







硬件环境:
win7 64bit、hadoop2.6
1、软件安装配置
- JDK配置
2、下载eclipse 4.4(luna)
- eclipse配置hadoop-eclipse-plugins插件
- 下载eclipse-hadoop2.6.jar 插件
- 链接: https://pan.baidu.com/s/1bMeelC 密码: 36ae
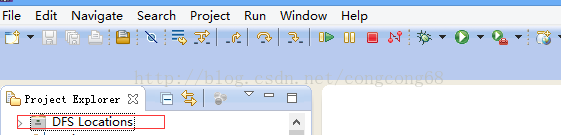
- 把hadoop-eclipse-plugin-2.6.0.jar拷贝到eclipse\plugins目录下,重启一下Eclipse,然后可以看到DFS Locations,如图所示:
- 2.2 打开Window-->Preferens,可以看到Hadoop Map/Reduc选项,然后点击,然后添加hadoop-2.6.0进来,如图所示:

2.3 配置Map/ReduceLocations
- 点击Window-->Show View -->MapReduce Tools 点击Map/ReduceLocation
- 点击Map/ReduceLocation选项卡,
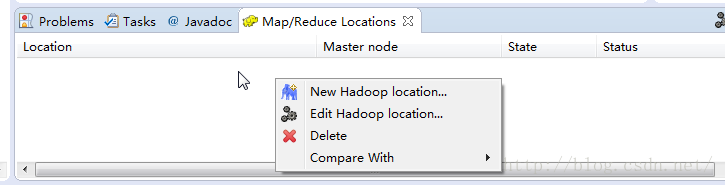 。
。 - 点击New Hadoop location
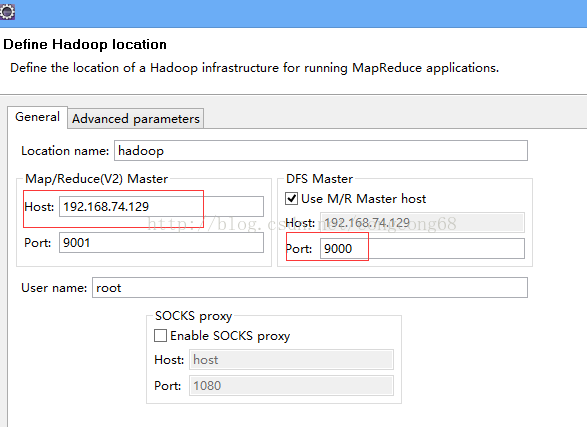
-
修改其中的内容:
我的hadoop安装在虚拟机上,地址为192.168.48.129
修改其中内容:
Map/Reduce Master 这个框里
Host:就是jobtracker 所在的集群机器,这里写192.168.48.129
Hort:就是jobtracker 的port,这里写的是9001
Map/Reduce Master 这个框里:这两个参数就是mapred-site.xml里面mapred.job.tracker里面的ip和port
DFS Master 这个框里
Host:就是namenode所在的集群机器,这里写192.168.48.129
Port:就是namenode的port,这里写9000
DFS Master 这个框里:这两个参数就是core-site.xml里面fs.defaultFS(或fs.default.name)里面的ip和portuser name:这个是连接hadoop的用户名
因为我是用hadoop用户安装的hadoop,而且没建立其他的用户,所以用hadoop。下面的不用填写。然后点击finish按钮,此时,这个视图中就有多了一条记录。
2.4 查看是否连接成功

3、新建MapReduce项目并运行
- 右击New->Map/Reduce Project
- 新建WordCount.java(在Hadoop的share目录下找到mapreduce的案例,copy过来)
- 在hdfs创建一个input目录(输出目录可以不用创建,运行MR是会自动创建),并上传一个file1.txt文件(随便写几个单词)
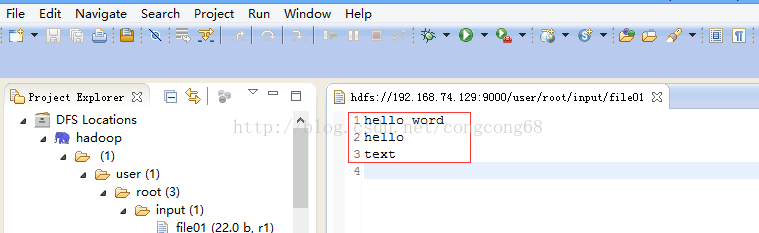
- 点击WordCount.java右击-->Run As-->Run COnfigurations 设置输入和输出目录路径,如图所示:
-

- 点击WordCount.java右击-->Run As-->Run on Hadoop
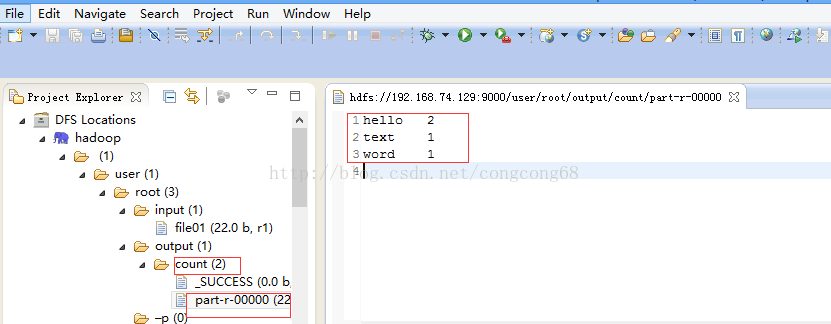
然后到output/count目录下,有一个统计文件,并查看结果,所以配置成功。
注:https://github.com/steveloughran/winutils/tree/master/hadoop-2.6.0/bin
参考;https://my.oschina.net/muou/blog/408543
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









