







5.4 Safety
The previous sections described how Raft elects leaders and replicates log entries. However, the mechanisms described so far are not quite sufficient to ensure that each state machine executes exactly the same commands in the same order. For example, a follower might be unavailable while the leader commits several log entries, then it could be elected leader and overwrite these entries with new ones; as a result, different state machines might execute different command sequences.
This section completes the Raft algorithm by adding a restriction on which servers may be elected leader. The restriction ensures that the leader for any given term contains all of the entries committed in previous terms (the Leader Completeness Property from Figure 3). Given the election restriction, we then make the rules for commitment more precise. Finally, we present a proof sketch for the Leader Completeness Property and show how it leads to correct behavior of the replicated state machine.
5.4 安全性
上一章节描述了Raft是如何选举leader和复制日志条目的。然而迄今为止描述的机制并不充分确保每个状态机以相同的顺序执行完相同的命令。例如,follower在leader提交日志条目的时候是不可用的,那么它可能当选leader并以一条新的条目覆盖这些条目;结果就是不同的状态机可能执行不同的命令序列。
本部分通过增加服务器当选leader的限制完成了Raft算法。该限制确保了leader在给定的term里包含之前所有term的已commited的条目(图3中的the Leader Completeness Property)。鉴于选举限制,我们关于提交制订了更精确的标准。最后,我们给出了leader完整性属性的一个正面草图,显示了它是如何引导纠正复制状态机的行为的。
5.4.1 Election restriction
In any leader-based consensus algorithm, the leader must eventually store all of the committed log entries. In some consensus algorithms, such as Viewstamped Replication [22], a leader can be elected even if it doesn’t initially contain all of the committed entries. These algorithms contain additional mechanisms to identify the missing entries and transmit them to the new leader, either during the election process or shortly afterwards. Unfortunately, this results in considerable additional mechanism and complexity. Raft uses a simpler approach where it guarantees that all the committed entries from previous terms are present on each new leader from the moment of its election, without the need to transfer those entries to the leader. This means that log entries only flow in one direction, from leaders to followers, and leaders never overwrite existing entries in their logs.
Raft uses the voting process to prevent a candidate from winning an election unless its log contains all committed entries. A candidate must contact a majority of the cluster in order to be elected, which means that every committed entry must be present in at least one of those servers. If the candidate’s log is at least as up-to-date as any other log in that majority (where “up-to-date” is defined precisely below), then it will hold all the committed entries. The RequestVote RPC implements this restriction: the RPC includes information about the candidate’s log, and the voter denies its vote if its own log is more up-to-date than that of the candidate.
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
5.4.1 选举限制
在任何一个基于leader的一致性算法,leader必须最终储存所有commited的日志条目。某些一致性算法,如Viewstamped Replication[22],leader甚至可以在还没拥有所有commited的日志条目的情况下当选。这些算法有额外机制来辨别条目丢失,无论是选举过程中还是不久之后将它们传给新的leader。不幸的是,这将导致相当大的额外机制和复杂性。Raft用了更简单的策略,即保证在它的选举期间,新的leader拥有之前所有term已commited的条目,不需要传输条目给leader。这意味着日志条目只有一个流向,那就是从leader流向follower,并且leader永不在它的日志里覆盖已有的条目。
Raft通过投票程序来预防一个candidate在日志不全的情况下当选。一个candidate必须联络到集群中的大多数才能当选,着就意味着每个commited的条目至少在这些服务器中的一个上存在。如果该candidate的日志在这大部分服务器中是最新的(如果“最新”是如下定义的),那么它会保留所有commited的条目。RequestVote RPC实现了这个限制:包含了candidate的日志信息,如果投票者自己的日志更新则拒绝。
Raft通过比较两个日志最新条目的index和term来定义两者间谁更新。如果日志条目的term不同,则term值大的更新。如果日志条目的term相同,则长的更新。
5.4.2 Committing entries from previous terms
As described in Section 5.3, a leader knows that an entry from its current term is committed once that entry is stored on a majority of the servers. If a leader crashes before committing an entry, future leaders will attempt to finish replicating the entry. However, a leader cannot immediately conclude that an entry from a previous term is committed once it is stored on a majority of servers. Figure 8 illustrates a situation where an old log entry is stored on a majority of servers, yet can still be overwritten by a future leader.
To eliminate problems like the one in Figure 8, Raft never commits log entries from previous terms by counting replicas. Only log entries from the leader’s current term are committed by counting replicas; once an entry from the current term has been committed in this way, then all prior entries are committed indirectly because of the Log Matching Property. There are some situations where a leader could safely conclude that an older log entry is committed (for example, if that entry is stored on every server), but Raft takes a more conservative approach for simplicity.
Raft incurs this extra complexity in the commitment rules because log entries retain their original term numbers when a leader replicates entries from previous terms. In other consensus algorithms, if a new leader rereplicates entries from prior “terms”, it must do so with its new “term number". Raft's approach makes it easier to reason about log entries, since they maintain the same term number over time and across logs. In addition, new leaders in Raft send fewer log entries from previous terms than in other algorithms (other algorithms must send redundant log entries to renumber them before they can be committed).
5.4.2 提交之前term的条目
如5.3节描述的,一旦条目被大多数服务器储存,leader就会知道当前term的条目是否被提交。如果leader在提交条目前挂了,下一任leader就会尝试完成条目的复制。然而一旦条目被大部分服务器储存,那么leader就不能直接断定条目之前term的条目是否提交了、图8演示了一种情况,一个旧的条目被大部分服务器储存后仍能被未来的leader覆盖。

为了消除如图8这样的情况发生,Raft不允许通过计算副本来提交之前term的日志条目。只有leader当前term的条目可以通过计算副本来提交;一旦当前term的日志条目通过这种方式提交,那么之前的条目都因为the Log Matching Property间接提交了。也有一些情况,leader可以安全的断定之前的日志条目被提交了(例如一个条目被所有服务器存储),但是Raft为了简易性采取了更保守的策略。
因为日志条目保留了之前leader复制条目的term值,Raft的提交机制导致了额外的复杂性。在其他一致性算法中,如果新的leader从之前term重新复制条目,那么就将用新的term替换原本的term值。Raft的策略更容易解释日志条目,因为他们有相同的term值来描述时间的流逝并贯穿整个日志。此外,Raft的新leader比其他算法的发送更少之前term的日志条目(其他算法在提交前必须发送多余的日志条目在用来重新编号)。
5.4.3 Safety argument
Given the complete Raft algorithm, we can now argue more precisely that the Leader Completeness Property holds (this argument is based on the safety proof; see Section 9.2). We assume that the Leader Completeness Property does not hold, then we prove a contradiction. Suppose the leader for term T (leaderT) commits a log entry from its term, but that log entry is not stored by the leader of some future term. Consider the smallest term U > T whose leader (leaderU) does not store the entry.
The committed entry must have been absent from leaderU’s log at the time of its election (leaders never delete or overwrite entries).
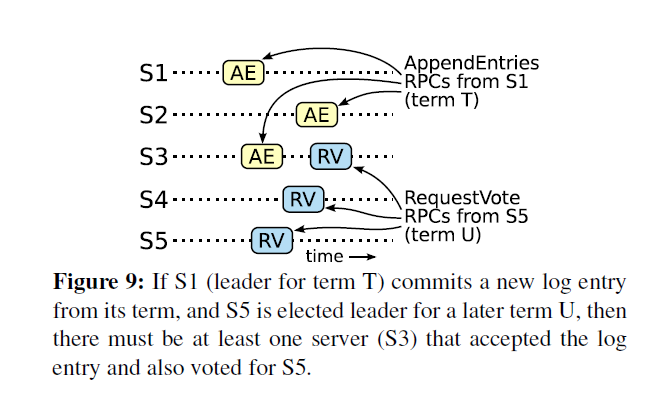
leaderT replicated the entry on a majority of the cluster, and leaderU received votes from a majority of the cluster. Thus, at least one server (“the voter”) both accepted the entry from leaderT and voted for leaderU, as shown in Figure 9. The voter is key to reaching a contradiction.
The voter must have accepted the committed entry from leaderT before voting for leaderU; otherwise it would have rejected the AppendEntries request from leaderT (its current term would have been higher than T).
The voter still stored the entry when it voted for leaderU, since every intervening leader contained the entry (by assumption), leaders never remove entries, and followers only remove entries if they conflict with the leader.
The voter granted its vote to leaderU, so leaderU’s log must have been as up-to-date as the voter’s. This leads to one of two contradictions.
First, if the voter and leaderU shared the same last log term, then leaderU’s log must have been at least as long as the voter’s, so its log contained every entry in the voter’s log. This is a contradiction, since the voter contained the committed entry and leaderU was assumed not to.
Otherwise, leaderU’s last log term must have been larger than the voter’s. Moreover, it was larger than T, since the voter’s last log term was at least T (it contains the committed entry from term T). The earlier leader that created leaderU’s last log entry must have contained the committed entry in its log (by assumption). Then, by the LogMatching Property, leaderU’s log must also contain the committed entry, which is a contradiction.
This completes the contradiction. Thus, the leaders of all terms greater than T must contain all entries from term T that are committed in term T.
The Log Matching Property guarantees that future leaders will also contain entries that are committed indirectly, such as index 2 in Figure 8(d).
Given the Leader Completeness Property, we can prove the State Machine Safety Property from Figure 3, which states that if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index. At the time a server applies a log entry to its state machine, its log must be identical to the leader’s log up through that entry and the entry must be committed. Now consider the lowest term in which any server applies a given log index; the Log Completeness Property guarantees that the leaders for all higher terms will store that same log entry, so servers that apply the index in later terms will apply the same value. Thus, the State Machine Safety Property holds.
Finally, Raft requires servers to apply entries in log index order. Combined with the State Machine Safety Property, this means that all servers will apply exactly the same set of log entries to their state machines, in the same order.
5.4.3 安全性论证
鉴于Raft算法的完整性,我们可以更精确地论证the Leader Completeness Property是成立的(这是基于安全证明的说法;见9.2节)。我们假设the Leader Completeness Property是不成立的,那么我们就会证明一个矛盾。假设处于term T的leader提交了一个日志条目,但是这个条目没有被未来term的leader存储。假定一个最小的term U >T,leaderU没有存该条目。
已提交的条目肯定不在leaderU的选举期(leader从未删除或覆盖条目)。
leaderT从集群的大多数复制了条目,leaderU获得了大部分的选票。因此,至少一个服务器(下称“选民”),既接收了来自leaderT的条目也为leaderU投了票,如图9所示。选民是矛盾的关键。
选民必须在为leaderU投票前接收所有来自leaderT的已提交条目;否则就会拒绝接收leaderT的AppendEntries 请求(当前的term比T大)。
选民依旧在为leaderU投票前存储这些条目,因为每个leader都含有这些条目(根据设定),leader永不删除条目,follower只有在和leader冲突时删除条目。
选民将票投给leaderU,所以leaderU的条目必须和选民的一样新。这导致了两个矛盾之一。
首先,如果选民和leaderU拥有相同的term值,那么leaderU的日志长度至少要和选民一样长,所以它的日志包含选民所有的日志条目。这是一个矛盾,因为选民包含了已提交的条目,而leaderU假设没得到。
否则,leaderU的term值必须比选民的大。此外,它还比T大,因为选民的最新term值至少是T(它包含了所有来自T的已提交条目)。之前的leader创建leaderU的最新日志条目时日志必须包含所有已提交的条目(根据设定)。那么,根据the LogMatching Property,leaderU的日志也必须包含所有已提交的条目,这又是一个矛盾。
这就完成了矛盾。因此,所有大于term T的leader必须包含所有来自在term T已提交的条目。
The Log Matching Property确保了未来的leader也包含所有间接提交的日志条目,如图8索引2(d)。
鉴于the Leader Completeness Property(leader完整性属性),我们可以从图3证明the State Machine Safety Property(状态机安全性属性),如果一个服务器在给定的索引位置从它的状态机申请一个日志条目,其他服务器就不可能在相同索引位置申请到不同日志条目。在一个服务器向它的状态机申请日志条目时,日志肯定和leader的日志一致,并且日志条目已经提交。现在我们考虑下最低term,即所有服务器在给定的索引位申请日志条目时;the Log Completeness Property确保了所有高term的leader存有相同的日志条目,所以服务器在后面的term申请索引时可以申请到相同值。因此, the State Machine Safety Property 成立。
最后,Raft要求服务器按照日志索引顺序申请日志条目。结合the State Machine Safety Property,这意味着所有服务器将能向他们的状态机精确地以相同的顺序申请到日志条目组。















 3030
3030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









