPGA
现场可编程门阵列(FPGA)的优点在于可以快速进行硬件的功能验证和评估,加快完成设计的迭代速度。但和专用集成电路(Application Specific Integrated Circuit, ASIC)相比,FPGA相对低效,这也限制了FPGA的应用范围。文献[53, 61]等在FPGA平台上开展了很多神经网络硬件的研究工作。云(Yun)等人[68]在2002年提出了基于传统单指令流多数据流结构的ERNA结构,在FPGA上实现了256-32-5(输入层有256个神经元、隐藏层有32个神经元、输出层有5个神经元)的多层感知器和反向传播训练算法。
与深度神经网络相比,卷积神经网络的一大特性是卷积层占很大的运算量,而运算中的核(kernel)是被每对输入输出特征图像所共享的,这样使得卷积神经网络的权值总量远远低于同样大小的深度神经网络。共享核的特性也使得每个输出特征图像上的神经元所需要的输入图像上的神经元是重叠的。卷积核在输入图像上滑动,与相应区域的输入神经元进行卷积运算后得到输出神经元(加上bias偏置和激活函数)。法拉贝特(Farabet)等人[26]基于FPGA实现了卷积神经网络处理器(Convolutional Network Processor, CNP)。基于卷积神经网络处理器的人脸检测系统可以以10帧/秒的速度处理大小为512×384的视频图像。法拉贝特等人[25]在2011年提出并在2012年[55]开发了一种运行时可重构数据流处理器NeuFlow,并在Xilinx Virtex 6 FPGA上实现。实时处理测试表明,这种实现方式的加速比高出CPU 100倍,功耗在10W左右。桑卡拉达斯(Sankaradas)等人[57]在2009年用FPGA加速了卷积神经网络。卷积运算被重点关注,实现了多个k×k的卷积核运算单元和相应的降采样非线性函数,片外存储和大带宽的数据连接用来保证运算的数据供应。然而卷积核的大小非常不灵活。查克拉哈(Chakradhar)等人[11]在2010年采用systolic-like结构在200MHz的FPGA上实现了卷积神经网络协处理器,来实时处理VGA(640×480)视频图像(25~30的帧率)。佩曼(Peemen)等人[54]在2013年利用卷积神经网络的计算特性实现了卷积神经网络协处理器。其中,MicroBlaze作为主控处理器实现卷积神经网络特殊的数据需求,计算单元PE与单指令流多数据流的结构类似。与使用传统的高速暂存存储器(scratchpadmemory)的FPGA实现的处理器相比,利用卷积神经网络特性实现的处理器的资源开销是前者的1/13。
ASIC
采用自定制电路可以给予设计者最大的自由度去实现设计,同时硬件设计的取舍也很大程度上取决于设计者本身。菲姆(Pham)等人利用IBM的45nmSOI工艺库对NeuFlow[55]进行了评估,认为如果将NeuFlow实现为专用集成电路,其性能功耗比将达到490 GOPs/W1,远大于FPGA实现的14.7 GOPs/W和GPU的1.8 GOPs/W。
ASIC可以采用数字电路、模拟电路或者混合设计。最早的模拟芯片如英特尔的ETANN[30],包含64个全连接的神经元和10240个权值连接。随后有很多在ETANN上的尝试,如Mod2Neurocomputer[50]将12个ETANN连接,实时处理图像。刘(Liu)等人[44]
在2002年展示了包含前向通路与实时错误处理的CMOS2芯片,采用了Orbit2um的N-well工艺。早期也有大量工作采用了模拟电路。文献[42]等采用模拟数字混合电路实现神经网络硬件,这些工作中,或者输入是模拟的,或者计算操作是模拟的。模拟电路的问题在于精度难以控制,表示数据范围极为有限,且实现依赖设计人员的经验。数字芯片则不然,数字芯片这些年统治了芯片行业的发展。Micro Devices的MD1220[16]是第一款商用数字芯片。埃舍梅尔扎德(Esmaeilzadeh)在2010年提出了采用近似运算的硬件多层感知器的神经网络流处理器NnSP[24]。特曼(Temam)[63]在2012年报告了有一定容错能力的硬件多层感知器。子东(Zidong)[20]等人研究实现了非精确硬件神经网络。笔者所在的课题组近年来在这方面的一系列工作也得到了国际上的关注。
生物启发的脉冲神经网络硬件
尽管生物启发的神经网络很贴近真实的神经元细胞,但是它在机器学习任务上的低精度使其一直在工业界得不到应用。卷积神经网络方向的巨擘勒坎(LeCun)就曾经发表过类似的观点![[5]](http://static.oschina.net/uploads/img/201507/15162918_4Jov.gif "[5]") :“他们寄希望于复制我们所知晓的神经元和神经突触的所有细节,然后在一台超级计算机上模拟巨大神经网络,从而产生人工智能,这是幻想。”然而,很多研究人员仍然认为贴近生物特征的神经网络才是构建真正强人工智能的基石(而不是传统的机器学习类的人工神经网络)。
:“他们寄希望于复制我们所知晓的神经元和神经突触的所有细节,然后在一台超级计算机上模拟巨大神经网络,从而产生人工智能,这是幻想。”然而,很多研究人员仍然认为贴近生物特征的神经网络才是构建真正强人工智能的基石(而不是传统的机器学习类的人工神经网络)。
脉冲放电是生物启发的神经网络里通用的概念。单个输入刺激所携带的信息通过一连串的脉冲传递到后续神经元。这样的编码方式通常分为两类(并没有清晰的定义),一类是将信息编码在脉冲的放电频率上,即频率编码(rate coding),这是研究多年的工作方式;另一类是强调单个脉冲放电的精确时间,即时间编码(temporal coding),它的难度也是不言而喻的。格斯特纳(Gerstner)[28]和索普(Thorpe)[64]在近些年提出了一些方法。究竟哪种编码方式更优?学术界一直争论不断。这也显示出我们对大脑工作机制的无知。
在硬件实现上,有一类研究是采用新兴的忆阻器(memristor)来实现神经网络的构建[51, 62]。奎瑞利兹(Querilioz)等人所用的模型是MNIST测试集上精度最高的脉冲神经网络模型[56]。李(Lee)[41]等人采用了CMOSCrossNet结构。埃依曼兹(Eryilmaz)等人![[22]](http://static.oschina.net/uploads/img/201507/15162918_lvoQ.gif "[22]") 专门研究了采用非易失性存储器学习问题。史密斯(Smith)在2014年研究了如何采用硬件(数字电路)高效地实现不同的LIF神经元模型[60]。沃格尔斯坦(Vogelstein)等人[67]比较了不同的神经元模型的模拟实现。作为BrainScale项目的一部分,舍梅尔(Schemmel)[58]调查了Wafer-scale的脉冲神经网络。SpiNNaker[36]实现了10亿个神经元。
专门研究了采用非易失性存储器学习问题。史密斯(Smith)在2014年研究了如何采用硬件(数字电路)高效地实现不同的LIF神经元模型[60]。沃格尔斯坦(Vogelstein)等人[67]比较了不同的神经元模型的模拟实现。作为BrainScale项目的一部分,舍梅尔(Schemmel)[58]调查了Wafer-scale的脉冲神经网络。SpiNNaker[36]实现了10亿个神经元。
近年来,生物启发的脉冲神经网络芯片方面引人瞩目的进展是IBM的SyNAPSE项目。2011年,塞欧(Seo)等人[59]提出了45nm的CMOS芯片;卡西迪(Cassidy)等人[10]提出了针对生物神经芯片的数字神经元模型实现方案;梅罗拉(Merolla)等人[47]提出了采用Crossbar结构的数字芯片,单个脉冲的能耗是45pJ。2014年,IBM发布了TrueNorth芯片[48](如图1所示)。TrueNorth的每个核都采用了Crossbar结构的静态随机存储器(SRAM),拥有256个输入神经元、256个输出神经元。每个芯片拥有4096个芯片核,总计100万个神经元,2.56亿个权值连接,共计采用54亿个晶体管。单个芯片平均放电频率为20Hz,单个神经元放电功耗低至26pJ,功耗低至65mW,远远低于传统芯片。IBM表示,将多个TrueNorth芯片连接起来可以提供更加强大的脉冲神经网络处理能力。
TrueNorth从推出伊始就充满了争议,如勒坎表示“尽管文章令人印象深刻,但实际上没有实现任何有价值的东西”。Neuflow的作者卡伦西罗(Culurciello)表示“从计算性能功耗比的角度讲,和一般的数字芯片相比,TrueNorth并没有优势3,反而处于劣势地位”[17]。然而从学科发展的角度讲,我们认为TrueNorth显示了神经网络硬件潜在的优势,使得神经网络硬件受到更多的关注。
寒武纪系列神经网络处理器
我是一名计算机体系结构研究者,而我所在课题组(体系结构国家重点实验室未来计算课题组)的陈天石博士,他的研究背景是人工智能。于是,我们从2008年开始走上了体系结构和人工智能交叉研究的道路,探索神经网络硬件。最初,研究推进难度很大,进展速度并不快。很多前辈都提到过,交叉领域的研究要得到认可并不容易,要做很多“培育”性质的工作,例如让体系结构领域的研究者认识到人工智能的重要性。2012年陈天石等人提出的国际上首个人工神经网络硬件的基准测试集benchNN就是一个代表[12]。我们发现,体系结构领域经典的测试集PARSEC中的大部分程序都是分类、聚类、逼近、优化、滤波等应用,非常适合神经网络算法。BenchNN利用人工神经网络算法对PARSEC的核心代码进行了重构(如图2所示)。这项工作提升了人工神经网络处理速度,有效加速了通用计算,因而获得了IISWC’12 (IEEE International Symposium onWorkload Characterization)的最佳论文提名奖,有力地推动了国际体系结构学术圈对神经网络的接纳。
局面打开之后,我们课题组立即推出了一系列寒武纪神经网络专用处理器4。当前寒武纪系列已包含三种处理器结构:DianNao(面向多种人工神经网络的原型处理器结构)[13]、DaDianNao(面向大规模人工神经网络)[14]和PuDianNao(面向多种机器学习算法)[43],如表1所示。在即将到来的2015 ACM/IEEE计算机体系结构国际会议(ACM/IEEEInternational Symposium on Computer Architecture, ISCA 2015)上,我们还将发布第四种结构:面向卷积神经网络的ShiDianNao[19] 。这一系列工作在2014年两获CCF推荐A类国际学术会议的最佳论文奖,并被《美国计算机学会通讯》(Communications of the ACM)遴选为研究亮点(researchhighlights)。
寒武纪1号:DianNao
陈天石等人提出的DianNao是寒武纪系列的第一个原型处理器结构[13],包含一个处理器核,主频为0.98GHz,峰值性能达每秒4520亿次神经网络基本运算(如加法、乘法等),65nm工艺下功耗为0.485W,面积3.02mm2(如图3所示)。在若干代表性神经网络上的实验结果表明,DianNao的平均性能超过主流CPU核的100倍,面积和功耗仅为CPU核的1/30~1/5,效能提升达三个数量级;DianNao的平均性能与主流通用图形处理器(NVIDIA K20M)相当,但面积和功耗仅为后者的百分之一量级。
DianNao要解决的核心问题是如何使有限的内存带宽满足运算功能部件的需求,使运算和访存之间达到平衡,从而实现高效能比。其难点在于选取运算功能部件的数量、组织策略以及片上随机存储器(RAM)的结构参数。由于整个结构参数空间有上千万种选择,而模拟器运行速度不及真实芯片的十万分之一,我们不可能蛮力尝试各种可能的设计参数。为解决此问题,我们提出了一套基于机器学习的处理器性能建模方法,并基于该模型最终为DianNao选定了各项设计参数,在运算和访存间实现了平衡,显著提升了执行神经网络算法时的效能。
即使数据已经从内存移到了片上,搬运的能耗依然非常高。英伟达公司首席科学家史蒂夫·凯科勒(SteveKeckler)曾经指出,在40nm工艺下,将64位数据搬运20毫米的能耗是做64位浮点乘法的数倍。因此,要降低处理器功耗,仅仅降低运算功耗是不够的,必须对片上数据搬运进行优化。我们提出了对神经网络进行分块处理,将不同类型的数据块存放在不同的片上随机存储器中,并建立理论模型来刻画随机存储器与随机存储器、随机存储器与运算部件、随机存储器与内存之间的搬运次数,进而优化神经网络运算所需的数据搬运次数。相对于CPU/GPU上基于缓存层次的数据搬运,DianNao可将数据搬运次数减少至前者的1/30~1/10。
寒武纪2号:DaDianNao
近年来兴起的深度神经网络在模式识别领域取得了很好的应用效果,但这类神经网络的隐层数量和突触数量远多于传统神经网络。例如,著名的谷歌大脑包括了100多亿个突触。百度采用的大规模深度学习神经网络包含200多亿个突触。急剧增长的神经网络规模给神经网络处理器带来了挑战。单个核已经难以满足不断增长的应用需求。将神经网络处理器扩展至多核成为自然之选。DaDianNao在DianNao的基础上进一步扩大了处理器的规模,包含16个处理器核和更大的片上存储(如图4所示),并支持多处理器芯片间直接高速互连,避免了高昂的内存访问开销。在28nm工艺下,DaDianNao的主频为606MHz,面积67.7 mm2,功耗约16W。单芯片性能超过了主流GPU 的21倍,而能耗仅为主流GPU的1/330。64芯片组成的计算系统的性能较主流GPU提升450倍,但总能耗仅为后者的1/150。
寒武纪3号:PuDianNao
神经网络已成为模式识别等领域的主流算法,但用户很多时候可能更倾向于使用其他一些经典的机器学习算法。例如程序化交易中经常使用线性回归这类可解释性好、复杂度低的算法。在此背景下,我们研发了寒武纪3号多用途机器学习处理器——PuDianNao[43],可支持k-最近邻、k-均值、朴素贝叶斯、线性回归、支持向量机、决策树、神经网络等近10种代表性机器学习算法。在65nm工艺下,PuDianNao的主频为1GHz,峰值性能达每秒10560亿次基本操作,面积3.51 mm2,功耗为0.596W。PuDianNao运行上述机器学习算法时的平均性能与主流通用图形处理器相当,但面积和功耗仅为后者的百分之一量级。PuDianNao的结构设计主要有两个难点:运算单元设计和存储层次设计,分别对应于机器学习的运算特征和结构特征。其中运算单元设计的出发点是高效实现机器学习最频繁的运算操作,而存储层次设计则主要根据访存特征提高各机器学习算法中数据的片内重用,降低片外访存带宽的需求,充分发挥运算单元的计算能力,避免片外访存成为性能瓶颈。在运算单元设计方面,我们提出了一种机器学习运算单元(Machine Learning Unit, MLU)来支持各种机器学习方法中共有的核心运算,包括:点积(线性回归、支持向量机、神经网络)、距离计算(k-最近邻、k-均值)、计数(决策树和朴素贝叶斯)、排序(k-最近邻、k-均值)和非线性函数计算(支持向量机和神经网络)等。机器学习运算单元被分成了计数器、加法器、乘法器、加法树、Acc和Misc 6个流水线阶段,如图5所示。
在存储层次设计方面,我们设计了HotBuf(HB)、ColdBuf (CB)和OutputBuf(OB) 3个片上数据缓存(见图6)。HotBuf存储输入数据,具有最短重用距离的数据。ColdBuf存放相对较长重用距离的输入数据。OutputBuf存储输出数据或者临时结果。这样设计的原因有两个:第一,在各种机器学习算法中,数据的重用距离通常可以分为两类或三类,因此设计了3个片上数据缓存;第二,机器学习算法中不同类型的数据读取宽度不同,因此设置了分开的缓存来降低不同的宽度带来的开销。
类脑硬件未来之路
不同流派的神经网络硬件在目标、手段和方法上都存在很大差别。但是选择哪条道路更好?我想分享一下自己的一些看法。
从短期(3~5年)来看,基于传统CMOS的人工神经网络硬件加速器是一种比较稳健的选择。从算法研究的现状看,面向机器学习的人工神经网络在所有认知应用上的精度几乎都显著超过了同等规模的生物启发的脉冲神经网络。前者已经开始部署在不同类型的互联网应用上(图像、语音和文本的智能处理),而后者几乎没有得到工业应用。从一个硬件设计者的角度看,硬件的设计应该是算法驱动的。要想让硬件有生命力,什么算法效果好、用途广,硬件就应该支持什么算法。传统CMOS工艺是最稳定成熟的,适合短期内的硬件开发。忆阻器这样的新型器件所需要的工艺复杂,距离大规模实用化开发还有很长的路要走。如果把目标定得过高过远,可能会给这个领域的发展带来很大的风险。
从中期(5~10年)来看,可能会出现面向机器学习的人工神经网络硬件和生物启发的脉冲神经网络硬件并存的情况。这些年以深度学习为代表的人工神经网络非常热门,但是它有应用上的局限性。在没有高层次语义层面指导的情况下,很多图像识别问题是深度学习难以解决的。最近12306网站新推出的图片验证码就可能是这样一类的问题。例如,它会询问一组图片中哪些是开心果,而这些图片中有的是一颗开心果果仁,有的则是装在一个食品包装袋中的没剥开的开心果。我认为,没有高层次语义层面的指导(去壳的和带壳的都是开心果),现有的深度学习技术几乎无法通过逐层的特征提取来把这两个不同的开心果图片识别出来。所以深度学习技术的发展可能会遇到瓶颈。另一方面,通过学术界的深入研究,生物启发的脉冲神经网络在5~10年内在精度问题上有可能会取得一定的突破(达到或接近深度学习的精度)。一旦如此,脉冲神经网络的优势就会充分发挥出来。脉冲神经网络硬件有很强的异步性,很多时候整个硬件中只有一小部分电路需要翻转,能耗会远远低于人工神经网络硬件。如果适合脉冲神经网络硬件的忆阻器的工艺成熟,脉冲神经网络硬件的能耗优势会进一步扩大。到那时,在很多极端看重低能耗的设备(如可穿戴设备)上,生物启发的脉冲神经网络硬件有可能发挥重要的作用。
在更遥远的未来,神经网络硬件可能会在迈向强人工智能的路上起到比较重要的作用。真正的生物神经网络是和计算机科学家正在研究的人工神经网络乃至脉冲神经网络有极大的差别。计算机科学家所关心的神经网络是对生物神经网络进行的某种抽象。究竟什么样的抽象能保证神经网络支撑或者涌现强人工智能?对此谁心里也没有底。脉冲神经网络相对人工神经网络更接近生物,因为它能更多地体现神经元放电的时域信息,但是它也把很多分子、离子层面的信息过滤掉了,而这些信息绝非无足轻重。例如,生物学上常用于描述神经元的霍奇金-赫克斯利(Hodgkin-Huxley)方程(相关工作获得了诺贝尔奖)就对神经元离子层面上的行为进行了建模。没有人知道高级智能的涌现是否依赖于某种离子或者分子(或者基因)层面上的基本规律。所以,到底哪种神经网络硬件会胜出,很大程度上取决于我们对大脑的理解有多深刻。这也是为什么会有一些生物学家对类脑计算提出质疑。毕竟生物学对脑、神经环路以及神经元细胞的理解还不透彻,如何借鉴人脑进行计算自然会存在争议。
不是结论
深度学习的出现直接推动神经网络进入新的发展高峰期。同时,类脑计划也在各个国家火热开展。这一切,无论是希望能够高效地完成机器学习任务,还是朝着终极的强人工智能前进,神经网络硬件在提升计算能力的同时也在推进着模型的发展,这都将有力地促进相关学科的发展。■
作者

陈云霁
CCF会员,2014 CCF青年科学家奖获得者。中国科学院计算技术研究所研究员。主要研究方向为计算机体系结构、集成电路设计和机器学习。cyj@ict.ac.cn
脚注:
1GOPS: Giga Operations Per Second,每秒10亿运算数。
2CMOS: Complementary Metal Oxide Semiconductor,互补金属氧化物半导体。
3卡伦西罗之所以认为TrueNorth功耗低,仅仅是因为它的频率(平均放电频率20Hz)比主流硬件(一般可达到1~3GHz)低约一亿倍。
4寒武纪是生命爆炸性发展的时代,各种现代动物的祖先纷纷登场。我们给自己的项目起这个名字,是希望21世纪成为智能爆炸性发展的时代。
图:

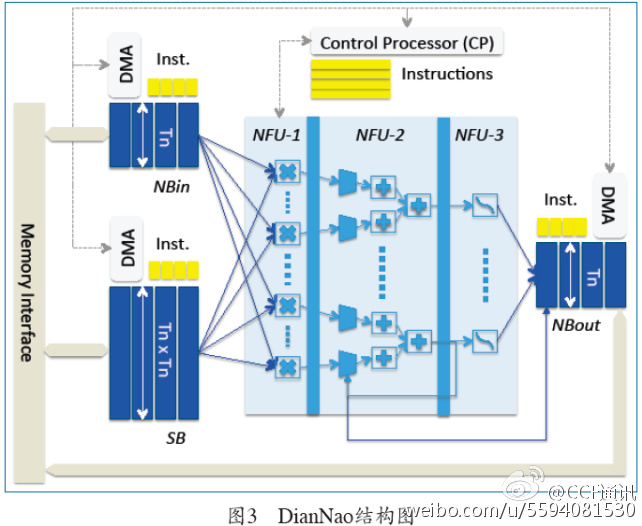



表:
 参考文献:
参考文献:
Making the move to quad-core and beyond.Technology@Intel Magazine, 2006.
Cudnn: Gpu-accelerated library of primitivesfor deep neural networks. https://developer.nvidia.com/cuDNN.
Torch: a matlab-like environment forstate-of-the-art machine learning algorithms in lua. http://torch.ch/.
Cuda-convnet2: A fast c++/cuda implementationof convolutional (or more generally, feedforward) neural networks.https://code.google.com/p/cuda-convnet2/.
IEEE spectrum: Facebook AI director yann lecunon his quest to unleash deep learning and make machines smarter.http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/facebook-ai-director-yann-lecun-on-deep-learning,2015.
Halici UgurAybay Isik, Cetinkaya Semih. Classification of neural network hardware. NeuralNetwork World, 6(9):11~29, 1996.
FrédéricBastien, Pascal Lamblin, Razvan Pascanu, and et al.. Theano: new features andspeed improvements. Deep Learning and Unsupervised Feature Learning NIPS 2012Workshop, 2012.
ChristianBienia, Sanjeev Kumar, Jaswinder Pal Singh, and Kai Li. The PARSEC benchmarksuite: Characterization and architectural implications. In InternationalConference on Parallel Architectures and Compilation Techniques, New York, NewYork, USA, 2008. ACM Press.
Shekhar Borkar and Andrew A. Chien. The futureof microprocessors. Commun. ACM, 2011; 54(5):67~77.
[10]Andrew S. Cassidy, PaulMerolla, John V. Arthur, and et al...Cognitive Computing Building Block: A Versatile and Efficient Digital NeuronModel for Neurosynaptic Cores. Technical report, 2011.
[11]Srimat Chakradhar, MuruganSankaradas, Venkata Jakkula, and Srihari Cadambi. A dynamically congurablecoprocessor for convolutional neural networks. In Proceedings of the 37th annual international symposium on Computerarchitecture - ISCA'10, pages 247~257, Saint-Malo, France., 2010. ACMPress.
[12]TianshiChen, Yunji Chen, Marc Duranton, and et al.. BenchNN: On the Broad PotentialApplication Scope of Hardware Neural Network Accelerators. In InternationalSymposium on Workload Characterization, 2012.
[13]Tianshi Chen, Zidong Du,Ninghui Sun, and et al.. DianNao: a small footprint high-throughput acceleratorfor ubiquitous machine-learning. In Proceedings of the 19th internationalconference on Architectural support for programming languages and operatingsystems - ASPLOS'14, pages 269-284, Salt Lake City, UT, USA, 2014.
[14]YunjiChen, Tao Luo, Shaoli Liu, and et al.. DaDianNao: A Machine-LearningSupercomputer. In Proceedings of the 47th Annual IEEE/ACM InternationalSymposium on Microarchitecture -
MICRO-47, 2014.
[15]Adam Coates, PaulBaumstarck, Quoc Le, and Andrew Y. Ng. Scalable learning for object detectionwith GPU hardware. 2009 IEEE/RSJ International Conference on Intelligent Robotsand Systems, 2009; 10: 4287~4293.
[16]M.D. Corp. Md 1220 neuralbit slice, March 1990.
[17]Eugenio Culurciello.Caculation gops/w about truenorth.https://www.facebook.com/yann.lecun/posts/10152184295832143.
[18]Fernando Morgado Dias, AnaAntunes, and Alexandre Manuel Mota. Articial neural networks: a review ofcommercial hardware. Engineering Applications of Artificial Intelligence,17(8):945-952, December 2004.
[19]Zidong Du, Robert Fasthuber,Tianshi Chen, Paolo Ienne, Ling Li, Tao Luo, Xiaobing Feng, Yunji Chen, andOlivier Temam. Shidiannao: Shifting vision processing closer to the sensor. InProceedings of the 42nd ACM/IEEE International Symposium on ComputerArchitecture (ISCA'15). ACM, 2015.
[20]Zidong Du, AvinashLingamneni, Yunji Chen, Krishna Palem, Olivier Temam, and Chengyong Wu. Leveragingthe error resilience of machine-learning applications for designing highlyenergy efficient accelerators. 2014 19th Asia and South Pacific DesignAutomation Conference (ASP- DAC) , January 2014, 201~206.
[21]P. Dubey. Recognition,mining and synthesis moves computers to the era of tera.http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.114.5768&rep=rep1&type=pdf.
Sukru Burc Eryilmaz,Duygu Kuzum, Rakesh Jeyasingh, Sangbum Kim, Paul G Allen Bx, and Via Palou.Brain-like associative learning using a nanoscale non-volatile phase changesynaptic device array. 1~22.
[23]Hadi Esmaeilzadeh, EmilyBlem, Renee St. Amant, Karthikeyan Sankaralingam, and Doug Burger. Dark siliconand the end of multicore scaling. In Proceeding of the 38th annualinternational symposium on Computer architecture - ISCA'11, pages 365-376, NewYork, New York, USA, 2011. ACM Press.
[24]Hadi Esmaeilzadeh, AdrianSampson, Luis Ceze, and Doug Burger. Neural Acceleration for General-PurposeApproximate Programs. In 2012 45th Annual IEEE/ACM International Symposium onMicroarchitecture, pages 449~460. Ieee, December 2012.
[25]Clement Farabet, BerinMartini, Benoit Corda, Polina Akselrod, Eugenio Culurciello, and Yann LeCun.NeuFlow: A runtime reconfigurable dataflow processor for vision. In IEEEComputer Society Conference on Computer Vision and Pattern RecognitionWorkshops (2011), pages 109~116. Ieee, June 2011.
[26]Clement Farabet, CyrilPoulet, Jeerson Y Han, and Yann Lecun. CNP: An FPGA-based processor forConvolutional Networks. In International Conference on Field Programmable Logicand Applications, 2009. FPL 2009, volume 1, pages 32-37, 2009.
[27]M. Flynn. Some computerorganizations and their effectiveness. Computers, IEEE Transactions on,C-21(9):948~960, Sept 1972.
[28]W Gerstner and WM Kistler.Spiking neuron models: Single neurons, populations, plasticity. 2002.
[29]RehanHameed, Wajahat Qadeer, Megan Wachs, Omid Azizi, Alex Solomatnikov, Benjamin C.Lee, Stephen Richardson, Christos Kozyrakis, and Mark Horowitz. Understandingsources of inefficiency in general-purpose chips. In Proceedings of the 37thannual international symposium on Computer architecture - ISCA'10, page 37, NewYork, New York, USA, 2010. ACM Press.
[30] M. Holler, Simon Tam, H. Castro, and R.Benson. An electrically trainable artificial neural network (etann) with 10240'floating gate' synapses. In Neural Networks, 1989. IJCNN., International JointConference on, pages 191-196 vol.2, 1989.
[31] J J Hopeld. Neural networks and physicalsystems with emergent collective computational abilities. Proceedings of theNational Academy of Sciences, 79(8):2554-2558, 1982.
[32] Paolo Ienne, In f Ecublens, and Gary Kuhn.Digital systems for neural networks. In Digital Signal Processing Technology,volume CR57 of Critical Reviews Series, pages 314-45. SPIE Optical Engineering,pages 314-345, 1995.
[33] N. Izeboudjen, C. Larbes, and a. Farah. A newclassification approach for neural networks hardware: From standards chips toembedded systems on chip. Artificial Intelligence Review, 41(4):491-534, 2014.
[34] Kevin Jarrett, Koray Kavukcuoglu, Marc'Aurelio Ranzato, and Yann LeCun. What is the best multi-stage architecture forobject recognition? 2009 IEEE 12th International Conference on Computer Vision,pages 2146-2153, September 2009.
[35] Yangqing Jia, Evan Shelhamer, Je Donahue,Sergey Karayev, Jonathan Long, Ross Girshick,Sergio Guadarrama, and TrevorDarrell. Caffe: Convolutional architecture for fast feature embedding. arXivpreprint arXiv:1408.5093, 2014.
[36] M. M. Khan, D. R. Lester, L. A. Plana, A.Rast, X. Jin, E. Painkras, and S. B. Furber. SpiNNaker: Mapping Neural Networksonto a Massively-Parallel Chip Multiprocessor. In Proceedings of theInternational Joint Conference on Neural Networks, pages 2849-2856, 2008.
[37] Alex Krizhevsky, Ilya Sutskever, and Georey EHinton. ImageNet Classification with Deep Convolutional Neural Networks.Advances in Neural Information Processing Systems, pages 1-9, 2012.
[38] Samir Kumar. Introducing Qualcomm Zeroth Processors:Brain-Inspired Computing, 2013.
[39] Hugo Larochelle, Dumitru Erhan, AaronCourville, James Bergstra, and Yoshua Bengio. An empirical evaluation of deeparchitectures on problems with many factors of variation. In InternationalConference on Machine Learning, pages 473-480, New York, New York, USA, 2007.ACM Press.
[40] Yann LeCun, Lfn'egon Bottou, Yoshua Bengio,and Patrick Haner. Gradient-Based Learning Applied to Document Recognition.Proceedings of the IEEE, 86(11):2278- 2324, 1998.
[41] Jung Hoon Lee. Scaling-efficient in-situtraining of CMOL CrossNet classifiers. Neural networks: the official journal ofthe International Neural Network Society, 24(10):1136-42, December 2011.
[42] Torsten Lehmann, Erik Bruun, and CasperDietrich. Mixed analog/digital matrix-vector multiplier for neural networksynapses. Analog Integr. Circuits Signal Process., 9(1):55-63, January 1996.
[43] Daofu Liu, Tianshi Chen, Shaoli Liu, JinhongZhou, Shengyuan Zhou, Olivier Temam, Xiaobing Feng, Xuehai Zhou, and Yunji Chen.PuDianNao: A Machine Learning Accelerator. In Proceedings of the 20thinternational conference on Architectural support for programming languages andoperating systems, pages 369-381, 2015.
[44] Jin Liu, M.A. Brooke, and K. Hirotsu. A cmosfeedforward neural-network chip with on-chip parallel learning for oscillationcancellation. Neural Networks, IEEE Transactions on, 13(5):1178-1186, Sep 2002.
[45] Wolfgang Maass. Networks of spiking neurons:The third generation of neural network models. Neural Networks,10(9):1659-1671, December 1997.
[46] WarrenS. McCulloch and Walter Pitts. Alogical calculus of the ideas immanent in nervous activity. The bulletin ofmathematical biophysics, 5(4):115-133, 1943.
[47] Paul Merolla, John Arthur, and FilippAkopyan. A digital neurosynaptic core using embedded crossbar memory with 45pJper spike in 45nm. In 2011 IEEE Custom Integrated Circuits Conference (CICC),pages 1-4. Ieee, September 2011.
[48] Paul A Merolla, John V Arthur, RodrigoAlvarez-icaza, Andrew S Cassidy, Jun Sawada, Filipp Akopyan, Bryan L Jackson,Nabil Imam, Chen Guo, Yutaka Nakamura, Bernard Brezzo, Ivan Vo, Steven K Esser,Rathinakumar Appuswamy, Brian Taba, Arnon Amir, Myron D Flickner, William PRisk, Rajit Manohar, and Dharmendra S Modha. A million spiling-neuron interatedcircuit with a scalable communication network and interface. Science,345(6197), 2014.
[49] Janardan Misra and Indranil Saha. Artificialneural networks in hardware: A survey of two decades of progress.Neurocomputing, 74(1-3):239-255, December 2010.
[50] M.L. Mumford, D.K. Andes, and L.R. Kern. Themod 2 neurocomputer system design. Neural Networks, IEEE Transactions on,3(3):423-433, May 1992.
[51] Emre Neftci, Srinjoy Das, Bruno Pedroni,Kenneth Kreutz-delgado, Gert Cauwenberghs, Neural Computation, and La Jolla.Event-driven contrastive divergence for spiking neuromorphic systems. Frontiersin Neuroscience, 7(January):1-14, 2014.
[52] Kyoung-Su Oh and Keechul Jung. GPUimplementation of neural networks. Pattern Recognition, 37(6):1311-1314, June2004.
[53] Ernesto Ordoñez cardenas and Rene De J Romero-troncoso. MLPNeural Network and On-Line Backpropagation Learning Implementation In ALow-Cost FPGA. In Proceedings of the 18th ACM Great Lakes symposium on VLSI,pages 333-338, 2008.
[54] Maurice Peemen, Arnaud a. a. Setio, BartMesman, and Henk Corporaal. Memory-centric accelerator design for ConvolutionalNeural Networks. In International Conference on Computer Design, pages 13-19.Ieee, October 2013.
[55] Phi Hung Pham, Darko Jelaca, Clement Farabet,Berin Martini, Yann LeCun, and Eugenio Culurciello. NeuFlow: Dataflow visionprocessing system-on-a-chip. In Midwest Symposium on Circuits and Systems,pages 1044-1047, 2012.
[56] Damien Querlioz, Olivier Bichler, PhilippeDollfus, and Christian Gamrat. Immunity to Device Variations in a SpikingNeural Network with Memristive Nanodevices. IEEE Transactions onNanotechnology, 12(3):288-295, May 2013.
[57] Murugan Sankaradas, Venkata Jakkula, SrihariCadambi, Srimat Chakradhar, Igor Durdanovic, Eric Cosatto, and Hans Peter Graf.A Massively Parallel Coprocessor for Convolutional Neural Networks. In 200920th IEEE International Conference on Application-specific Systems,Architectures and Processors, pages 53-60. Ieee, July 2009.
[58] Johannes Schemmel, Daniel Bruderle, AndreasGrubl, Matthias Hock, Karlheinz Meier, and Sebastian Millner. AWafer-ScaleNeuromorphic Hardware System for Large-Scale Neural Modeling. In IEEEInternational Symposium on Circuits and Systems: Nano-Bio Circuit Fabrics andSystems, pages 1947-1950, 2010.
[59] Jae-sun Seo, Bernard Brezzo, Yong Liu,BenjaminD. Parker, Steven K. Esser, Robert K. Montoye, Bipin Rajendran, Jose a.Tierno, Leland Chang, Dharmendra S. Modha, and Daniel J. Friedman. A 45nm CMOSneuromorphic chip with a scalable architecture for learning in networks ofspiking neurons. In 2011 IEEE Custom Integrated Circuits Conference (CICC),pages 1-4. Ieee, September 2011.
[60] James E. Smith. Efficient digital neurons forlarge scale cortical architectures. In 2014 ACM/IEEE 41st InternationalSymposium on Computer Architecture (ISCA), pages 229-240. Ieee, June 2014.
[61] JA Starzyk, Y Guo, and Z Zhu. Dynamicallyreconfigurable neuron architecture for the implementation of self-organisinglearning array. In International Journal of Embedded Systems, pages 4-7, 2006.
[62] Tianqi Tang, Lixue Xia, Boxun Li, Rong Luo,Yiran Chen, YuWang, and Huazhong Yang. Spiking Neural Network with RRAM: Can WeUse It for Real-World Application? In Proceedings of Design, Automation&Test in Europe, DATE 2015, 2015.
[63] Olivier Temam. A defect-tolerant acceleratorfor emerging high-performance applications. In Proceedings of the 39th AnnualInternational Symposium on Computer Architecture (ISCA'12), volume 00, pages356-367, 2012.
[64] Simon Thorpe and Jacques Gautrais. Rank ordercoding. Computational neuroscience: Trends in Research, 13:113-119, 1998.
[65] Vincent Vanhoucke, Andrew Senior, and Mark ZMao. Improving the speed of neural networks on CPUs. In Deep Learning and UnsupervisedFeature Learning Workshop, NIPS 2011, 2011.
[66] Ganesh Venkatesh, Jack Sampson, NathanGoulding-hotta, Sravanthi Kota Venkata, Michael Bedford Taylor, and StevenSwanson. QSCORES: Trading Dark Silicon for Scalable Energy Efficiency withQuasi-Specific Cores Categories and Subject Descriptors. In Proceedings of the44th Annual IEEE/ACM International Symposium on Microarchitecture - MICRO-44'11, pages 163-174, 2011.
[67] R Jacob Vogelstein, Udayan Mallik, Joshua TVogelstein, and Gert Cauwenberghs. Dynamically reconfigurable silicon array ofspiking neurons with conductance-based synapses. IEEE Transactions on NeuralNetworks, 18(1):253-265, 2007.
[68] Seok Bae Yun, Young Joo Kim, Sung So Dong,and Chong Ho Lee. Hardware implementation of neural network with expansible andREcongfigurable architecture. In Proceedings of 9th International Conference onNeural Information Processing, volume 2, pages 970-975, 2002.















 2685
2685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









