







lucene简介:
摘自百科:Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
lucene开发的步骤:
-
创建索引
-
创建Directory
-
创建IndexWriter
-
创建Document对象
-
为Document添加Field
-
通过IndexWriter添加文档到索引中
-
关闭IndexWriter
搜索
-
创建Directory
-
创建IndexReader
-
根据IndexReader创建IndexSearcher
-
创建搜索的Query
-
根据searcher搜索并返回TopDocs
-
根据topDocs获取ScoreDoc对象
-
根据searcher和StoreDoc对象获取具体的Document对象
-
根据Document对象获取需要的值
-
关闭IndexReader
一个最简单的lucene例子
说明:该例子采用lucene5.3,主要功能就是在硬盘上的3个txt文件里面找到你查询的字符,并打印出文件名和文件路径.
首先,在我的电脑D盘,创建一个文件夹,用来保存lucene检索的文件的地方.然后创建3个文件用来存放字符串,a.txt,b.txt,c.txt,里面分别录入一些字符.下面是我的例子中的图:



接着,我们打开eclipse创建一个maven项目.加入lucene和junit的依赖jar
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.3.1</version>
</dependency>
</dependencies>package com.kkrgwbj.demolucene;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.NoLockFactory;
public class HelloLucene {
/**
* 建立索引
*/
public void index() {
// 1.创建Directory
Directory directory = null;
try {
directory = FSDirectory.open(new File("D:/workspace/lucene/index01").toPath(), NoLockFactory.INSTANCE);// 建立在硬盘
// directory = new RAMDirectory();//建立在内存中
} catch (IOException e1) {
e1.printStackTrace();
}
// 2.创建IndexWriter
IndexWriterConfig ic = new IndexWriterConfig(new StandardAnalyzer());
IndexWriter iw = null;
try {
iw = new IndexWriter(directory, ic);
} catch (IOException e1) {
e1.printStackTrace();
}
try {
// 3.创建Document对象
Document doc = null;
// 4.为Document添加Field
File f = new File("D:/workspace/lucene");
for (File item : f.listFiles()) {
if (item.isDirectory()) {
continue;
}
doc = new Document();
doc.getFields().add(new TextField("content", new FileReader(item)));
doc.getFields().add(new TextField("filename", item.getName(), Field.Store.YES));
doc.getFields().add(new TextField("path", item.getAbsolutePath(), Field.Store.YES));
// 5.通过IndexWriter添加文档到索引中
iw.addDocument(doc);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭
if (iw != null)
try {
iw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 搜索
*/
public void searcher() {
// 1.创建Directory
Directory directory = null;
IndexReader ir = null;
try {
directory = FSDirectory.open(new File("D:/workspace/lucene/index01").toPath());// 建立在硬盘
// directory = new RAMDirectory();//建立在内存中
// 2.创建IndexReader
ir = DirectoryReader.open(directory);
// 3.根据IndexReader创建IndexSearcher
IndexSearcher is = new IndexSearcher(ir);
// 4.创建搜索的Query,创建parser来确定搜索文件的内容,第一个参数表示搜索的域
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
Query query = parser.parse("java");// 搜索含有java内容的文档
// 5.根据searcher搜索并返回TopDocs
TopDocs tds = is.search(query, 10);
// 6.根据topDocs获取ScoreDoc对象
ScoreDoc[] docs = tds.scoreDocs;
for (ScoreDoc scoreDoc : docs) {
// 7.根据searcher和StoreDoc对象获取具体的Document对象
Document d = is.doc(scoreDoc.doc);
// 8.根据Document对象获取需要的值
System.out.println("文件名:" + d.get("filename") + "路径:" + d.get("path"));
}
// 9.关闭reader
ir.close();
} catch (Exception e1) {
e1.printStackTrace();
}
}
}
package com.kkrgwbj.demolucene;
import org.junit.Test;
public class TestLucene {
@Test
public void testIndex() {
HelloLucene hl = new HelloLucene();
hl.index();
}
@Test
public void testSearch(){
HelloLucene hl = new HelloLucene();
hl.searcher();
}
}
首先,执行创建索引.执行完后,我们会发现在index01目录创建索引
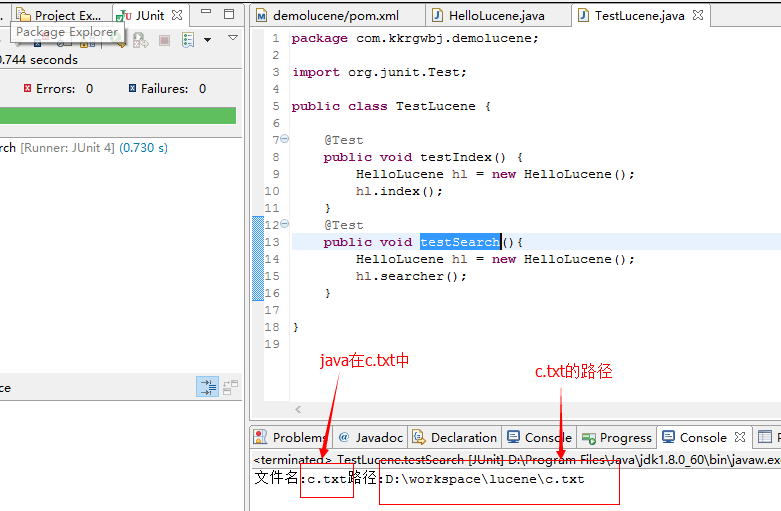
 接下来,我们执行检索,在控制台打印输出a,b,c3个文件中,java出现在哪个文件中,和文件路径
接下来,我们执行检索,在控制台打印输出a,b,c3个文件中,java出现在哪个文件中,和文件路径















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









