







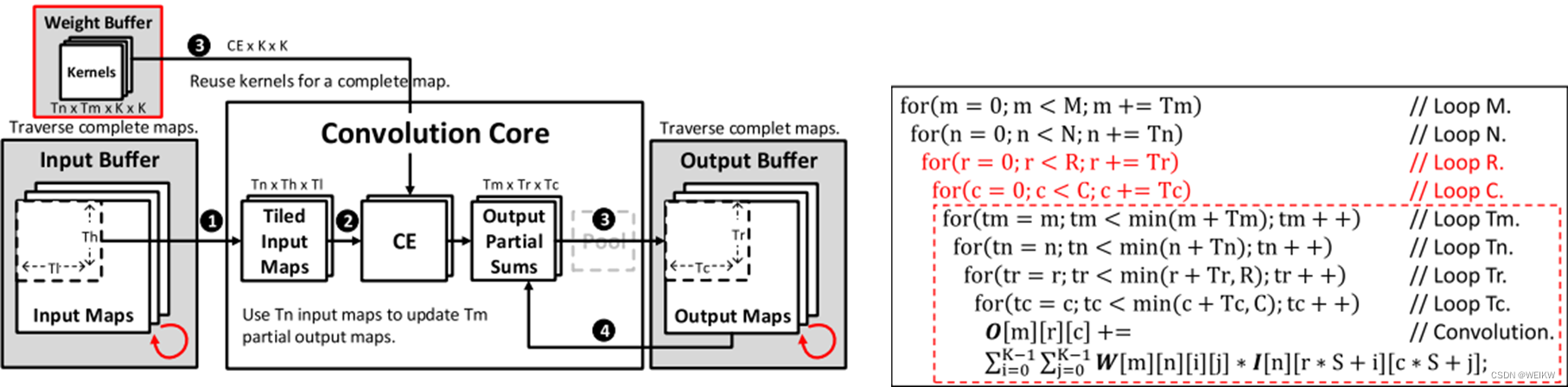
一 基本网络层数学模型
输入特征图尺寸为N*H*L,卷积计算通过M个尺寸为K*K*N的3维卷积核完成,每个卷积核在输入特征图上以S为步长滑动并进行3维卷积计算,最终生成尺寸为R*C*M的输出特征图。
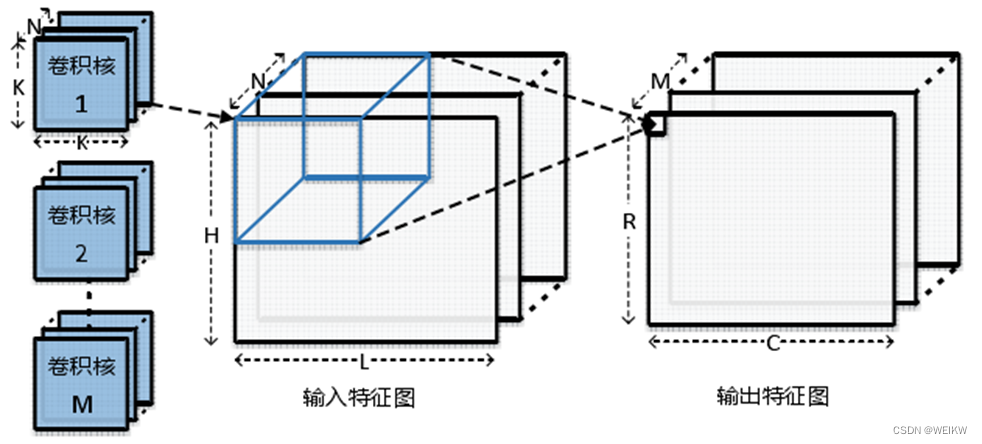
CNN中的卷积层计算
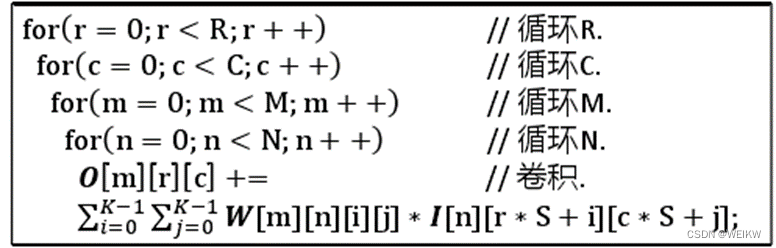
卷积层计算伪代码
二 数据复用
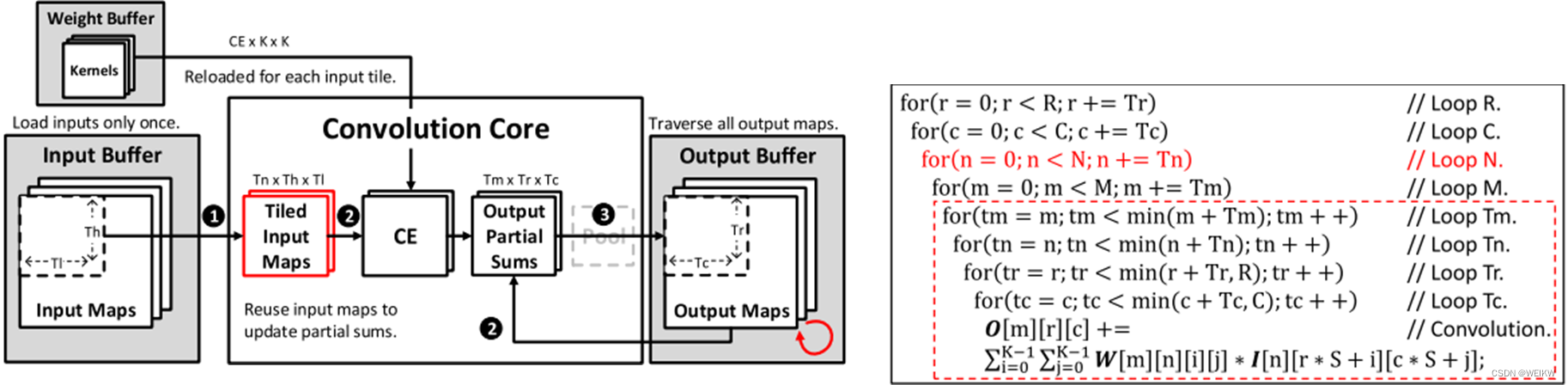
1、输入数据复用
输入数据复用对输入缓存具有最少的访问次数,其分为3个步骤:①计算核心把输入特征图读入局部输入寄存器;②计算核心充分复用这些输入数据,更新输出缓存中的所有相关的输出部分和;③更新后的输出部分和会重新写会输出缓存。当新的输入数据被读入计算核心时会重复上述3个步骤。
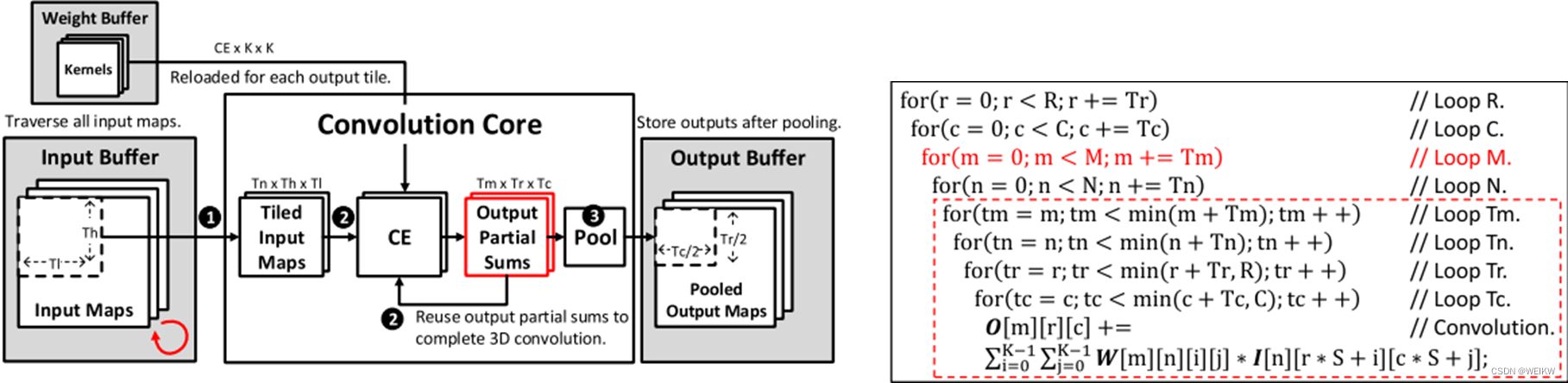
2、输出数据复用
输出数据复用对输出缓存具有最少的访问次数,其分为3个步骤:①计算核心把输入特征图的各通道读入局部的输入缓存器;②存储在计算核心输出寄存器中的输出部分和会被充分复用,以完成3为卷积通道方向上的完全累加;③最终的输出特征图会在池化之后再写入输出缓存。计算过程中不会再有其他对输出缓存的访问,对于剩余的输出特征图计算,会重复上述3个步骤。
3、权重数据复用
权重数据复用对权重具有最少的访问次数,其分为3个步骤:①计算核心读取Tn个输入特征图分块到局部的输入寄存器;②计算核心利用这些输入数据更新Tm个通道的输出部分和;③存储在权重缓存中的Tm个Tn通道的卷积核权重被充分复用,以更新存储在输出缓存中的Tm个通道的R*C输出部分和。重复上述3个步骤以完成整个卷积层的全部计算。
4、混合数据复用
该数据复用模式,将根据每一层单独分配针对该层最优的数据复用模式。因此涉及寻找最优的数据复用模式,需要探索各种分块参数下的不同模式的访存能耗。
三 并行计算
尽管神经网络中的计算具有很强的可并行性,但是由于受到计算资源和存储资源的限制,往往不能全部同时映射到单个芯片上,因此需要设计一些调度方法将神经网络映射到计算芯片的计算阵列上依次执行。
1、并行计算
探索计算单元PE的并行性,获取高性能。
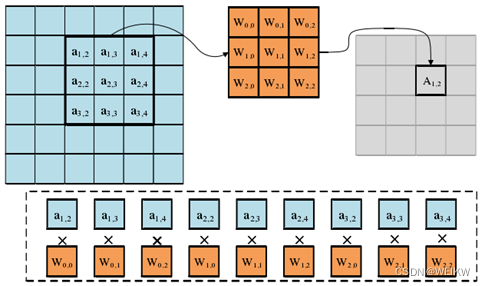
(1)像素并行性
分为卷积窗口内部并行/卷积窗口间并行
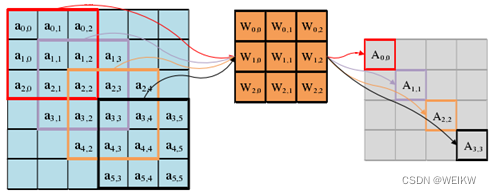
(2)输入通道并行性
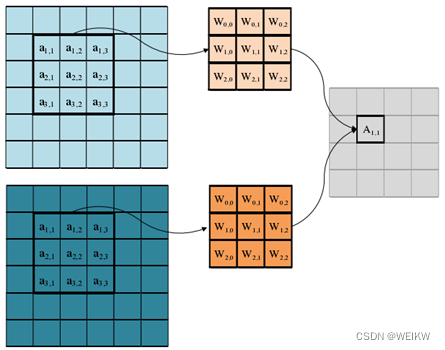
(3)输出并行性
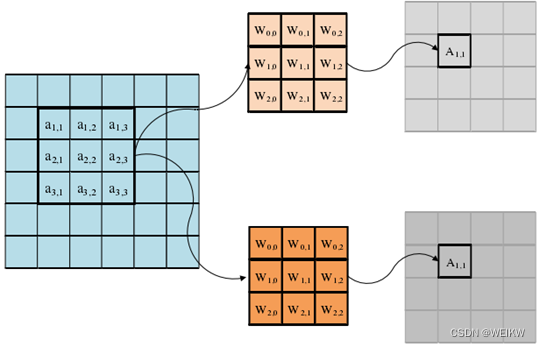
2、循环展开
通过最大化在PE和片上缓存上的数据复用,获取高能效。
对于某个神经网络加速,通常在有限的片外传输带宽限制下,通过高效的数据调度,驱动尽可能多的计算单元,以实现最高的有效吞吐量,同时要利用数据共享的特性,提高数据重用率,尽可能提升NPU吞吐量和能效。
(1)循环交换(Loop Interchange):优化数据复用模式,减少访存次数
(2)循环分块(Loop Tiling):优化卷积映射方法,提高计算资源利用率
为复用输入特征图,卷积核维度循环须在最内层:即要确定R/C/M/N的展开顺序
先计算输出通道循环M:要求更新权重,重利用输入特征图-时间维度复用输入像素
先计算输入通道循环N:要求更新权重和输入像素
先计算输出特征图高R和宽C:要求更新输入像素,重利用权重-时间维度复用权重
四 应用案例分析
待补充















 2028
2028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









