







hadoop 2.6.5 + hive 集群搭建
概念了解
主从结构:在一个集群中,会有部分节点充当主服务器的角色,其他服务器都是从服务器的角色,当前这种架构模式叫做主从结构。
主从结构分类:
1、一主多从
2、多主多从
Hadoop中的HDFS和YARN都是主从结构,主从结构中的主节点和从节点有多重概念方式:
1、主节点 从节点
2、master slave
3、管理者 工作者
4、leader follower
Hadoop集群中各个角色的名称:
| 服务 | 主节点 | 从节点 |
| HDFS | NameNode | DataNode |
| YARN | ResourceManager | NodeManager |
集群服务器规划
使用3台CentOS-6.8虚拟机进行集群搭建
| 服务 | ip | 主机名称 | 用户 | HDFS | YARN |
| hadoop1 | 192.168.1.40 | hadoop1 | root | NameNode,Datenode,SecondaryNameNode | ResourceManager,NodeManager, |
| hadoop2 | 192.168.1.39 | hadoop2 | root | Datenode | NodeManager |
| hadoop3 | 192.168.1.38 | hadoop3 | root | Datenode | NodeManager |
软件安装步骤概述
1、获取安装包
2、解压缩和安装
3、修改配置文件
4、初始化,配置环境变量,启动,验证
Hadoop安装
1、规划
规划安装用户:root
规划安装目录:/home/hadoop/apps
规划数据目录:/home/hadoop/data
注:apps和data文件夹需要自己单独创建
2、上传解压缩
#wget http://archive.apache.org/dist/hadoop/core/hadoop-2.6.5/hadoop-2.6.5-src.tar.gz
#tar -zxf hadoop-2.6.5-src.tar.gz -C /usr/local/src/
3、修改配置文件
配置文件目录:/use/local/src/hadoop-2.6.5/etc/hadoop

A. hadoop-env.sh
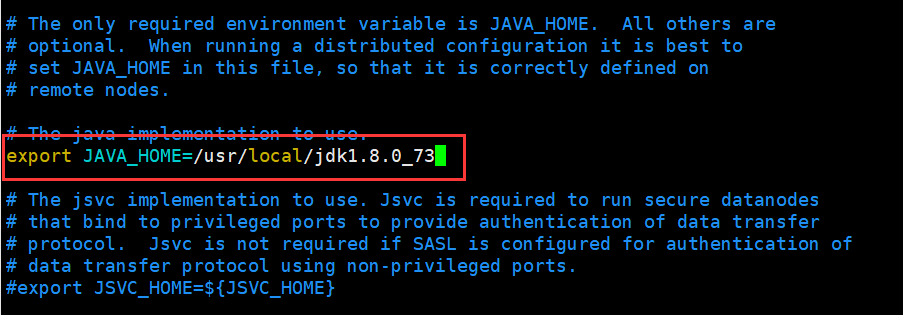
[hadoop@hadoop1 hadoop]$ vi hadoop-env.sh
修改JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_73
B. core-site.xml
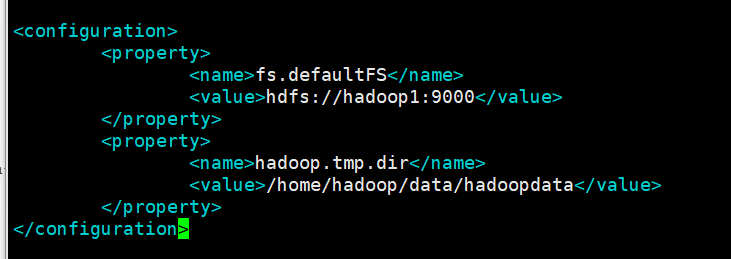
[hadoop@hadoop1 hadoop]$ vi core-site.xml
fs.defaultFS : 这个属性用来指定namenode的hdfs协议的文件系统通信地址,可以指定一个主机+端口,也可以指定为一个namenode服务(这个服务内部可以有多台namenode实现ha的namenode服务
hadoop.tmp.dir : hadoop集群在工作的时候存储的一些临时文件的目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata</value>
</property>
</configuration>
C. hdfs-site.xml
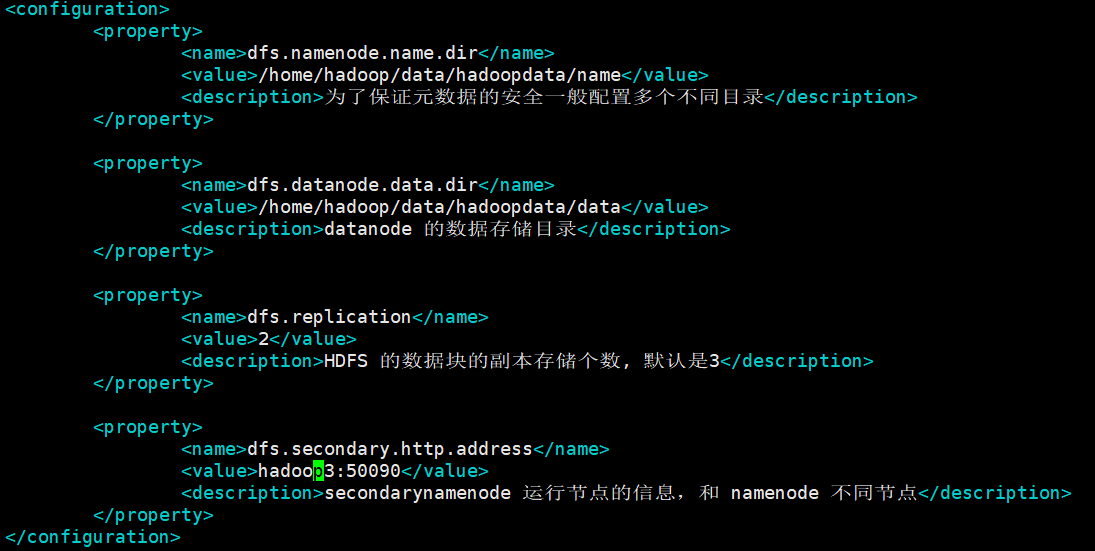
[hadoop@hadoop1 hadoop]$ vi hdfs-site.xml
dfs.namenode.name.dir:namenode数据的存放地点。也就是namenode元数据存放的地方,记录了hdfs系统中文件的元数据。
dfs.datanode.data.dir: datanode数据的存放地点。也就是block块存放的目录了。
dfs.replication:hdfs的副本数设置。也就是上传一个文件,其分割为block块后,每个block的冗余副本个数,默认配置是3。
dfs.secondary.http.address:secondarynamenode 运行节点的信息,和 namenode 不同节点
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/hadoopdata/name</value>
<description>为了保证元数据的安全一般配置多个不同目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoopdata/data</value>
<description>datanode 的数据存储目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>HDFS 的数据块的副本存储个数, 默认是3</description>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop3:50090</value>
<description>secondarynamenode 运行节点的信息,和 namenode 不同节点</description>
</property>
</configuration>
D. mapred-site.xml
[hadoop@hadoop1 hadoop]$ cp mapred-site.xml.template mapred-site.xml [hadoop@hadoop1 hadoop]$ vi mapred-site.xml
mapreduce.framework.name:指定mr框架为yarn方式,Hadoop二代MP也基于资源管理系统Yarn来运行 。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

E. yarn-site.xml
[hadoop@hadoop1 hadoop]$ vi yarn-site.xml
yarn.resourcemanager.hostname:yarn总管理器的IPC通讯地址
yarn.nodemanager.aux-services:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop4</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>
</configuration>

F. slaves
[hadoop@hadoop1 hadoop]$ vi slaves
hadoop1 hadoop2 hadoop3

4、把安装包分别分发给其他的节点
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
[hadoop@hadoop1 hadoop]$ scp -r /usr/local/src/hadoop-2.6.5/ hadoop2:~/usr/local/src/ [hadoop@hadoop1 hadoop]$ scp -r /usr/local/src/hadoop-2.6.5/ hadoop3:~/usr/local/src/
5、配置Hadoop环境变量
千万注意:
1、如果你使用root用户进行安装。 vi /etc/profile 即可 系统变量
2、如果你使用普通用户进行安装。 vi ~/.bashrc 用户变量
[hadoop@hadoop1 ~]$ vi /etc/profile
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:

使环境变量生效
[hadoop@hadoop1 bin]$ source /etc/profile
6、查看hadoop版本
[hadoop@hadoop1 bin]$ hadoop version Hadoop 2.7.5 Subversion Unknown -r Unknown Compiled by root on 2017-12-24T05:30Z Compiled with protoc 2.5.0 From source with checksum 9f118f95f47043332d51891e37f736e9 This command was run using /home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/hadoop-common-2.7.5.jar [hadoop@hadoop1 bin]$

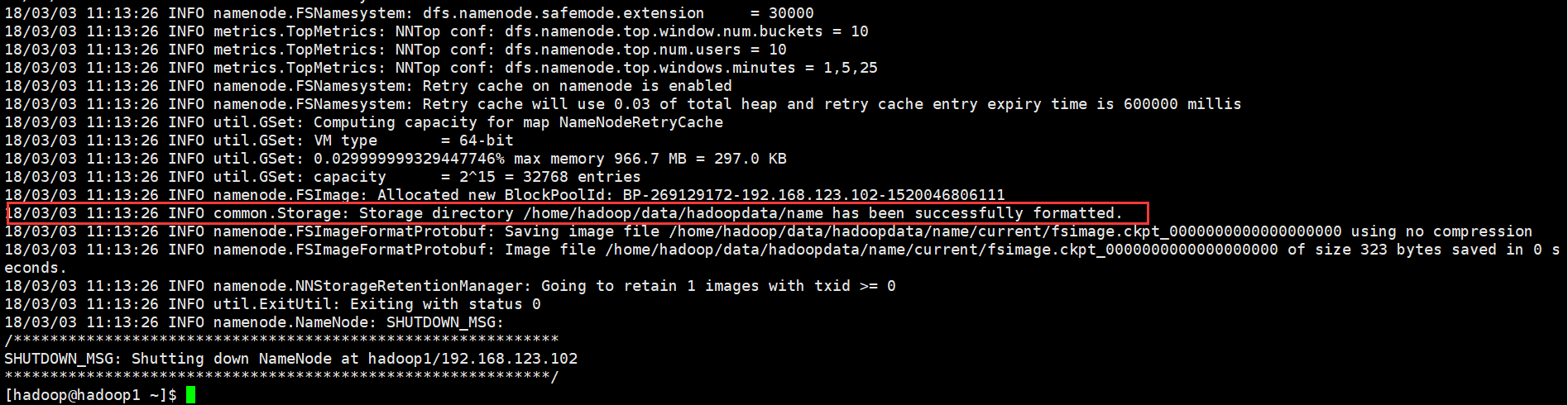
7、Hadoop初始化
注意:HDFS初始化只能在主节点上进行
[hadoop@hadoop1 ~]$ hadoop namenode -format
 View Code
View Code
8、启动
A. 启动HDFS
注意:不管在集群中的那个节点都可以
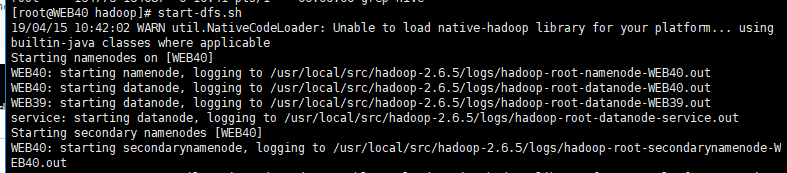
[root@WEB40 hadoop]# start-dfs.sh 19/04/15 10:42:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [WEB40] WEB40: starting namenode, logging to /usr/local/src/hadoop-2.6.5/logs/hadoop-root-namenode-WEB40.out WEB40: starting datanode, logging to /usr/local/src/hadoop-2.6.5/logs/hadoop-root-datanode-WEB40.out WEB39: starting datanode, logging to /usr/local/src/hadoop-2.6.5/logs/hadoop-root-datanode-WEB39.out service: starting datanode, logging to /usr/local/src/hadoop-2.6.5/logs/hadoop-root-datanode-service.out Starting secondary namenodes [WEB40] WEB40: starting secondarynamenode, logging to /usr/local/src/hadoop-2.6.5/logs/hadoop-root-secondarynamenode-WEB40.out
B. 启动YARN
注意:只能在主节点中进行启动
[root@WEB40 hadoop]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /usr/local/src/hadoop-2.6.5/logs/yarn-root-resourcemanager-WEB40.out WEB40: starting nodemanager, logging to /usr/local/src/hadoop-2.6.5/logs/yarn-root-nodemanager-WEB40.out WEB39: starting nodemanager, logging to /usr/local/src/hadoop-2.6.5/logs/yarn-root-nodemanager-WEB39.out service: starting nodemanager, logging to /usr/local/src/hadoop-2.6.5/logs/yarn-root-nodemanager-service.out

9、查看4台服务器的进程
hadoop1

hadoop2

hadoop3

10、启动HDFS和YARN的web管理界面
HDFS : http://192.168.1.40:50070
YARN : http://192.168.1.40:8088
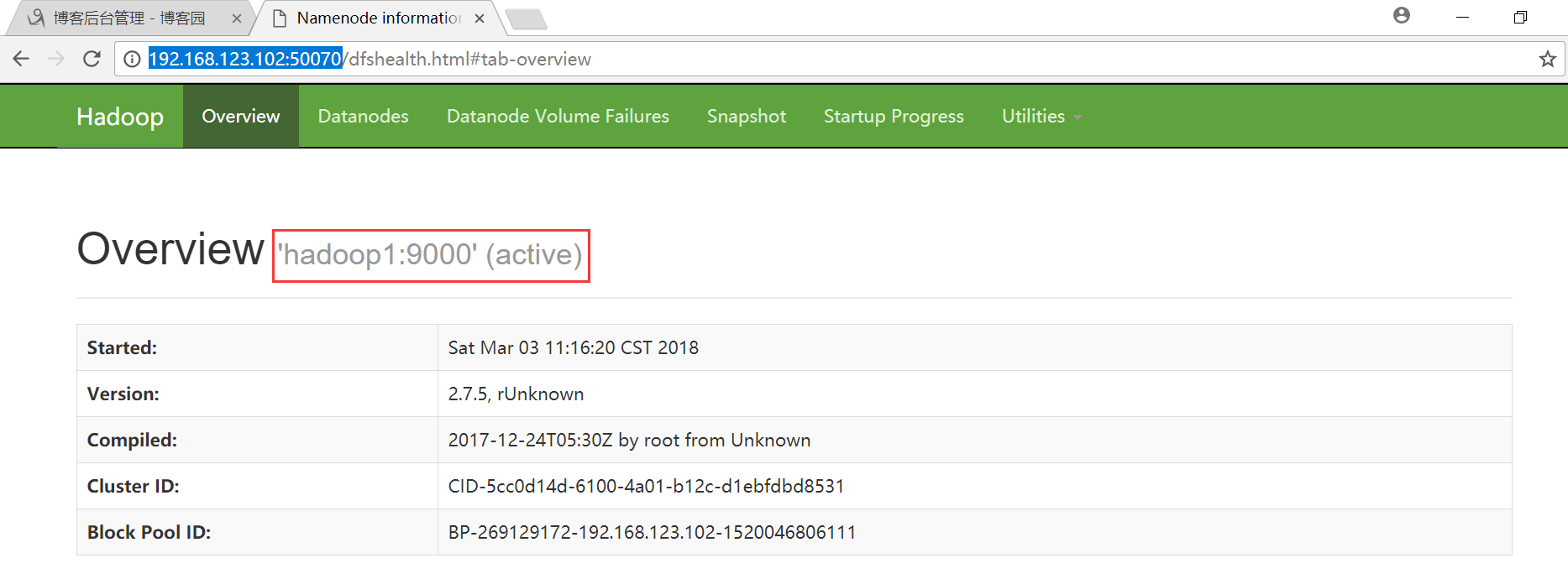
疑惑: fs.defaultFS = hdfs://hadoop1:9000
解答:客户单访问HDFS集群所使用的URL地址
同时,HDFS提供了一个web管理界面 端口:50070
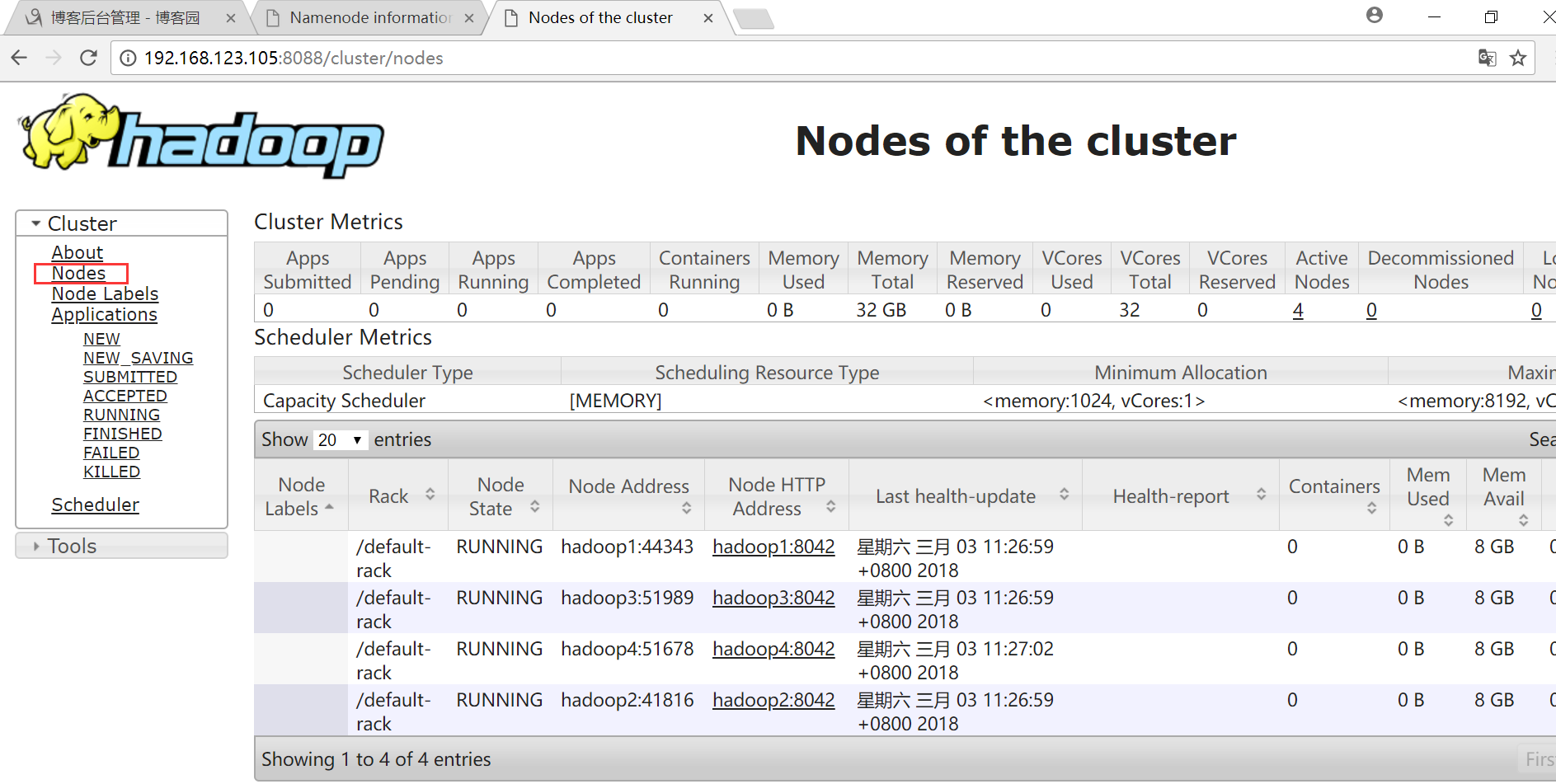
HDFS界面
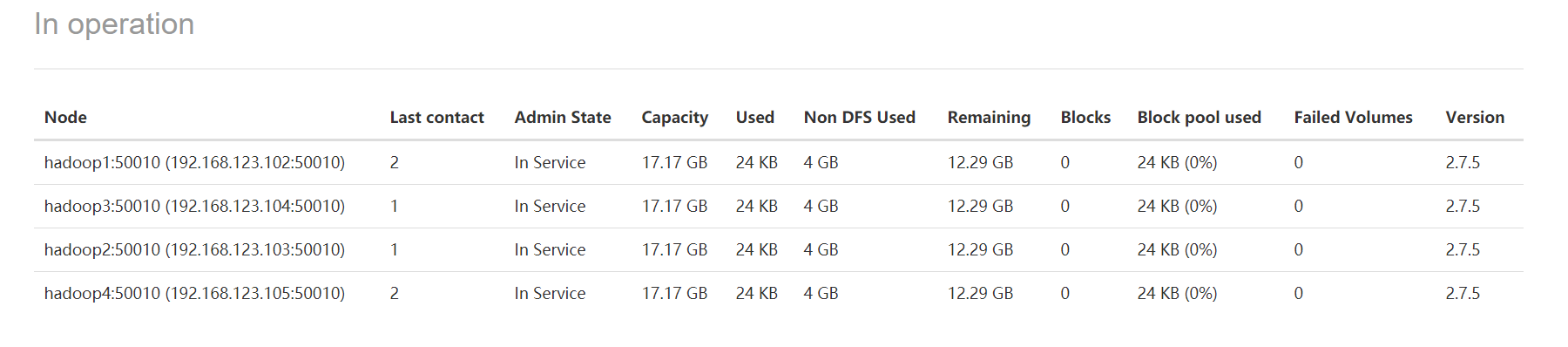
点击Datanodes可以查看四个节点
YARN界面
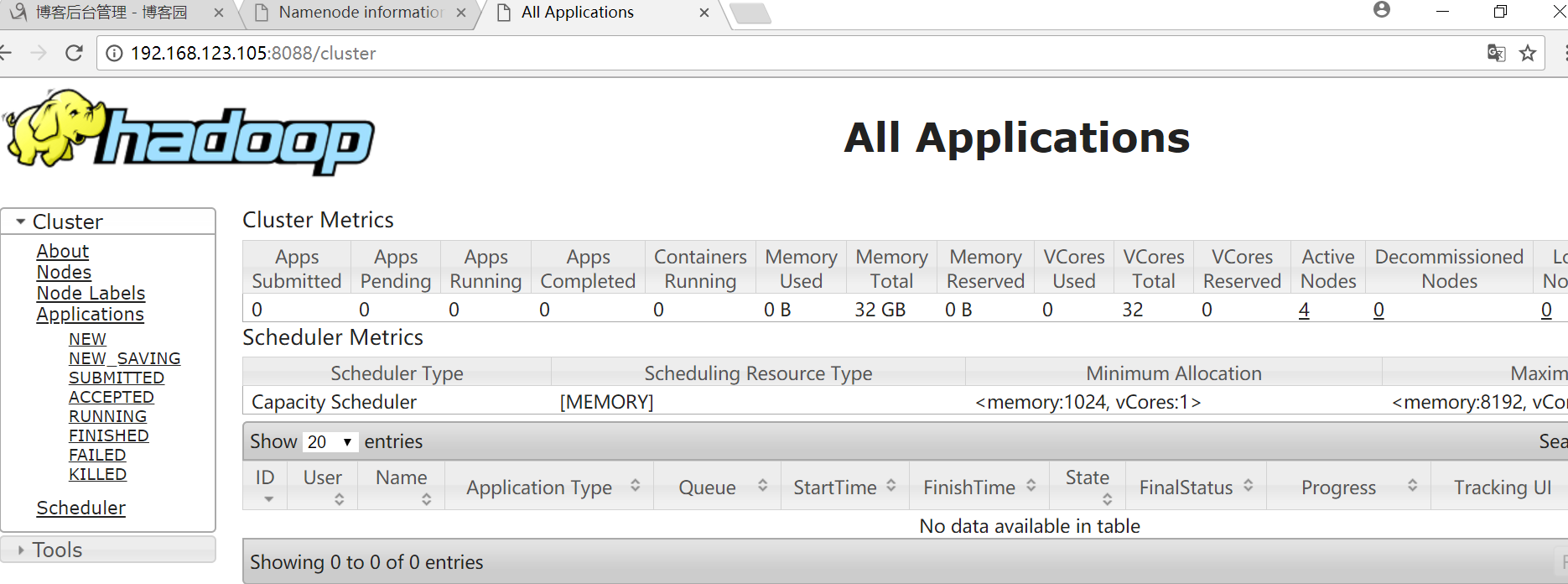
点击Nodes可以查看节点
Hadoop的简单使用
创建文件夹
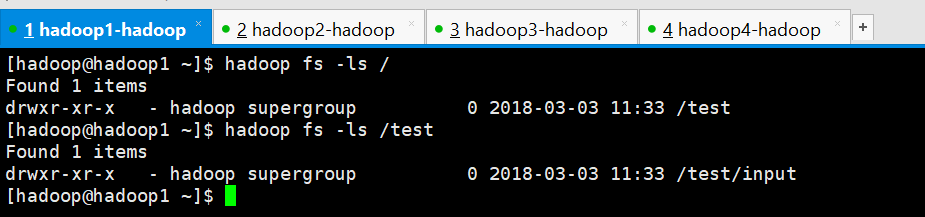
在HDFS上创建一个文件夹/test/input
[hadoop@hadoop1 ~]$ hadoop fs -mkdir -p /test/input
查看创建的文件夹
[hadoop@hadoop1 ~]$ hadoop fs -ls / Found 1 items drwxr-xr-x - hadoop supergroup 0 2018-03-03 11:33 /test [hadoop@hadoop1 ~]$ hadoop fs -ls /test Found 1 items drwxr-xr-x - hadoop supergroup 0 2018-03-03 11:33 /test/input [hadoop@hadoop1 ~]$
上传文件
创建一个文件words.txt
[hadoop@hadoop1 ~]$ vi words.txt
hello zhangsan hello lisi hello wangwu
上传到HDFS的/test/input文件夹中
[hadoop@hadoop1 ~]$ hadoop fs -put ~/words.txt /test/input
查看是否上传成功
[hadoop@hadoop1 ~]$ hadoop fs -ls /test/input Found 1 items -rw-r--r-- 2 hadoop supergroup 39 2018-03-03 11:37 /test/input/words.txt [hadoop@hadoop1 ~]$

下载文件
将刚刚上传的文件下载到~/data文件夹中
[hadoop@hadoop1 ~]$ hadoop fs -get /test/input/words.txt ~/data
查看是否下载成功
[hadoop@hadoop1 ~]$ ls data hadoopdata words.txt [hadoop@hadoop1 ~]$

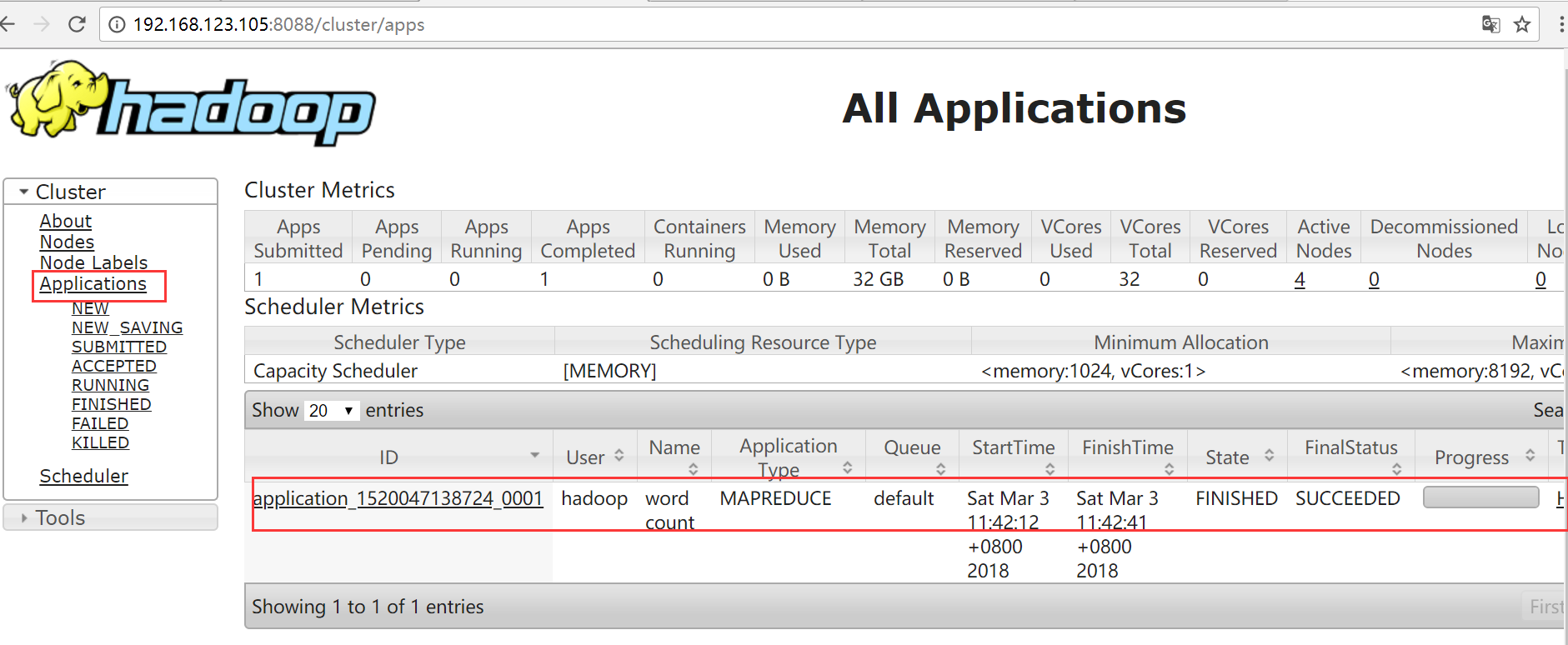
运行一个mapreduce的例子程序: wordcount
[hadoop@hadoop1 ~]$ hadoop jar ~/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /test/input /test/output

在YARN Web界面查看
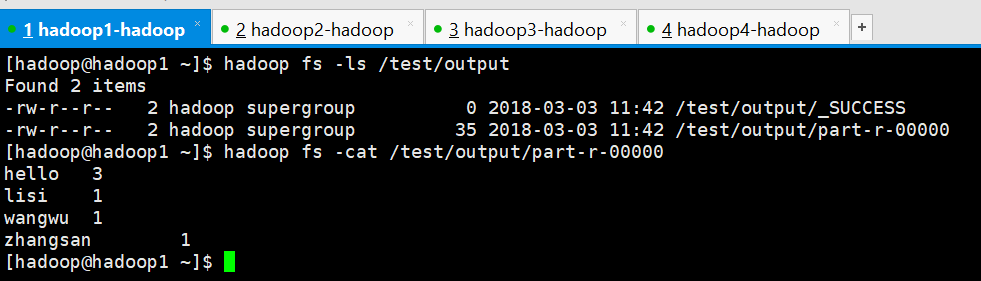
查看结果
[hadoop@hadoop1 ~]$ hadoop fs -ls /test/output Found 2 items -rw-r--r-- 2 hadoop supergroup 0 2018-03-03 11:42 /test/output/_SUCCESS -rw-r--r-- 2 hadoop supergroup 35 2018-03-03 11:42 /test/output/part-r-00000 [hadoop@hadoop1 ~]$ hadoop fs -cat /test/output/part-r-00000 hello 3 lisi 1 wangwu 1 zhangsan 1 [hadoop@hadoop1 ~]$
hive 搭建
1. 系统环境
centos 6.8
Hadoop 2.6.5
Java 1.7.0_51
hadoop集群
master:192.168.1.40
slave1:192.168.1.39
slave2:192.168.1.38
MySQL安装在master机器上,hive服务器也安装在master上
hive版本: https://mirrors.cnnic.cn/apache/hive/hive-2.3.4/apache-hive-2.3.4-bin.tar.gz
2.mysql安装
本文使用MySQL作为远程元数据库,部署在master节点上
2.1安装mysql
安装mysql服务端
sudo apt-get install mysql-server
安装mysql客户端
sudo apt-get install mysql-client
期间会有命令窗口会有跳窗提醒输入密码,一定要记住密码,登录Mysql和后续的配置都需要密码。
2.2.查看mysql服务是否启动
sudo netstat -tap | grep mysql
2.3.设置mysql远程访问
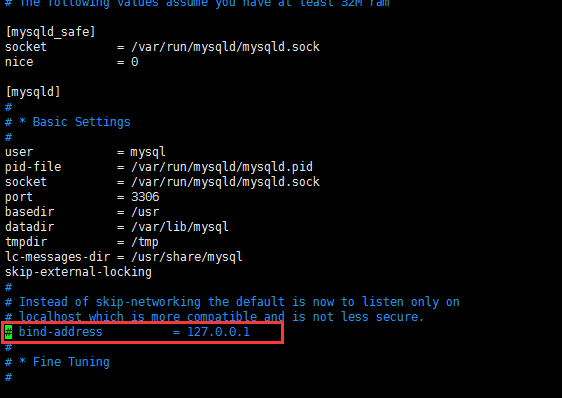
a).编辑mysql配置文件,把其中bind-address = 127.0.0.1注释了
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
b). 使用root进入mysql命令行,执行如下2个命令,示例中mysql的root账号密码就是按照mysql时输入的密码
mysql -u root -p
命令窗口会有提示输入密码,即是安装mysql时输入的密码
c).授权root账户,并授予它远程连接的权力
添加一个用户名是root且密码是root的远程访问用户
grant all on *.* to root@'%' identified by 'root' with grant option;
d).运行完后紧接着输入,以更新数据库:
FLUSH PRIVILEGES;
e).执行quit退出mysql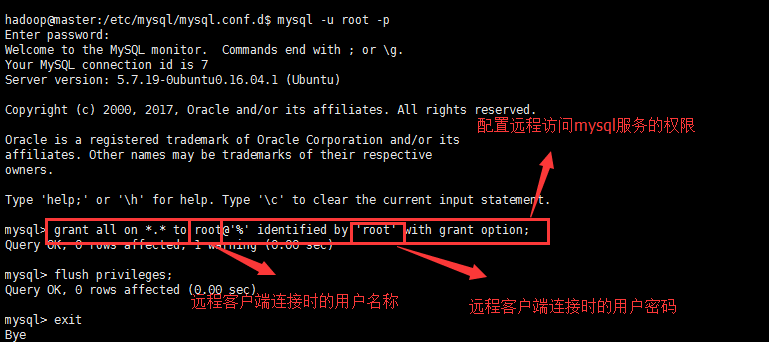
2.4.重启mysql
/etc/init.d/mysql restart
重启成功后,在其他计算机上,便可以登录。
MySQL卸载:
1、sudo apt-get autoremove --purge mysql-server-5.0
2、sudo apt-get remove mysql-server
3、sudo apt-get autoremove mysql-server
4、sudo apt-get remove mysql-common --这个很重要
5、dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg -P -- 清除残留数据
3.Hive安装配置
3.1.下载Hive安装包
wget https://mirrors.cnnic.cn/apache/hive/hive-2.3.0/apache-hive-2.3.0-bin.tar.gz
3.2.解压
tar -zxfv apache-hive-2.3.0-bin.tar.gz
3.3.将解压后的目录移动到自己指定的安装目录
mv apache-hive-2.3.0-bin /home/hadoop/software/
3.4.配置环境变量
sudo vim /etc/profile
export HIVE_HOME=/home/hadoop/software/apache-hive-2.3.0-bin
export PATH=$HIVE_HOME/bin:$PATH
3.5.使环境变量生效
source /etc/profile
3.6.修改conf/下的几个template模板并重命名
a).复制hive-env.sh.template创建为hive-env.sh
cp hive-env.sh.template hive-env.sh
给hive-env.sh增加执行权限
chmod 755 hive-env.sh
修改conf/hive-env.sh 文件
HADOOP_HOME=/home/hadoop/software/hadoop-2.7.4
b).复制hive-default.xml.template创建为hive-site.xml
cp hive-default.xml.template hive-site.xml
修改hive-site.xml文件内容
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<!--配置缓存目录-->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/software/apache-hive-2.3.0-bin/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop/software/apache-hive-2.3.0-bin/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
根据hive-site-xml,创建缓存目录
cd /home/hadoop/software/apache-hive-2.3.0-bin/
mkdir iotmp
3.7.修改 bin/hive-config.sh 文件
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_121
export HIVE_HOME=/home/hadoop/software/apache-hive-2.3.0-bin
export HADOOP_HOME=/home/hadoop/software/hadoop-2.7.4
3.8.下载mysql-connector-java-5.1.44-bin.jar文件,并放到/home/hadoop/software/apache-hive-2.3.0-bin/lib目录下
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.44.tar.gz
解压mysql-connector-java-5.1.44.tar.gz后,将mysql-connector-java-5.1.44-bin.jar放置在lib目录下
4.将apache-hive-2.3.0-bin分发到slave节点
scp -r apache-hive-2.3.0-bin hadoop@slave1:/home/hadoop/software/
scp -r apache-hive-2.3.0-bin hadoop@slave2:/home/hadoop/software/
slave端配置, 修改 conf/hive-site.xml 文件
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
5.Hive的mysql数据库配置
5.1.使用root用户登录mysql数据库
mysql -u root -p
5.2.创建hive用户
mysql> CREATE USER 'hive' IDENTIFIED BY 'hive';
5.3.给hive用户赋权限
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%' WITH GRANT OPTION;
5.4.更新数据库
mysql>flush privileges;
mysql> quit
5.5.Hive用户登录
hadoop@master:~$ mysql -u hive -p
5.6.创建Hive数据库
mysql>create database hive;
6.启动Hive
6.1.启动hadoop
6.2. 进入bin目录初始化表数据
hadoop@master:~/software/apache-hive-2.3.0-bin/bin$./schematool -dbType mysql -initSchema
6.3.启动metastore服务
hive –service metastore &
在 master 节点上运行 jps 应该会有RunJar 进程
6.4.服务器端访问
hadoop@master:~$ hive
6.5.客户端(slave)访问
hadoop@slave2:~$ hive














 3901
3901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









