







给定100亿个网址,如何检测出重复的文件?这里所谓的“重复”是指两个URL完全相同。


或者:
使用hash将所有整数映射到1000个文件中,在每个文件中使用 bitmap,用两个bit表示出现次数,00表示没出现过,01表示出现过1次,10表示出现过多次,11舍弃,最后归并每个文件中出现只有1次的数即为所求。
如果是有符号整数的话,范围为-2147483648~2147483647 无符号整数为0~4294967296 有符号的使用两个bitset,一个存放正数,一个负数。 每个数使用两个位来判断其出现几次。00表示出现0词,01出现1次,10出现大于一次。 比如说存放整数100,就将bitset的第100*2位设置为+1,当所有数放完之后,对每两位进行测试看其值为多少?若是第i为与i+1为的值为 01,则这个整数:i*2,在集合中只出现了1次。需要总共用bitnun=(2^31*2)个位表示,需空间为int[bitnum],即512M.
将文件通过哈希函数成多个小的文件,由于哈希函数所有重复的URL只可能在同一个文件中,在每个文件中利用一个哈希表做次数统计。就能找到重复的URL。这时候要注意的就是给了多少内存,我们要根据文件大小结合内存大小决定要分割多少文件
topK问题和重复URL其实是一样的重复的多了才会变成topK,其实就是在上述方法后获得所有的重复URL排个序,但是有点没必要,因为我们要 找topK时,最极端的情况也就是topK在用一个文件中,所以我们只需要每个文件的topK个URL,之后再进行排序,这样就比找出全部的URL在排序 方法优秀。还有一个topK个URL到最后还是需要排序,所以我们在找每个文件的topK时,是否只需要找到topK个,其中顺序不用管,那么我们就可以 用大小为K的小根堆遍历哈希表。这样又可以降低查找的时间。
这里我来讲一下为什么用小根堆。
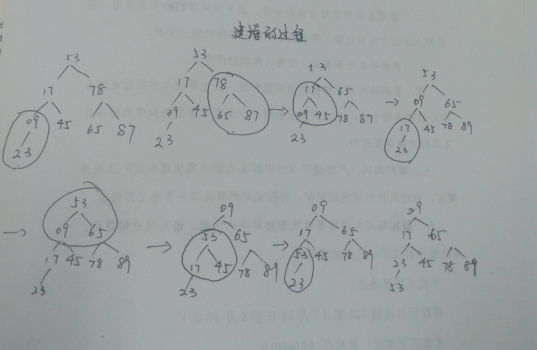
小根堆是一棵完全二叉树存在如下特性
(1)若树根结点存在左孩子,则根结点的值(或某个域的值)小于等于左孩子结点的值(或某个域的值);
(2)若树根结点存在右孩子,则根结点的值(或某个域的值)小于等于右孩子结点的值(或某个域的值);
(3)以左、右孩子为根的子树又各是一个堆。
建最小堆的过程,从最后一个叶节点的父节点开始,往前逐个检查各个节点,看其是不是符合父节点小于它的子节点,如果不小于,则将它的 子节点中最小的那个节点与父节点对换;否则,不交换,















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









