







在Jupyter中使用Spark
Jupyter 是什么?
The Jupyter Notebook is a web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, machine learning and much more.
Jupyter 是从IPython中分离出来的一个项目。其是一个Web应用,可以方便的使用浏览器创建文档,编写程序,以可视化的方式展示数据。其原始目的为个给Python设计的,但现在可以支持多种语言,Scala就是其中一种。
安装软件
运行环境
- 操作系统 Linux
- Python 3
- Scala 2.11.8
- Spark 1.6.2 (由于toree包现在支持1.6 所以不能用最新的Spark 2.0)
- Apache Torre 0.1.0.dev8 (可以让Jupyter 支持Scala)
首先下载 Scala和Spark
注:我用的是的Debian系列的Linux,可以在Scala官网下载相应的Linux安装包
wget http://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.deb
wget http://mirror.bit.edu.cn/apache/spark/spark-1.6.2/spark-1.6.2-bin-hadoop2.6.tgz
安装 Scala,Spark
sudo dpkg -i scala-2.11.8.deb
sudo tar -xzf spark-1.6.2-bin-hadoop2.6.tgz -C /opt
安装Jupyter和toree
pip3 install jupyter --user
pip3 install toree --user
--user 指定安装方式为用户模式,默认安装在$HOME/.local/bin 只需将此路径加入环境变量即可
export PATH="$HOME/.local/bin:$PATH"
配置Spark和toree
jupyter toree install --spark_home=/opt/spark-1.6.2-bin-hadoop2.6 --user
启动Jupyter
jupyter-notebook
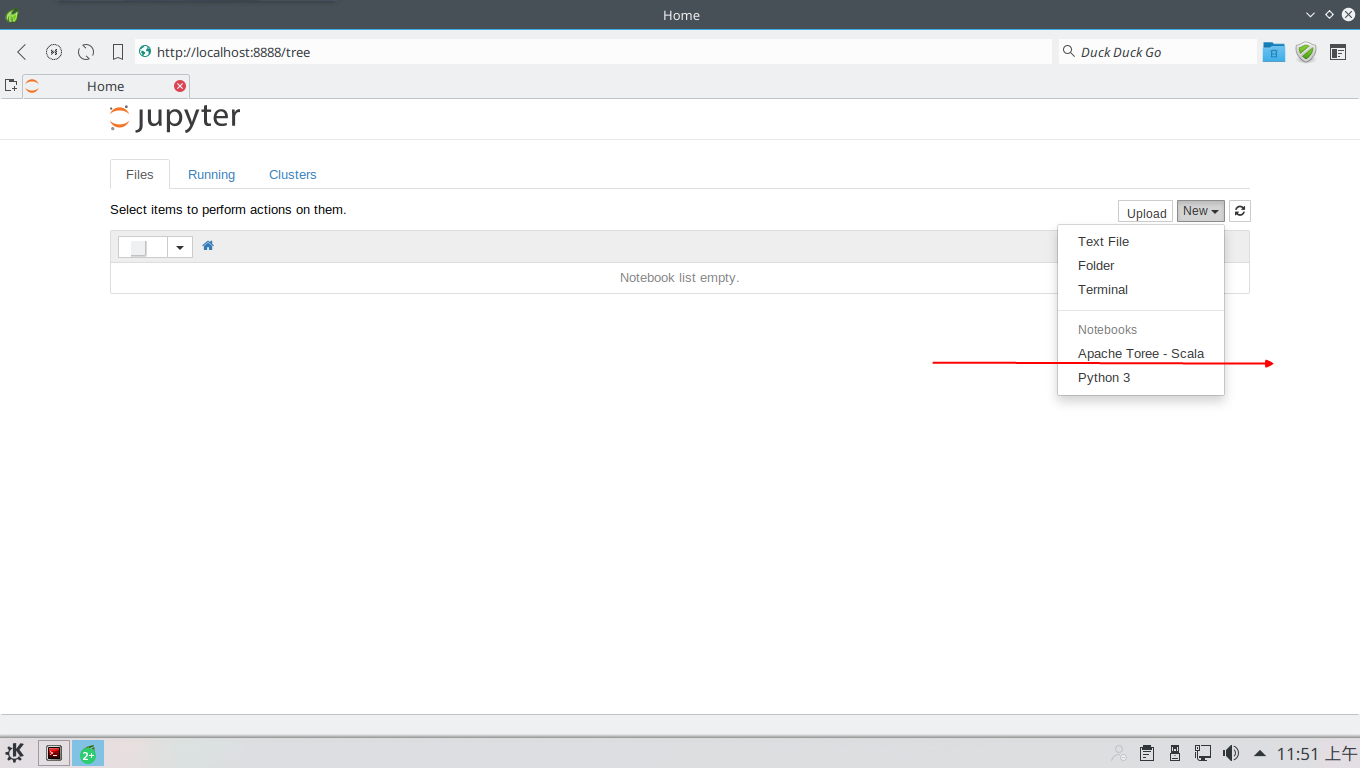
新建一个Kernel
测试一下

这里的每一个输入框都是一个Scala解释器,并且带有SparkContext。可以当作是一个Spark-Shell
使用Jupyter有几个优势
- 方便修改代码
- 方便查看结果
- 可以把操作记录生成文档
- 可以远程访问(只需将Jupyter 端口绑定到0.0.0.0即可)
全民放假,今天就写到这吧















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









