






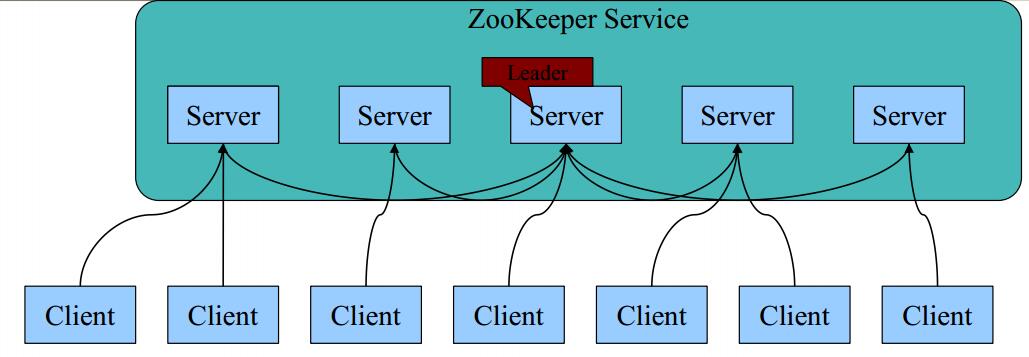
Zookpeeper的基本架构
1 每个Server在内存中存储了一份数据;
2 Zookeeper启动时,将从实例中选举一个leader(Paxos协议);
3 Leader负责处理数据更新等操作(Zab协议);
4 一个更新操作成功,当且仅当大多数Server在内存中成功修改数据。
Zookpeeper Server 节点的数目
Zookeeper Server数目一般为奇数
Leader选举算法采用了Paxos协议;Paxos核心思想:当多数Server写成功,则任务数据写
成功。也就是说:
如果有3个Server,则两个写成功即可;
如果有4或5个Server,则三个写成功即可。
Server数目一般为奇数(3、5、7)
如果有3个Server,则最多允许1个Server挂掉;
如果有4个Server,则同样最多允许1个Server挂掉
既然如此,为啥要用4个Server?
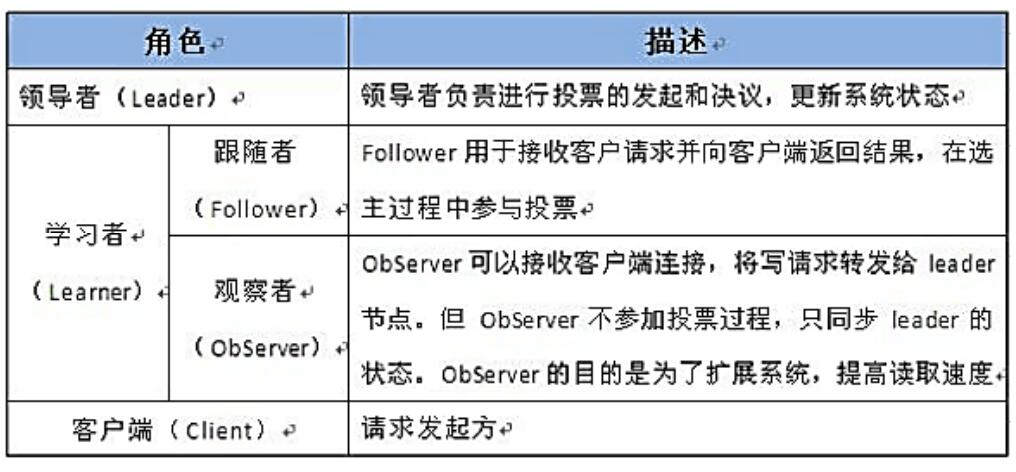
Observer节点
3.3.0 以后 版本新增角色Observer
增加原因:
Zookeeper需保证高可用和强一致性;
当集群节点数目逐渐增大为了支持更多的客户端,需要增加更多Server,然而Server增多,投票阶段延迟增大,影响性能。为了权衡伸缩性和高吞吐率,引入Observer:
Observer不参与投票;
Observers接受客户端的连接,并将写请求转发给leader节点;
加入更多Observer节点,提高伸缩性,同时不影响吞吐率。
Zookeeper写流程:
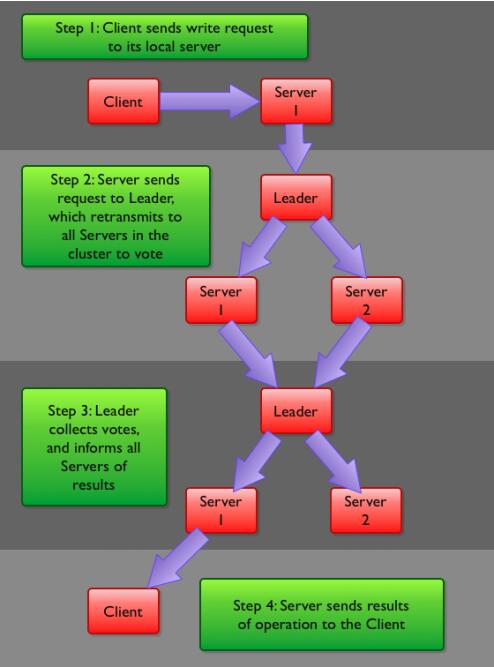
客户端首先和一个Server或者Observe(可以认为是一个Server的代理)通信,发起写请求,然后Server将写请求转发给Leader,Leader再将写请求转发给其他Server,Server在接收到写请求后写入数据并相应Leader,Leader在接收到大多数写成功回应后,认为数据写成功,相应Client。
Zookeeper数据模型
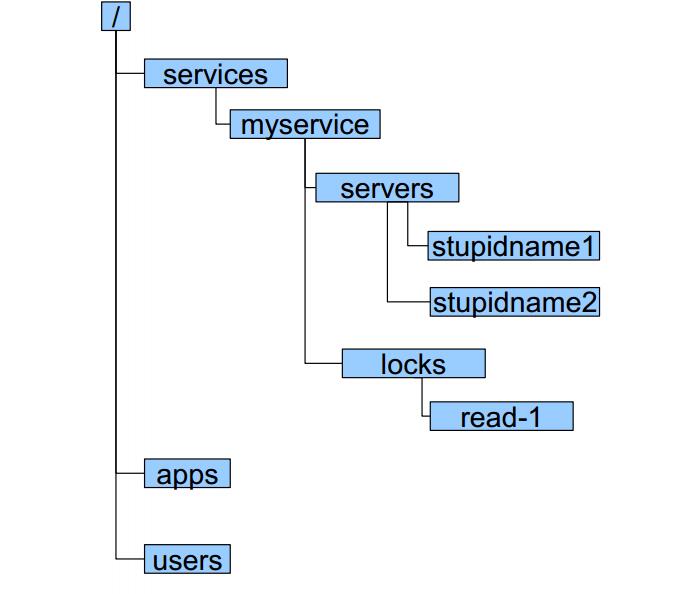
zookeeper采用层次化的目录结构,命名符合常规文件系统规范;
每个目录在zookeeper中叫做znode,并且其有一个唯一的路径标识;
Znode可以包含数据和子znode(ephemeral类型的节点不能有子znode);
Znode中的数据可以有多个版本,比如某一个znode下存有多个数据版本,那么查询这个路径下的数据需带上版本;
客户端应用可以在znode上设置监视器(Watcher)
znode不支持部分读写,而是一次性完整读写
Znode有两种类型,短暂的(ephemeral)和持久的(persistent);
Znode的类型在创建时确定并且之后不能再修改;
ephemeralzn ode的客户端会话结束时,zookeeper会将该ephemeral znode删除,ephemeralzn ode不可以有子节点;
persistent znode不依赖于客户端会话,只有当客户端明确要删除该persistent znode时才会被删除;
Znode有四种形式的目录节点,PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、PHEMERAL_SEQUENTIAL。
转载于:https://blog.51cto.com/2091535/1910001















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









