







SVM支持向量机
1、定义
SVM全称是support vector machine(支持向量机),即寻找一个超平面使样本分成两类,并且间隔最大
SVM能够执行线性或非线性分类、回归、甚至是异常值检测任务。
SVM特别适用于中小型复杂数据集的分类
2、超平面最大间隔
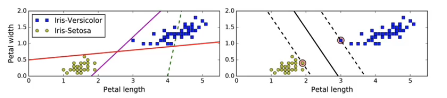
左图虚线表现非常不好。实线边界与实例过于接近,导致在面对新实例时,可能表现不会太好。
右图中的实线代表SVM分类器的决策边界,不仅分离了两个类别,且尽可能远离最近的训练实例
3、硬间隔和软间隔
3.1、硬间隔分类
上图1左边的表现
缺点:1、只在数据线性可分离的时候才有效
2、对异常值非常敏感
3.2、软间隔分类
上图1右边的表现
目标时尽可能在保持最大间隔宽阔和闲置间隔选例(即位于最大间隔之上,甚至错误的一边的实例)之间找到良好的平衡。这就是软间隔分类
在Scilit-Learn的SVM类中,可以通过参数C来控制这个平衡。C越小,则间隔越宽,但是间隔违例也会越多。上图显示了在一个非线性可分的数据集上,两个软间隔SVM分类器各自的决策边界和间隔
4、SVM算法API
from sklearn import svm
x=[[0,0],[1,1]]
y = [0,1]
ss=svm.SVC()
ss.fit(x,y)
ss.predict([[2,2]])
array([1]) 所属类别1
5、SVM算法原理
5.1、定义输入数据

5.2、线性可分支持向量机


5.3、SVM的计算过程
5.3.1、推导目标函数


5.3.2、目标函数求解
目标函数带有一个约束条件,可以用拉格朗日乘子法求解
拉格朗日乘子法:一种寻找多元函数在一组约束瞎的极值方法。通过引入拉格朗日乘子,可将有d个变量与K个约束条件的优化问题转化为具有d+k个变量的无约束优化问题求解。


5.3.3、整体流程确定

5.3.4、举例


5.4、SVM的损失函数

主要用Hinge函数
5.5、SVM核方法
核函数并不是SVM特有的,核函数可以和其他算法也进行结合,只是核函数与SVM结合的优势非常大
核函数概念:是将原始输入空间映射到新的特征空间,从而,是的原本线性不可分的样本可能在核空间可分



常见核函数

一般有如下指导规则

5.6、SVM回归
SVM回归是让尽可能多的实例位于预测线上,同事闲置问题违例(也就是不在预测线距上的实例)
线距的宽度由参数C控制

6、SVM算法api综述
6.1、综述
SVM方法可以用于分类(二\多分类),也可用于回归和异常值检测
SVM具有良好的鲁棒性,对未知数据拥有很强的泛化能力,特别是在数据量较少的情况下,相较其它传统机器学习算法具有更优的性能
6.2、流程
1、样本归一化
2、应用核函数对样本进行映射(通常采用和核函数是RBF和Linear,在样本线性可分时,Linear效果比RBF好)
3、用cross-valivation 和grid-search对超参数进行优选
4、用最优参数训练得到模型
5、测试
6.3、方法
sklearn中支持向量分类主要由三种方法:SVM、NOSVM、LinearSVM 扩展为三个支持向量回归方法:SVR、NuSVR、LinearSVR


7、案例:数字识别器:
目标:从数万个手写图像的数据集中正确识别数字
每个图像的高度为28个像素,高度为28个像素,总共为784个像素
每个像素值是0-255之间的整数,包括0和255.较高的数值表示较暗
测试数据集(test.csv)与训练数据集(train.csv)类似
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn import svm
from sklearn.model_selection import train_test_split
#获取数据
train= pd.read_csv('D:\\data\\svm\\train.csv')
train.head()
train.shape
#划分训练集和样本集
train_image = train.iloc[:, 1:]
train_image.head()
train_label = train.iloc[:, 0]
train_label.head()
#查看具体图像
def to_plot(n):
num = train_image.iloc[n,].values.reshape(28, 28)
plt.imshow(num)
plt.axis('off')
plt.show()
to_plot(n = 40)
#对数据特征值归一化
train_image= train_image.values /255
train_label=train_label.values
#数据集分割
x_train,x_val,y_train,y_val = train_test_split(train_image,train_label,train_size=0.8,random_state=0)
print(x_train.shape,x_val.shape)
import time
from sklearn.decomposition import PCA
# 多次使用pca,确定最后的最优模型
def n_components_analysis(n, x_train, y_train, x_val, y_val):
# 记录开始时间
start = time.time()
# pca降维实现
pca = PCA(n_components=n)
print("特征降维,传递的参数为:{}".format(n))
pca.fit(x_train)
# 在训练集和测试集进行降维
x_train_pca = pca.transform(x_train)
x_val_pca = pca.transform(x_val)
# 利用svc进行训练
print("开始使用svc进行训练")
ss = svm.SVC()
ss.fit(x_train_pca, y_train)
# 获取accuracy结果
accuracy = ss.score(x_val_pca, y_val)
# 记录结束时间
end = time.time()
print("准确率是:{}, 消耗时间是:{}s".format(accuracy, int(end - start)))
return accuracy
#传递多个n_components,寻找合理的n_components:
n_s = np.linspace(0.7,0.85, num =5)
accuracy=[]
for n in n_s:
tmp = n_components_analysis(n,x_train,y_train,x_val,y_val)
accuracy.append(tmp)
#准确率可视化展示
plt.plot(n_s,np.array(accuracy),'r')
plt.show()
#确定最优模型
pca=PCA(n_components=0.8)
pca.fit(x_train)
pca.n_components_
x_train_pca = pca.transform(x_train)
x_val_pca = pca.transform(x_val)
print(x_train_pca.shape,x_val_pca.shape)
#训练比较优的模型,计算accuracy
ssl = svm.SVC()
ssl.fit(x_train_pca,y_train)
ssl.score(x_val_pca,y_val)

(33600, 784) (8400, 784)
特征降维,传递的参数为:0.7
开始使用svc进行训练
准确率是:0.9761904761904762, 消耗时间是:19s
特征降维,传递的参数为:0.7374999999999999
开始使用svc进行训练
准确率是:0.9779761904761904, 消耗时间是:19s
特征降维,传递的参数为:0.7749999999999999
开始使用svc进行训练
准确率是:0.9783333333333334, 消耗时间是:23s
特征降维,传递的参数为:0.8125
开始使用svc进行训练
准确率是:0.9798809523809524, 消耗时间是:25s
特征降维,传递的参数为:0.85
开始使用svc进行训练
准确率是:0.9803571428571428, 消耗时间是:28s
(33600, 43) (8400, 43)
8、svm基本综述
svm是一种二类分类模型。
它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器
1)当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即可线性可分支持向量机。
2)当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机
3)当训练数据线性不可分时,通过核技巧及软间隔最大化,学习非线性支持向量机
8、svm优缺点
优点:在高维空间中非常有效
即使在数据维度比样本量大的情况下仍然有效
在决策函数(称为支持向量)中使用训练集的自己,因此他也是高效利用内存的
通用性:不同的核函数与特定的决策函数一一对应
缺点:如果特征数量比样本数量大的多,在选择核函数时要避免过拟合
对缺失数据敏感
对于和函数的高维映射解释力不强















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









