







引子:荒废的空间
自从盘古开天辟地、仓颉创造文字以来,美帝国的程序猿们在长期实践中就发现了这么一个问题:那些组成文字的26个字母在实际应用中的频率是有差别的。
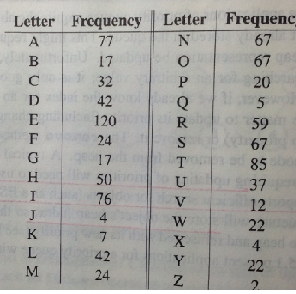
这就意味着有的字母用到的多,而有的用到的会少一点。so,他们认为凡是字母都用7个比特存储这对于那些常用的字母来说并不公平,实际上造成了大量存储空间的荒废。那么怎样让那些最常用的字母在存储过程中占用较少的字节、又较能方便查找呢?
-
霍夫曼树简介
于是,以霍夫曼为代表的机智的程序猿和算分师(算法分析师)们经过一番折腾和探索,为解决这个问题,联想到了堆的应用。因为最大堆(maxium heap)中越大的数字距离根节点越近。因此,如果改进最大堆,使得出现频率越高的字母距离根节点越近,那么搜索出现频率较高的字母的路径不是就变短了吗?他们提出如下图示的解决方案:
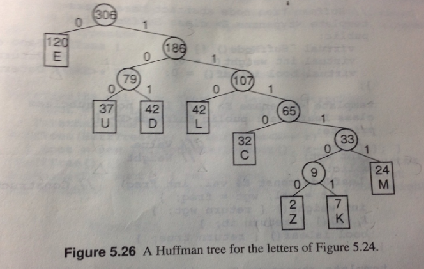
根据此图,寻找任何一个树中的元素,都是从根节点开始,0表示向左子树搜索,1表示向右子树搜索,至含有该元素的叶子节点结束,或者返回找不到。比如在一段给定文本中寻找使用频率为120次的字母E,从根节点306开始,搜索左子树即得E,可记为0。再如,搜索使用频率仅为7次的字母K,搜索过程可记为111101.这样,我们就发现查找高频字母的速度比查找低频字母快了很多。同时,我们发现如果就用一个数字0代表E,比用E的Ascii码代表E明显省了6比特。即使是位于树的深处的字母Z和K,我们也仅仅用了6个位。(然而字母多了以后随着层数的增加这种优势可能丧失)这就为节省这段文本的空间找到了一种可能。在当时不少计算机还是通过插卡才能运行的情况下,这样对于部分字母既省时又省空间的解决方案的发现还是能称得上是一件破天荒的事情的。
- 论霍夫曼树的栽培方法
俗话说“前人栽树后人乘凉”。那么这么好的一棵树是怎么栽起来以备日后使用的呢?我们还是以简介中那棵树的构造过程为例。首先,对出现的字母以频率为关键字进行堆排序(此时先选择最小堆),会得到一个数组如下:

把这个堆最小的两个元素推出,作为霍夫曼树的叶子节点,它们的和作为暂时的根并推入刚才的最小堆,得到以下结果:
 接下来的事情依次类推,推出两个元素9和24:M,在已有树的基础上构造新树,推入它们的和33,形成以下结果:
接下来的事情依次类推,推出两个元素9和24:M,在已有树的基础上构造新树,推入它们的和33,形成以下结果:

有时会出现一种特殊情况,由于上一步推入堆的和太大,连续推出的两个或多个元素都是带有数字和字母的节点,如下图所示,后两个推出的元素是37:U以及42:L:

那么此时,我们就先把推出的两个节点形成另一颗树,根即为它们的和79,再将79推入堆。后面的事情则继续照常进行。因此,每次这样推出2个元素,推入一个元素,这个堆就总有身子被掏空的时候,那个时候只要把这个堆交给各大编程语言的垃圾回收机制,霍夫曼树就算种好了。本例的结果参见简介部分那棵树即可。
- 后记:由霍夫曼树想到什么
我们的中文字符比英语那26个字母复杂得多,这就意味着对于中文字符查找、存储的需求就会更多样化。那么霍夫曼树能否用于中文字符的压缩、存储和查找呢?其二,文本统计得越多,关于字符出现频率的规律就掌握得越准确。那么,是否可以设计一种方法让程序自动统计文本中字符的个数、自动去维护已经种好的树呢?其三,文本可以这么搞,那么数字呢?音频呢?MV呢?甚至计算机病毒的特征存储与分析呢?……笔者认为,这种树引进中国,在对于我国日常工作中用到的数据用它进行处理,可能会带来软件行业的枝繁叶茂,体现在存储和查找的效率可能会被大大提高。因此学习栽种霍夫曼树这个品种的树前景还是比较看好的。上述具体过程,参见笔者分享的代码:简版霍夫曼树,链接:
http://www.oschina.net/code/snippet_2626980_58384
参考资料:
《数据结构与算法分析(C++版)》第三版















 1966
1966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









