







 本文介绍了word2vec词向量的训练过程,详细讲解了从下载源码到运行的步骤,并展示了结果。通过提供的资源,读者可以学习如何利用word2vec进行中文文本相似度计算。
本文介绍了word2vec词向量的训练过程,详细讲解了从下载源码到运行的步骤,并展示了结果。通过提供的资源,读者可以学习如何利用word2vec进行中文文本相似度计算。
本文是讲述如何使用word2vec的基础教程,文章比较基础,希望对你有所帮助!
官网C语言下载地址: http://word2vec.googlecode.com/svn/trunk/
官网Python下载地址: http://radimrehurek.com/gensim/models/word2vec.html
参考:《Word2vec的核心架构及其应用 · 熊富林,邓怡豪,唐晓晟 · 北邮2015年》
《Word2vec的工作原理及应用探究 · 周练 · 西安电子科技大学2014年》
《Word2vec对中文词进行聚类的研究 · 郑文超,徐鹏 · 北京邮电大学2013年》
PS:第一部分主要是给大家引入基础内容作铺垫,这类文章很多,希望大家自己去学习更多更好的基础内容,这篇博客主要是介绍Word2Vec对中文文本的用法。
(1) 统计语言模型
统计语言模型的一般形式是给定已知的一组词,求解下一个词的条件概率。形式如下:
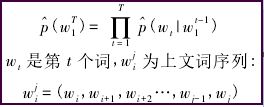
统计语言模型的一般形式直观、准确,n元模型中假设在不改变词语在上下文中的顺序前提下,距离相近的词语关系越近,距离较远的关联度越远,当距离足够远时,词语之间则没有关联度。
但该模型没有完全利用语料的信息:
1) 没有考虑距离更远的词语与当前词的关系,即超出范围n的词被忽略了,而这两者很可能有关系的。
例如,“华盛顿是美国的首都”是当前语句,隔了大于n个词的地方又出现了“北京是中国的首都”,在n元模型中“华盛顿”和“北京”是没有关系的,然而这两个句子却隐含了语法及语义关系,即”华盛顿“和“北京”都是名词,并且分别是美国和中国的首都。
2) 忽略了词语之间的相似性,即上述模型无法考虑词语的语法关系。
例如,语料中的“鱼在水中游”应该能够帮助我们产生“马在草原上跑”这样的句子,因为两个句子中“鱼”和“马”、“水”和“草原”、“游”和“跑”、“中”和“上”具有相同的语法特性。
而在神经网络概率语言模型中,这两种信息将充分利用到。
(2) 神经网络概率语言模型
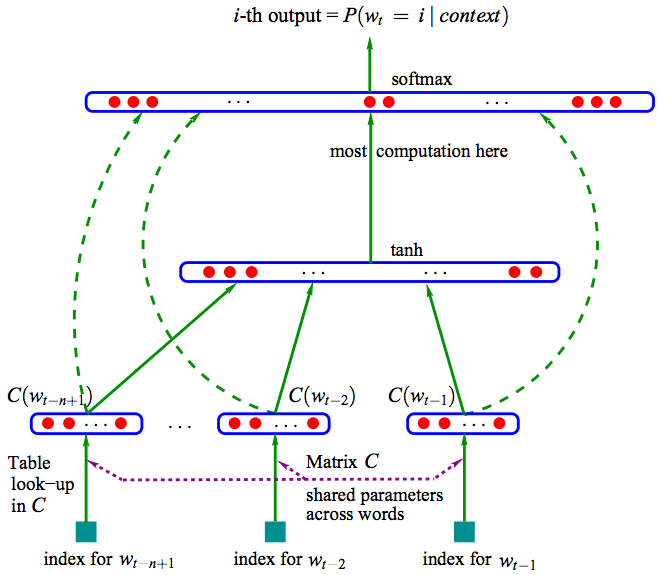
神经网络概率语言模型是一种新兴的自然语言处理算法,该模型通过学习训练语料获取词向量和概率密度函数,词向量是多维实数向量,向量中包含了自然语言中的语义和语法关系,词向量之间余弦距离的大小代表了词语之间关系的远近,词向量的加减运算则是计算机在"遣词造句"。
神经网络概率语言模型经历了很长的发展阶段,由Bengio等人2003年提出的神经网络语言模型NNLM(Neural network language model)最为知名,以后的发展工作都参照此模型进行。历经十余年的研究,神经网络概率语言模型有了很大发展。
如今在架构方面有比NNLM更简单的CBOW模型、Skip-gram模型;其次在训练方面,出现了Hierarchical Softmax算法、负采样算法(Negative Sampling),以及为了减小频繁词对结果准确性和训练速度的影响而引入的欠采样(Subsumpling)技术。
官网C语言下载地址: http://word2vec.googlecode.com/svn/trunk/
官网Python下载地址: http://radimrehurek.com/gensim/models/word2vec.html
1.简单介绍
参考:《Word2vec的核心架构及其应用 · 熊富林,邓怡豪,唐晓晟 · 北邮2015年》
《Word2vec的工作原理及应用探究 · 周练 · 西安电子科技大学2014年》
《Word2vec对中文词进行聚类的研究 · 郑文超,徐鹏 · 北京邮电大学2013年》
PS:第一部分主要是给大家引入基础内容作铺垫,这类文章很多,希望大家自己去学习更多更好的基础内容,这篇博客主要是介绍Word2Vec对中文文本的用法。
(1) 统计语言模型
统计语言模型的一般形式是给定已知的一组词,求解下一个词的条件概率。形式如下:
统计语言模型的一般形式直观、准确,n元模型中假设在不改变词语在上下文中的顺序前提下,距离相近的词语关系越近,距离较远的关联度越远,当距离足够远时,词语之间则没有关联度。
但该模型没有完全利用语料的信息:
1) 没有考虑距离更远的词语与当前词的关系,即超出范围n的词被忽略了,而这两者很可能有关系的。
例如,“华盛顿是美国的首都”是当前语句,隔了大于n个词的地方又出现了“北京是中国的首都”,在n元模型中“华盛顿”和“北京”是没有关系的,然而这两个句子却隐含了语法及语义关系,即”华盛顿“和“北京”都是名词,并且分别是美国和中国的首都。
2) 忽略了词语之间的相似性,即上述模型无法考虑词语的语法关系。
例如,语料中的“鱼在水中游”应该能够帮助我们产生“马在草原上跑”这样的句子,因为两个句子中“鱼”和“马”、“水”和“草原”、“游”和“跑”、“中”和“上”具有相同的语法特性。
而在神经网络概率语言模型中,这两种信息将充分利用到。
(2) 神经网络概率语言模型
神经网络概率语言模型是一种新兴的自然语言处理算法,该模型通过学习训练语料获取词向量和概率密度函数,词向量是多维实数向量,向量中包含了自然语言中的语义和语法关系,词向量之间余弦距离的大小代表了词语之间关系的远近,词向量的加减运算则是计算机在"遣词造句"。
神经网络概率语言模型经历了很长的发展阶段,由Bengio等人2003年提出的神经网络语言模型NNLM(Neural network language model)最为知名,以后的发展工作都参照此模型进行。历经十余年的研究,神经网络概率语言模型有了很大发展。
如今在架构方面有比NNLM更简单的CBOW模型、Skip-gram模型;其次在训练方面,出现了Hierarchical Softmax算法、负采样算法(Negative Sampling),以及为了减小频繁词对结果准确性和训练速度的影响而引入的欠采样(Subsumpling)技术。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2545
2545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









