






堆排序介绍
堆排序,顾名思义,就是基于堆。因此先来介绍一下堆的概念。
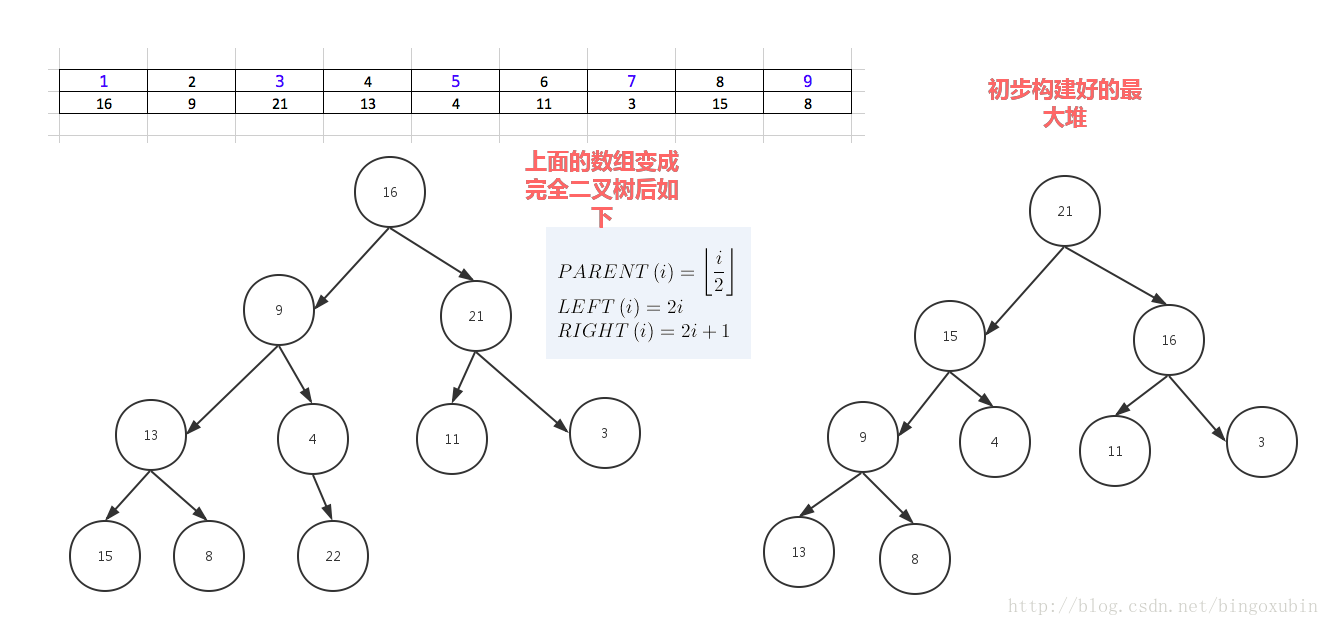
堆分为最大堆和最小堆,其实就是完全二叉树。最大堆要求节点的元素都要大于其孩子,最小堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求,其实很好理解。有了上面的定义,我们可以得知,处于最大堆的根节点的元素一定是这个堆中的最大值。其实我们的堆排序算法就是抓住了堆的这一特点,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最大堆,依次类推,最终得到排序的序列。
-
步骤:
-
堆排序就是把堆顶的最大数取出,
将剩余的堆继续调整为最大堆,具体过程在第二块有介绍,以递归实现
剩余部分调整为最大堆后,再次将堆顶的最大数取出,再将剩余部分调整为最大堆,这个过程持续到剩余数只有一个时结束
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import time,random
def sift_down(arr, node, end):
root = node
#print(root,2*root+1,end)
while True:
# 从root开始对最大堆调整
child = 2 * root +1 #left child
if child > end:
#print('break',)
break
print("v:",root,arr[root],child,arr[child])
print(arr)
# 找出两个child中交大的一个
if child + 1 <= end and arr[child] < arr[child + 1]: #如果左边小于右边
child += 1 #设置右边为大
if arr[root] < arr[child]:
# 最大堆小于较大的child, 交换顺序
tmp = arr[root]
arr[root] = arr[child]
arr[child]= tmp
# 正在调整的节点设置为root
#print("less1:", arr[root],arr[child],root,child)
root = child #
#[3, 4, 7, 8, 9, 11, 13, 15, 16, 21, 22, 29]
#print("less2:", arr[root],arr[child],root,child)
else:
# 无需调整的时候, 退出
break
#print(arr)
print('-------------')
def heap_sort(arr):
# 从最后一个有子节点的孩子还是调整最大堆
first = len(arr) // 2 -1
for i in range(first, -1, -1):
sift_down(arr, i, len(arr) - 1)
#[29, 22, 16, 9, 15, 21, 3, 13, 8, 7, 4, 11]
print('--------end---',arr)
# 将最大的放到堆的最后一个, 堆-1, 继续调整排序
for end in range(len(arr) -1, 0, -1):
arr[0], arr[end] = arr[end], arr[0]
sift_down(arr, 0, end - 1)
#print(arr)
def main():
# [7, 95, 73, 65, 60, 77, 28, 62, 43]
# [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [16,9,21,13,4,11,3,22,8,7,15,27,0]
array = [16,9,21,13,4,11,3,22,8,7,15,29]
#array = []
#for i in range(2,5000):
# #print(i)
# array.append(random.randrange(1,i))
print(array)
start_t = time.time()
heap_sort(array)
end_t = time.time()
print("cost:",end_t -start_t)
print(array)
#print(l)
#heap_sort(l)
#print(l)
if __name__ == "__main__":
main()
dataset = [16,9,21,3,13,14,23,6,4,11,3,15,99,8,22]
for i in range(len(dataset)-1,0,-1):
print("-------",dataset[0:i+1],len(dataset),i)
#for index in range(int(len(dataset)/2),0,-1):
for index in range(int((i+1)/2),0,-1):
print(index)
p_index = index
l_child_index = p_index *2 - 1
r_child_index = p_index *2
print("l index",l_child_index,'r index',r_child_index)
p_node = dataset[p_index-1]
left_child = dataset[l_child_index]
if p_node < left_child: # switch p_node with left child
dataset[p_index - 1], dataset[l_child_index] = left_child, p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
if r_child_index < len(dataset[0:i+1]): #avoid right out of list index range
#if r_child_index < len(dataset[0:i]): #avoid right out of list index range
#print(left_child)
right_child = dataset[r_child_index]
print(p_index,p_node,left_child,right_child)
# if p_node < left_child: #switch p_node with left child
# dataset[p_index - 1] , dataset[l_child_index] = left_child,p_node
# # redefine p_node after the switch ,need call this val below
# p_node = dataset[p_index - 1]
#
if p_node < right_child: #swith p_node with right child
dataset[p_index - 1] , dataset[r_child_index] = right_child,p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
else:
print("p node [%s] has no right child" % p_node)
#最后这个列表的第一值就是最大堆的值,把这个最大值放到列表最后一个, 把神剩余的列表再调整为最大堆
print("switch i index", i, dataset[0], dataset[i] )
print("before switch",dataset[0:i+1])
dataset[0],dataset[i] = dataset[i],dataset[0]
print(dataset)














 1678
1678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









