







随着大数据日新月异的飞速发展,机器学习也变的越来越性感。云和大数据是天生的一对,那么云上的机器学习又是什么样呢?我们今天就来看看几个基于云的机器学习平台:亚马逊,微软和bigml
亚马逊机器学习
我们先来看看云的领军人物亚马逊的机器学习平台 Amazon Machine Learning
首先,要是用亚马逊的机器学习,你需要有一个AWS的账号(废话)。在Analytics服务区域你会找到他的位置:

Machine Learning是AWS的一个相对比较新的功能,所以当前只有EU(爱尔兰)和美西(弗吉尼亚)两个domain支持。
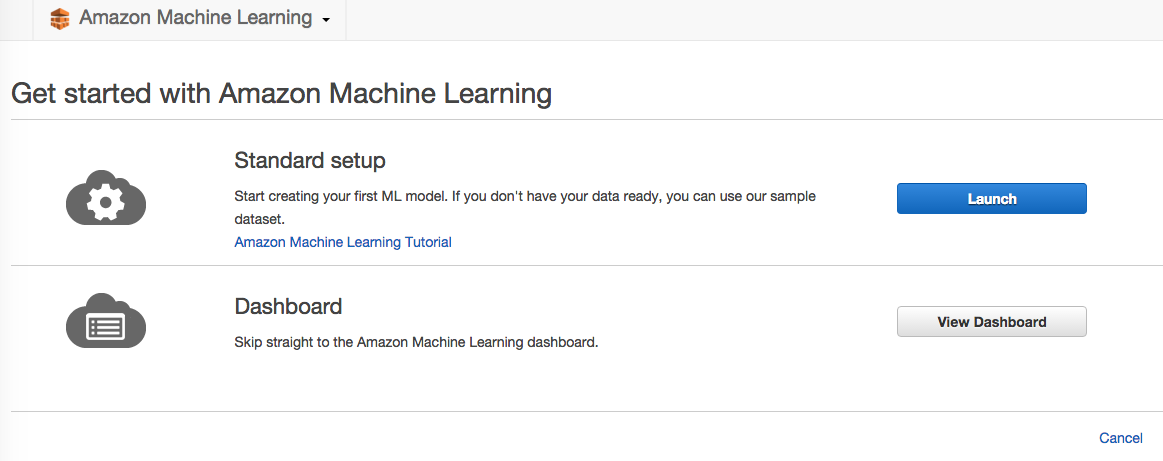
选择Launch启动机器学习,首先需要一个数据源。创建一个数据源分几步:
输入数据 input data
输入的数据源可以来自:用户可以使用S3上的一个csv文件或者来自Amazon Redshift数据库

这里,我在我的S3上放了一个Iris的dataset,Verify后,数据就准备好了。
⚠ Iris Dataset 可能是最著名的数据集 (参见wikipedia的介绍),该数据集包含了三种鸢尾属植物(什么鬼?)的50个样本,该数据包涵植物的花瓣的萼片的长度和宽度的统计。
数据模式 schema
在schema这一步,选择CSV包含name column, (Does the first line in your CSV contain the column names? -> Yes) 结果如下:

目标 Target
在Target这一步,选择一个要预测的目标。
如果选择了Species,AWS会选择创建一个分类模型 (multinomial logistic regression)

如果选择了长度或者宽度属性,AWS会选择创建一个回归模型 (线性回归)

Rowid
这一步用户可以选择一个rowid
review
review所有的数据源选项后,数据源就创建成功了
数据源创建成功后,可以对模型做一些设置。
这里可以选择缺省的设置。
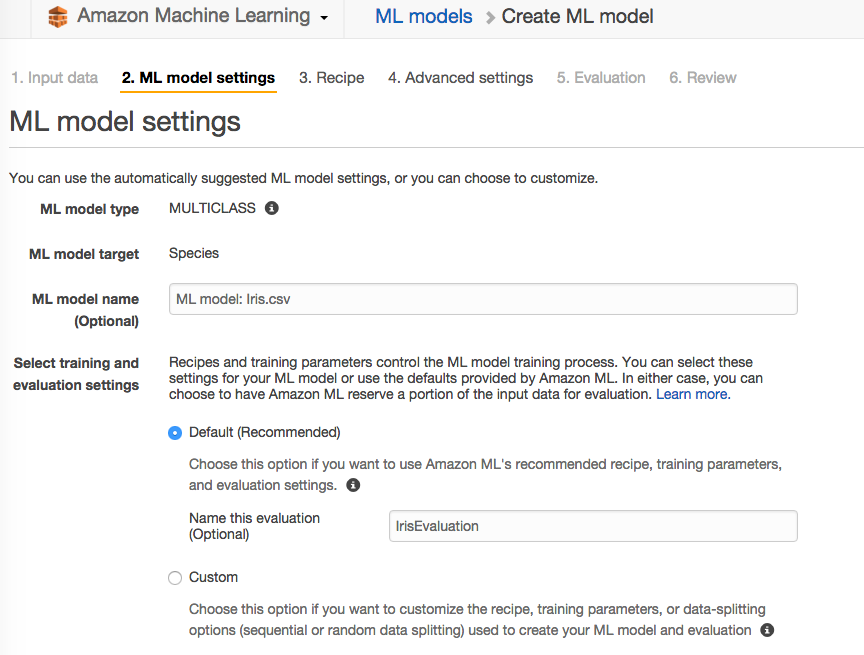
设置好模型后,AWS会对该模型进行评估(evaluation),需要等一段时间看到结果。
我们不需要等待评估的结果,直接来进行预测。
为了省事,我们直接使用原始的Iris数据集进行预测(本文的目的只是为了感受在云上的机器学习,并非解决实际问题)
选择Batch Prediction
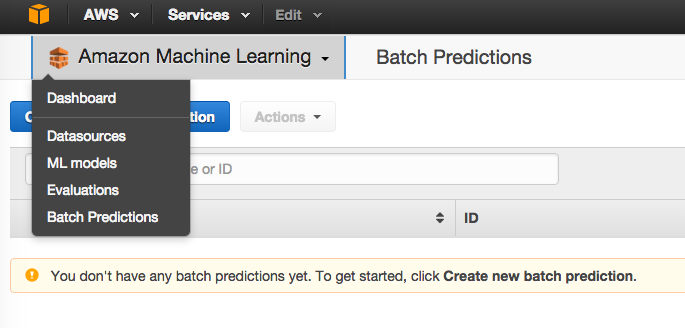
选择我们刚刚创建的模型:

选择Iris数据集来进行预测
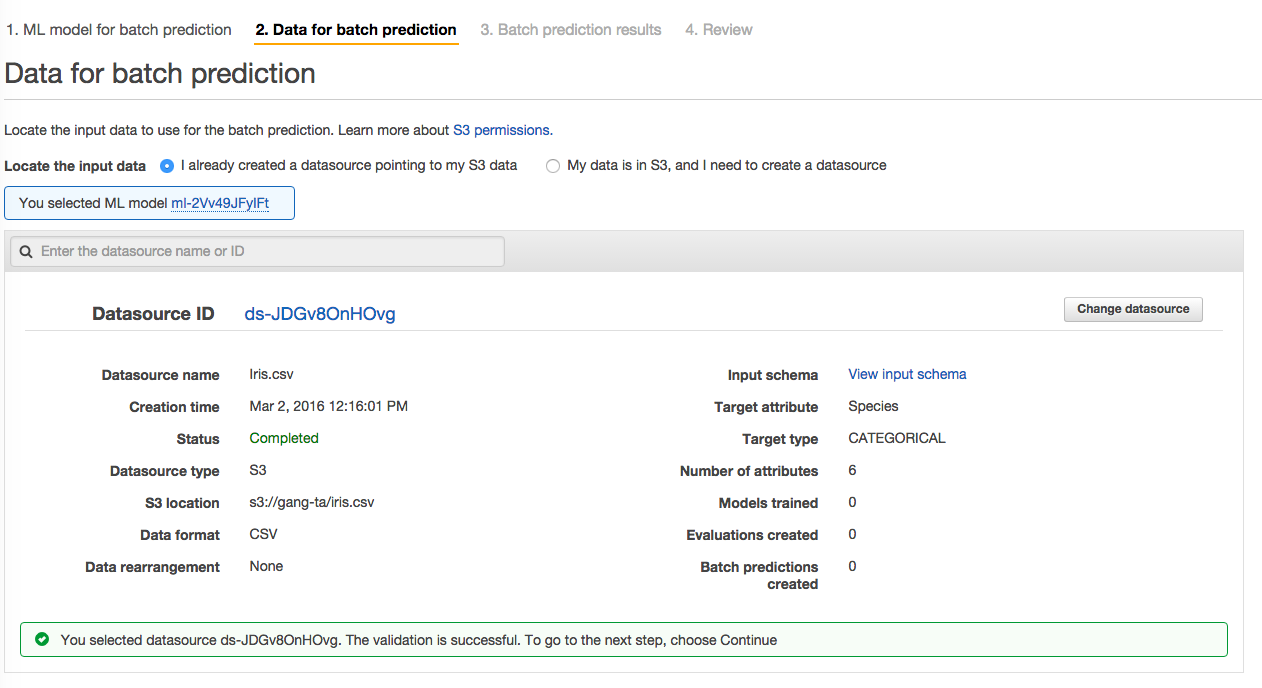
选择一个S3bucket的路径作为预测结果的存放,注意,确保机器学习的服务有对该目录的写权限。
注意,模型的创建是不收费的,但是预测是收费,这里AWS提示每1000个预测收费0.1美元。
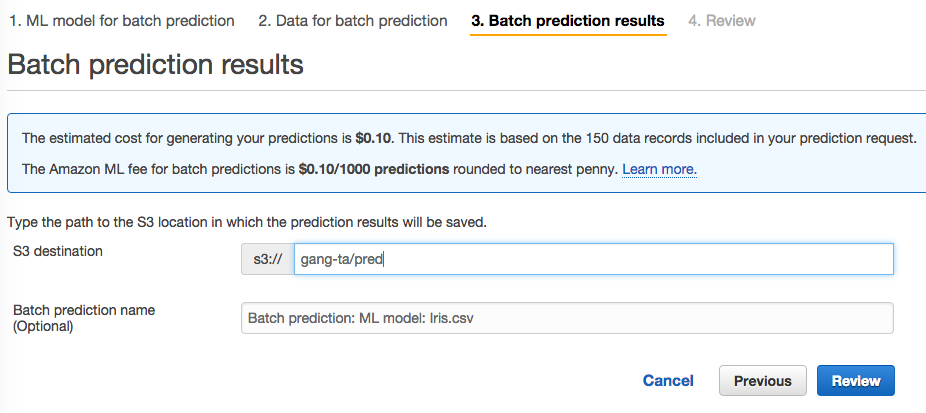
review后没有问题,就开始预测了。

在Dashboard里面可以查看预测的状态,如果是completed表示预测完成。我们去S3里面看看预测的结果如何。
在S3里面我们看到我们之前指定的Bucket里面多了一个batch-prediction的目录,该目录的result目录下就是预测的结果。我们下载下来看看:
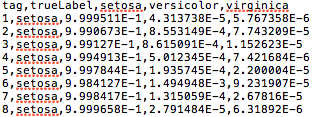
预测的结果是一个文本格式的CSV文件,包含了对每一种结果的预测概率。例如对于第一行的数据,实际是一个setosa,而模型预测是setosa的概率是99.99%。 好像还不错!
好了,现在我们经历了AWS 机器学习 创建数据源 -》 建立模型 -》 对指定89数据集做预测的过程,貌似还不错。
微软Azure机器学习平台
如果说AWS是云行业的number one的话,那么微软的Azure的第二名的位子应该也是稳定的很。当然,微软可不甘心屈居第二,至少在机器学习上,Azure让我们眼前一亮。( Microsoft Azure Machine Learning )
我们试试在Azure上完成同样的测试吧。
首先,你并不需要有一个Azure的账号,可以使用微软账号或者匿名试用,真是太贴心了。
登陆后的界面是这个样子,还好了,不算好看,也不算难看。
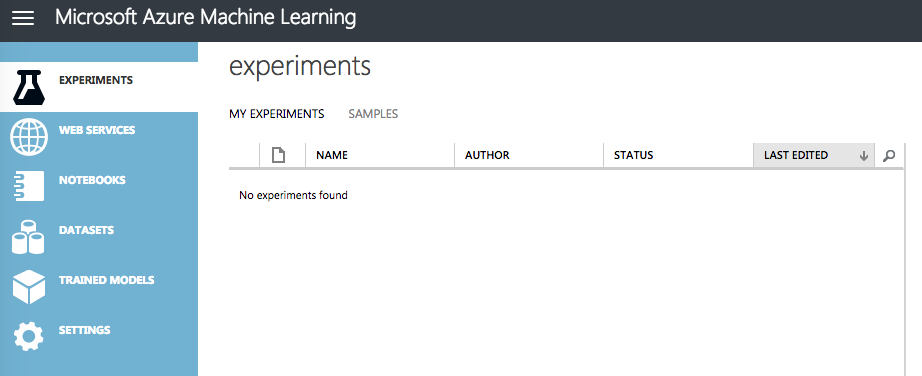
Azure ML的主要功能菜单有:
Experiments (实验)
Web Service (WEB服务)
NOTEBOOK (IPython Notebook, 这个功能很赞)
Datasets (数据集)
Trained Models (已训练的模型)
SETTING (设置)
我们来试验一下同样的对Iris数据集的分类预测,是如何在Azure平台上进行的。
首先还是创建数据源,Azure提供四种数据源,上传本地文件,来自另一个模块(MODULE),来自一个实验(EXPERIMENT)或者一个Notebook。

我们还是上传本地的Iris的CSV文件,上传好后,我们选择一个实验。
选择实验(Experiment)菜单,该功能页面有两个Tab页,我的实验和样例,这里微软很贴心的准备了许多的例子供你参考。
我们选择创建一个空的实验

你会看到以下的界面:

这里Azure使用了基于流程图的编程(Flow Based Programming)概念来创建一个实验。可以把机器学习的过程,直观的用流程图的表示和创建,非常的方便。为了做一个基于Iris数据集的预测模型,我们需要创建如下的一个流程。

注意,在连接数据集到Train Model之后,需要在右侧的UI中选择一个要作为预测目标的列,launch column selector。在这个例子中,我们还是选择Species作为预测目标。
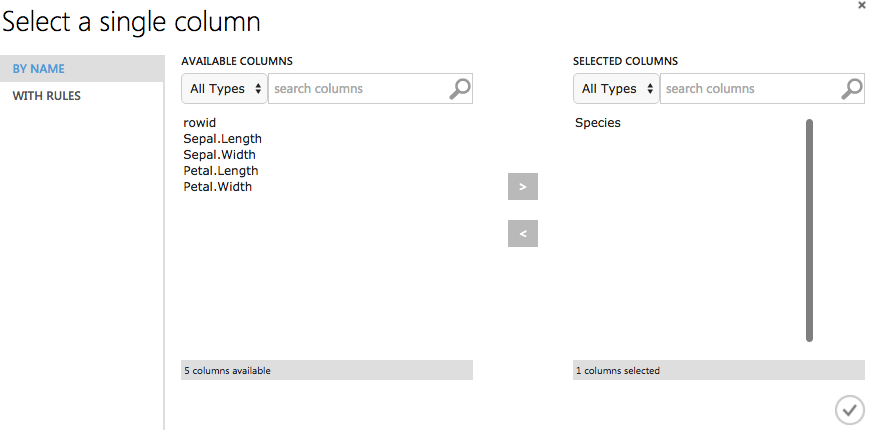
模型建立好后可以保存下来供以后使用。
下面我们开始做预测,我找了半天才找到做预测的模块。名字叫Score Model

加入预测功能后的流程路如下:
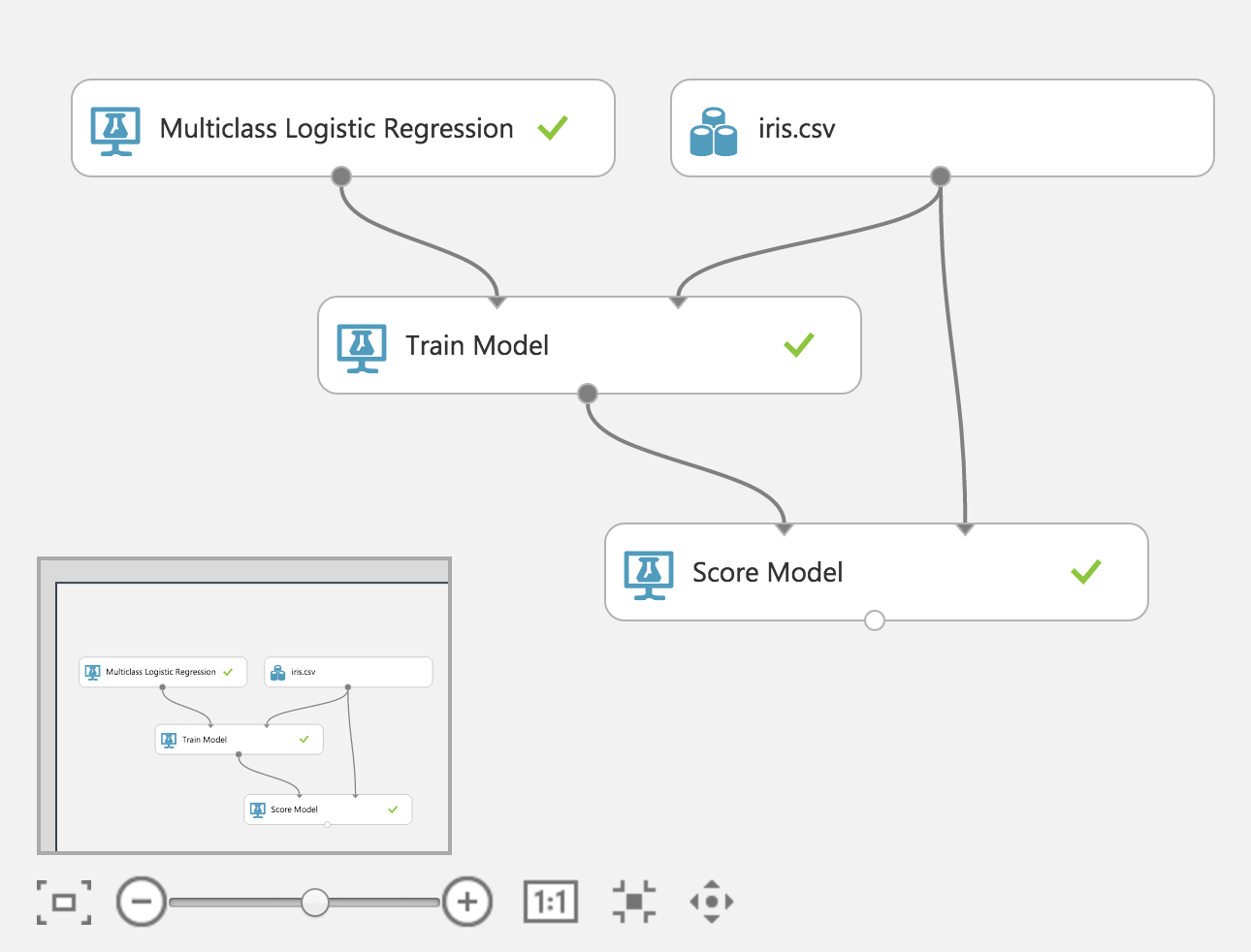
点击下方的运行按钮就可以开始预测的计算了。
预测完成后,右键点击Score Model模块,可以直接以可视化的形式查看结果数据集 (点击Visualize),这个功能非常方便。

预测的可视化结果如下图:

预测的分类结果是Scored Labels。同时用户还可以方便的基于该预测结果的数据集生成不同的图表:
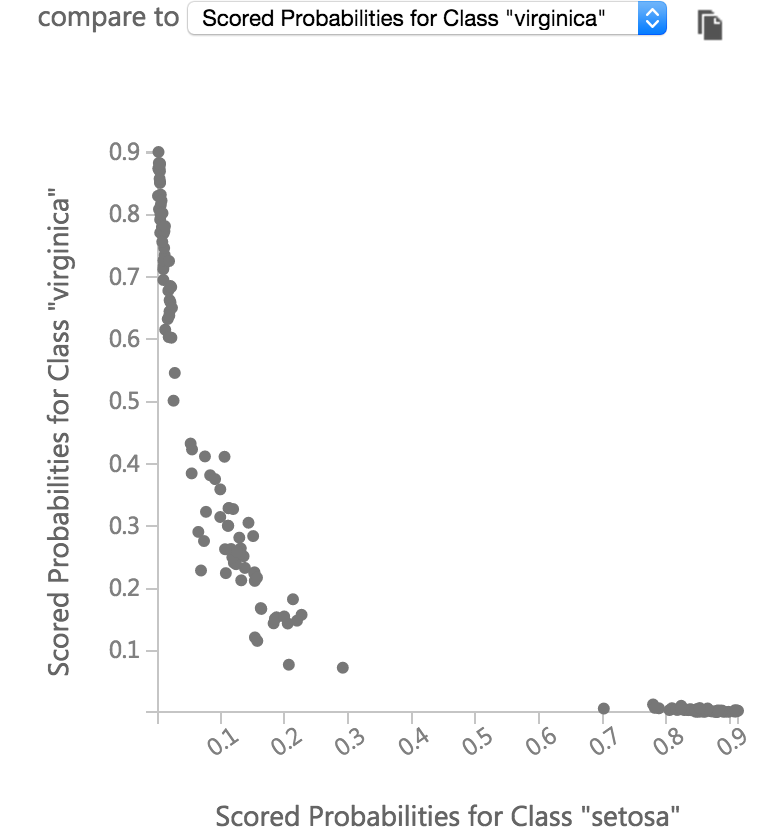
Azure的Machine Learning 平台提供了大量的模块功能,用户可以用Flow的形式把这些模块连接成一个计算网络,实现复杂的机器学习的功能。除了机器学习,这里列出其中的一些其它的功能:
R/Python 可以直接调用Python和R的模块
图像处理 Open CV
文本处理
统计功能
数据变形 Data Transform
Web Service API
Azure的机器学习平台提供非常丰富的机器学习的算法,并且支持R和Python的调用,非常适合数据科学家和程序员使用。而且,免费账户的功能也非常的powerful。堪称业内良心。
BigML
BigML 是提供基于云的机器学习平台, 目标是让机器学习更容易使用。
同样的我们试用一下如何在BigML上对Iris数据集做预测。
登陆后,先进入Dashboard

创建一个数据源,Sources,选择上传CSV文件,上传好了之后,点击数据源,显示如下:

点击Configure Dataset,将数据源转换成Dataset

下一步创建模型,BigML提供了很方便的模型创建功能:

我们选择创建一个模型

BigML会自动选择Species作为预测目标。点击创建模型,注意创建之前,我们需要deselect rowid,因为rowid与预测无关。

创建好的模型是一个Tree结构分类模型,可以看到每一条预测路径的信息:

下面我们就可以用这个模型来做预测了:
点击Predict菜单项,看到如下的预测界面。
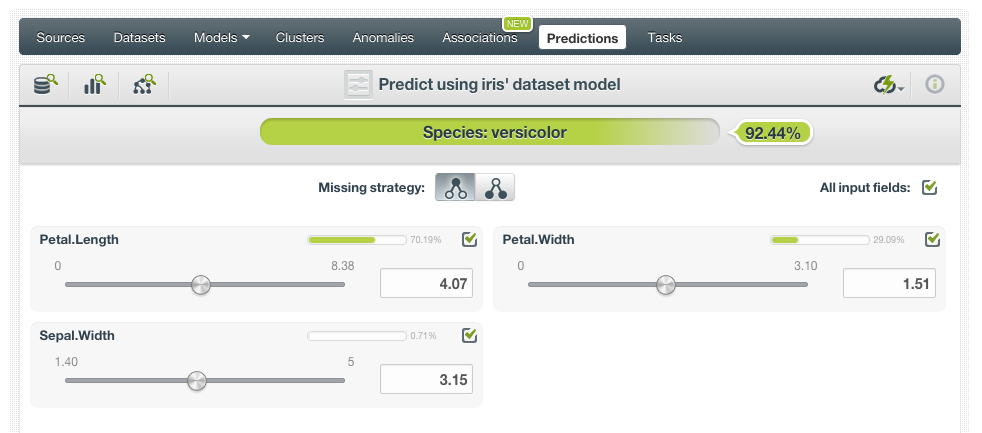
这里很奇怪的是,我明明有四个变量,Tree Model里也可以看到,为什么预测的时候,只能使用其中三个?好了,不关注这些细节,用鼠标滑动改变每一个变量的值,就可以直观的看到预测的结果。这个界面我给100分!
使用下来,BigML确实比较容易使用,用户体验也不错,值得拥有。
其它
除了这几家之外,还有其他的一些厂商也提供了在云上的机器学习,包括Databricks,Google,百度,IBM
Databricks
Databricks这个名字很多人可能不太清楚,然而如果我说Spark,相信大家都是如雷贯耳,2015年大数据领域最火的技术就是Spark了,没有之一。
Databricks是Spark开发者创办的公司,提供一个基于Spark的数据云平台,

因为使用需要信用卡绑定,笔者还没有对该产品进行评估。
Google Prediction API
Googl的Prediction API可能是最早的在提供的云上的机器学习功能了。它提供了一些场景下的预测功能,包括情感分析,垃圾邮件检测,推荐系统等等。不过和其他云平台比较起来,总觉得google的云用着不那么爽。试用账户还要绑定信用卡,我也没有对该产品进行评估。

百度预测
百度基本上是Google有什么都要来抄一个的,所以如果存在一个Baidu Prediction API,我相信大家不会感觉奇怪。果然,百度有一个百度预测。不过百度预测并不是一个通用的机器学习的平台,只能做特定领域的,特定数据集的预测。

其中百度的预测开放平台可以对时间序列的数据进行预测,例如股票(发财了)。

阿里云数加 机器学习

阿里在去年10月高调发布他的数加平台,掌声不断。
阿里云的机器学习正处于公测阶段。https://data.aliyun.com/product/learn?spm=a2c0j.7906235.devenv.2.7rWRRt
大家有兴趣也可以去试用。阅读了他的快速开始文档后,我的内心久久的不能平静,不抄就不会做产品了么。和Azure ML studio 相似度 76.35%。

阿里机器学习的项目名称也叫实验,太专业了,完全保留了Azure的命名风格!
腾讯云
腾讯作为国内体量最大的互联网公司,在云这一块自然不能落后。
腾讯云也有自己的机器学习 TML。

这里是他的帮助文档
同样采用了流程图的方式,开来也许我们错怪了阿里,用流程图来建模是机器学习的标准,微软只是运气好,帅先实现了该标准而已。

IBM Bluemix
IBM近年来在云上的投入非常大,新的Bluemix也提供了非常多的功能呢,其中Watson模块提供了一部分机器学习的功能,但这些功能更多是实现一个更接近用户的功能,比较多的是自然语言处理相关的功能。

除了以上这些厂商,还有其他的几个玩家,我就不一一介绍了,有兴趣的可以自己去看:
比较和总结
这里我们对几个主要的通用机器学习平台最一个比较和总结:
| AWS Machine Learning | Azure Machine Learning | BigML | |
| 数据源格式 | CSV, Redshift | CSV | CSV,Gziped CSV |
| 数据源存储 | S3 | upload from local | S3,Google Storage, Google Drive, Azure, Drop Box |
| 数据准备和变形 | 使用Data Recipes进行数据变形 | 使用特定的Transformation模块或者Python/R编程来进行数据变形 | 只支持简单的数据变形,例如增加字段,过滤等。 |
| 特征提取 | 没有 | 支持 | 没有 |
| 机器学习算法 | 提供基本的分类,回归算法,用户可控部分较少 | 有非常丰富的算法涵盖分类,回归,聚类,异常检测。 | 提供基本的分类,聚类,异常检测的功能,用户可选择的部分较少 |
| 其它功能 | 图像处理,统计,文本分析 | ||
| 编程扩展 | 不支持 | Python/R | 不支持 |
| 可视化功能 | 基本没有 | 可以灵活的对计算过程中的数据进行可视化的展现和分析 | 以图(大部分是树行图)的形式展现模型 |
| API/SDK | Rest API和不同语言的绑定 | Web Service | Rest API以及各种主要语言的绑定(Python,Java,Nodejs,etc) |
| 价格 | 基于预测的次数收费,0.1$/1000次预测 | 免费用户有10G的是试用空间,真心赞。 标准版每月10$ | 免费用户有16M空间 |
除了这几个通用的机器学习的平台,另外几个云上的机器学习也各有特点。Google Prediction API,百度预测,IBM Watson几个产品也都提供了特定场景下的的机器学习或者预测的功能,如果有这一类的需求,也可以使用。对于Databricks以为没有试用,了解不多,希望以后能有机会试用。
如果你是一个程序员或者数据科学家,我觉得Azure的Machine Learning Studio是你不二的选择。他提供了大量的基础算法,并且支持R/Pyhon的扩展。
如果你对机器学习了解不多,希望快速的对已有的数据进行预测,我推荐AWS或者BigML。
如果你是有特定场景的预测要求,可以考虑Google Prediction API,百度预测或者IBM的Watson。
相关链接
http://www.zdnet.com/article/cloud-machine-learning-wars-heat-up/















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









