







之前运行爬虫文件的时候碰到问题,通过查阅百度,需要在手动安装该.py文件(在scripy文件夹内)
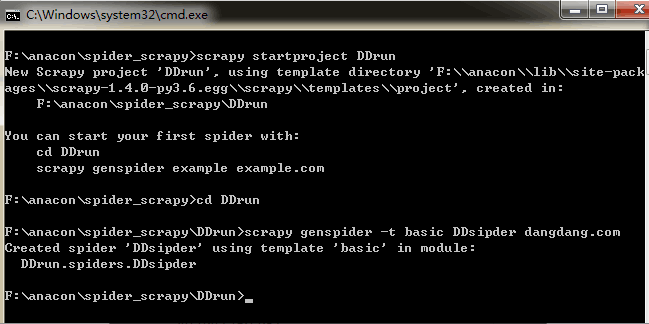
首先使用一下命令生成一个名为DDrun的爬虫项目
scrapy startproject DDruncd到DDrun\DDrun\spiders目录下,然后输入一下命令,创建一个爬虫文件。
scrapy genspider -t basic DDsipder dangdang.com创建爬虫项目及爬虫文件后,先在items.py编写所需要的容器:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DdrunItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#定义title存储商品标题
title = scrapy.Field()
#定义link存储商品链接
link = scrapy.Field()
#定义price存储商品价格
price = scrapy.Field()
#定义author存储商品作者
author = scrapy.Field()
再在爬虫文件(DDsipder.py)编辑爬虫代码,在这里我们首先分析要爬取的网页的HTML:
http://category.dangdang.com/cp01.16.00.00.00.00.html
#这是当当网两性书籍的第一页的网址
http://category.dangdang.com/pg2-cp01.16.00.00.00.00.html
#这是当当网两性书籍的第二页的网址,我们可以发现第一页和第二页主要少了一个"pg2-"
#将第一页的网址改成:
http://category.dangdang.com/pg1-cp01.16.00.00.00.00.html
#打开此网址,我们发现这就是当当网的两性书籍的第一页。所以可以判定,每一个只是pg后的值不一样
'''
<a class="pic" title=" 男人来自火星,女人来自金星(1-4套装)(升级版) " ddclick="act=normalResult_picture&pos=23706011_0_2_p" name="itemlist-picture" dd_name="单品图片" href="http://product.dangdang.com/23706011.html" target="_blank">
'''
#注意看网页的信息,title里的是书的名字,href里的是书的链接
#所以这里书名、书链接的xpath路径是 //a[@class="pic"]/@title、//a[@class="pic"]/@href
#所有class="pic"的a标签下的title属性对应的值,以及href对应的值
#<span class="search_now_price">¥82.80</span>
#书的价格的xpath的路径是 //span[@class="search_now_price"]/text()
#所有class="search_now_price"的span标签的内容文本
'''
<a href="http://search.dangdang.com/?key2=约翰格雷&medium=01&category_path=01.00.00.00.00.00" name="itemlist-author" dd_name="单品作者" title="[美]约翰格雷 博士 著">约翰格雷</a>
'''
#书的作者的xpath的路径为 //a[@dd_name="单品作者"]/text()
#所有的dd_name="单品作者"的a标签下的内容文本分析完我们要的数据的xpath后,可以进行爬虫文件的编写:
# -*- coding: utf-8 -*-
import scrapy
from DDrun.items import DdrunItem
from scrapy.http import Request
class DdsipderSpider(scrapy.Spider):
name = 'DDsipder'
allowed_domains = ['dangdang.com']
start_urls = (r'http://category.dangdang.com/pg1-cp01.16.00.00.00.00.html',)
def parse(self, response):
item = DdrunItem()
item['title'] = response.xpath(r"//a[@class='pic']/@title").extract()
item['link'] = response.xpath(r"//a[@class='pic']/@href").extract()
item['price'] = response.xpath(r"//span[@class='search_now_price']/text()").extract()
item['author'] = response.xpath(r"//a[@dd_name='单品作者']/text()").extract()
#提取完后返回item
yield item
#通过循环自动爬取19页的数据
for i in range(1,20):
url = "http://category.dangdang.com/pg"+str(i)+"-cp01.16.00.00.00.00.html"
#通过yield返回Request,并指定要爬取的网址和回调函数
yield Request(url,callback = self.parse)再接着打开piplines,编写代码对得到的item进行处理:
# -*- coding: utf-8 -*-
import codecs
import json
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class DdrunPipeline(object):
def __init__(self):
self.file = codecs.open(r"F:\anacon\spider_scrapy\DDrun\dangdang2.json","wb",encoding = "utf-8")
def process_item(self, item, spider):
for j in range(0,len(item["title"])):
name = item["title"][j]
price = item["price"][j]
author = item["author"][j]
link = item["link"][j]
first_dict = {"name":name,"price":price,"author":author,"link":link}
i = json.dumps(dict(first_dict), ensure_ascii=False)
line = i + '\n'
self.file.write(line)
return item
def close_spider(self,spider):
self.file.close()编写完pipelines后,需要在settings.py内将piplines功能打开,找到代码,将注释去掉后如下。
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'DDrun.pipelines.DdrunPipeline': 300,
}也可以在中间件middlewares内编辑代理用户和访问IP:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
import random
from DDrun.settings import IPPOOL
from DDrun.settings import UAPOOL
from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
class IPPOOLS(HttpProxyMiddleware):
def __init__(self,ip=''):
self.ip = ip
def process_request(self,request,spider):
thisip = random.choice(IPPOOL)
print("当前使用的IP是:"+thisip['ipaddr'])
request.meta["proxy"] = r"http://"+thisip["ipaddr "]
class UAPOOLS(UserAgentMiddleware):
def __init__(self,ua=''):
self.ua = ua
def process_request(self,request,spider):
thisua = random.choice(UAPOOL)
print("当前使用的用户代理是:"+thisua)
request.headers.setdefault('User-Agent',thisua)那么这样的话也需要在settings.py内编辑IP和代理用户,以及打开对应的功能
IPPOOL = [
{'ipaddr':'116.18.228.55'}
]
UAPOOL = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0',
"Mozilla/5.0 (Windows NT 6.1; rv:48.0) Gecko/20100101 Firefox/48.0",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.5"
]
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
#'DDrun.middlewares.MyCustomDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':123,
'DDrun.middlewares.IPPOOLS':125
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':2,
'DDrun.middlewares.UAPOOLS':1
}但是发现一个问题,这个IP访问当当网不成功啊,没办法下载网页信息,链接失败,无响应等各种问题。最后把IP的功能关闭,就可以正常访问了。
还需要在settings.py里将cookie和遵守爬虫规则的选项关闭:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Disable cookies (enabled by default)
COOKIES_ENABLED = False在cmd下运行爬虫:
scrapy crwal DDsipder --nolog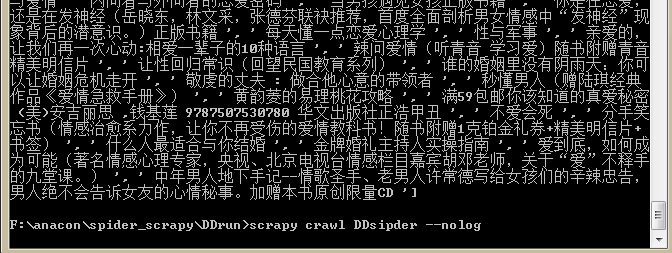
在目录下打开生成的文件















 2066
2066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









