







一、概要介绍
Xcache完整实现了Spring cache接口的本地/远程组合缓存框架,支持使用Spring cache注解,并在Spring cache的基础上扩展了以下功能:
1. 缓存List:通过缓存List<Id>的方式降低内存占用和保证数据唯一。
2. 关联缓存:username→ID→user,username与ID关联,ID与user关联。
3. 缓存版本:远程版本等于本地版本返回本地缓存,远程版本大于本地版本返回远程缓存。
4. Spring自带的ConcurrentMapCache无缓存清理策略,因此扩展了ConcurrentHashMap作为本地缓存,实现了可配置的LRU缓存淘汰算法。本地缓存可以根据需要替换为其它实现了SpringCache接口的缓存框架,譬如Ehcache。
5. 远程缓存采用Redis作为存储仓库,但未采用Spring自带的RedisCache(原因后面再谈),而是封装Jedis作为缓存实现,支持RedisCluster和RedisSingleServer。
二、缓存使用问题与框架设计思考
缓存几乎是每个服务端应用必备,即使是单服务器低流量的应用,使用缓存也能加快响应速度,提升用户体验。但在缓存使用过程中,可能会遇到以下问题:
1. 单纯使用集中式的远程缓存,高并发时网络传输压力过大,响应速度变慢。
如仅仅是缓存数据记录,而不是缓存整个页面,大多数情况下,通过提升网络配置,数据分应用分片缓存,这并不会成为问题(电商类和新闻类的网站是例外)。但因为CPU处理速度远超网络速度,当数据访问量大到一定程度,网络一定会成为瓶颈,因此增加本地缓存是必然。
2. 本地缓存和远程缓存双缓存,本地缓存与远程缓存的数据不一致。
如果增加本地缓存,必然会出现远程缓存更新后本地缓存未更新的情形,解决方式主要有被动接收通知和主动获取更新两种。
2.1 被动接收通知:消息广播。
优点:只需在数据变化时与远程缓存服务器或者数据库进行一次通讯,通信次数少效率高。
缺点:消息意外丢失导致数据未更新、消息接收延迟导致数据短暂不一致。如果某个服务器节点因为网络原因或者MQ中间件Bug导致一直未能接收到消息,那么该节点将一直使用本地缓存的旧数据,直到数据过期为止。
或许zookeeper的watch机制会是一个其它选择?但在复杂的缓存策略下代码实现会比较复杂,且zookeeper的性能可能会是一个瓶颈?
2.2 主动获取更新:定时轮询。通过定时线程从数据库或者远程缓存拉取数据。 优点是通信次数少。缺点:数据更新频率低,多服务器同时更新缓存会出现性能问题,适合一些很久都不会变化的数据。
以上两种方案都会出现本地缓存数据未能及时更新问题,但消息广播方式比定时轮询要好。当然,可以采用消息广播为主,定时轮询为辅双策略来实现缓存数据更新。
2.3 主动获取更新:版本比对。通过增加版本机制,每次返回本地缓存数据前主动比对远程缓存的版本。
优点:每次网络传输由整条数据变成仅传输版本号,降低了网络传输的数据量。
缺点:网络通信次数多,比消息广播方式的响应延迟要高;对网络环境依赖较重,一般来说设计为远程缓存不可用则本地缓存不可用;编程实现比较复杂。
3. 缓存命名混乱,可能出现缓存冲突。
如果没有缓存使用规范和缓存框架设计,每个程序员随意命名,要么会出现缓存命名冲突,导致缓存获取的数据并非想要的数据。要么是使用非常复杂怪异冗长的名字作为Key,那么很可能Key的字节数要远大于数据本身的字节数,浪费大量的内存空间。
4. 缓存使用随意,积压大量无用数据。
没有过期策略,过期时间由程序员随意指定或者干脆没有设置过期;或者选择不合理的数据结构,性能差,Key数量多且混乱,无法清理无效数据,导致缓存速度降低或缓存服务不可用,不得不彻底清空缓存。
5. 数据库数据与缓存数据不一致。
因为数据库和缓存并非同一份数据,所以一定会存在不一致,只是时间长短的问题。只要运行速度足够快,操作间隔足够短,那么一定会读取到过期数据,除非为了强一致性选择牺牲性能,具体说明等下一点的设计解析中再画图详解。
三、Xcache设计解析
1. 缓存数据保存/更新流程
![]()
2. 缓存数据读取流程

3. 可能的数据不一致性分析
步骤1:
线程1执行更新数据,线程2执行读取数据,线程3执行读取数据。
数据版本:远程缓存1,本进程缓存1,其它进程缓存1,数据库1。
步骤2:
线程1执行到删除远程缓存之后更新数据库之前;
数据版本:远程缓存null,本进程缓存null,其它进程缓存1或null,数据库版本1。
步骤3:
线程2发现远程缓存被删除,执行数据库读取数据并存入远程缓存和本地缓存;
数据版本:远程缓存1,本进程缓存1,其它进程缓存1或null,数据库版本1。
步骤4:
线程1执行到更新数据库之后,更新远程缓存之前。
数据版本:远程缓存1,本进程缓存1,其它进程缓存1或null,数据库版本2。
步骤5:
线程3执行到读取本地缓存并比较远程缓存,版本一致,返回版本1的旧数据。
数据版本:远程缓存1,本进程缓存1,其它进程缓存1或null,数据库版本2。
步骤6:
线程1执行到更新远程缓存和本地缓存,并返回版本2的新数据。
数据版本:远程缓存2,本进程缓存2,其它进程缓存1或null或2,数据库版本2。
结论:
线程1更新数据库后,任意进程/线程更新远程缓存前,其它进程/线程得到的均为旧版本数据。如果要实现强一致性,那么就只能牺牲性能,通过分布式锁机制,保证只有写入线程更新远程缓存之后才能访问缓存数据,但代价太过昂贵。
版本管理方式比消息广播方式只能降低不一致性的可能和延迟,但无法从根本上解决一致性问题。
因此,程序不能依赖于缓存数据的正确性来处理关键业务逻辑,只能用于非关键数据。
4. 保存数据时的版本问题
线程1、线程2、线程3依次更新数据库完毕,线程1版本1,线程2版本2,线程3版本3。
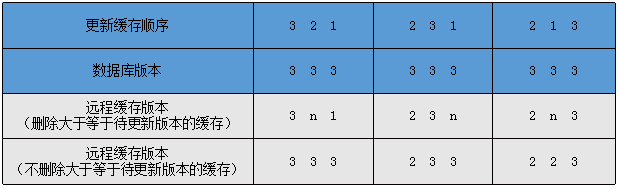
从上面图示可知,各线程以逆序方式更新缓存时,发现缓存版本大于等于本线程携带的数据版本:
⑴ 如果选择删除远程缓存,那么远程缓存的版本将会成为1,直到下一次数据更新之前一直会返回旧数据。
⑵ 如果选择不删除远程缓存:线程1和线程2选择返回远程缓存的版本,会出现用户明明设定年龄为18,但因为其它线程更新为17,结果返回年龄为17的情形,与用户预期不符;选择返回本线程携带的数据,就会出现明明数据库已经是年龄为17岁,但依然返回年龄为18岁的情形;选择抛出版本错误异常,业务层面自行判断处理,但这种取舍更为难,业务层面重新更新数据库会导致旧数据覆盖新数据,业务层面捕捉异常但不处理,那么异常抛出其实无任何作用。
因此,Xcache的最终选择是容许部分线程返回的数据版本过旧,不删除大于等于当前要更新版本的缓存数据,否则极有可能最终所有其它线程/进程始终读取到旧数据,同时也与用户当次操作的结果预期相符。
四、Xcache编码实现遇到的问题和取舍
1. 关于RedisCache
Spring Data Redis有Redis缓存的具体实现——RedisCache,使用实现RedisOperations接口的具体类来作为Redis客户端操作类,如RedisTemplate。但RedisCache不支持版本管理,也不支持消息广播,所以作为本地缓存+远程缓存的组合实现并不适合。
为什么不选择RedisCache作为缓存数据存取,用RedisTemplate来辅助管理版本呢?我写了一个XcacheBasic,但有很多问题:获取远程缓存数据至少要两次远程通信;RedisCache 关于Redis集群的Cache Clear的实现并不合理;序列化方式不能在在特定用途时做特定处理……
2. 关于序列化方案的选择
我尝试了各种各样的序列化方案和框架,FST、Kryo、MsgPack、Jackson、fastJson、Protobuf……等等,最后选择了使用Json作为主要的序列化方式,使用Jackson作为Json序列化框架。因为需要在Redis服务器端反序列化对象比对版本,而Redis支持通过Lua脚本操作Json。
如果使用额外的HashSet来保存版本则可以避免反序列化对象,但在RedisCluster环境中,数据Key和版本Key通常不会在同一服务器更不会在同一slot,所以会导致二次通信的问题。
Redis支持Lua的MsgPack库来操作二进制数据,MsgPack的二进制序列化方式比Json方式要好,序列化后的字节数更少,序列化的效率更高,但是MsgPack的Java客户端Bug太多,而且已经有近两年没有任何更新发布,经过测试后最终还是放弃。或许以后有时间阅读MsgPack源码的时候再考虑看看。
Json无法准确还原数字类型,所以可能无法得到正确的HashCode,当从Redis中获取到ID时可能无法从本地缓存中找到缓存对象。因此,ID使用FST进行二进制方式的序列化。
3. 关于RedisCluster和JedisCluster
RedisCluster(Redis3.2.8)服务器在使用过程中碰到一些问题,不算是Bug,仅仅是设计方面的权衡:
3.1 Redis返回集群节点状态时,当前客户端所连接的Redis节点的主机IP会返回127.0.0.1,其他节点的IP则正常,导致JedisCluster客户端无法初始化成功。
Redis这是为加快本机客户端的访问速度?还是因为我的虚拟机原因?
3.2 RedisCluster批处理数据时,仅支持操作同一slot的Key,而不是同一个Server的Key,虽然Redis集群规范中说明支持通过hash tags来强制将多个key分配到同一个slot,但Jedis和Lettuce均没有实现此操作。缓存集群本来要将热点数据分散存储,因此即使支持hash tags,也不建议使用。Redis如此保守设计的原因可能是怕原来可以批处理的key在集群状态变更后无法执行,但也会带来通信次数过多的问题,尤其是clear操作。
以上两点JedisCluster没有处理,也没有给出根据slot获取对应服务器的接口。框架或许首先考虑的是正确性和普适性,然后才是灵活度。当然,完全可以改Jedis源码,虽然不难但并不想这么干,改一次源码以后每次Jedis新版本都要改源码,这也是一件挺无趣的事。
JedisCluster采用BIO与RedisServer通信,在RedisCluster节点数量达到一定程度的时候,可能会带来较大的性能消耗。Redis的另一个Java客户端Lettuce使用Netty作为nio通信框架,但在集群支持方面又有较多的问题,好些操作均只写了接口没有具体实现,而且整个代码看起来远远没有Jedis清晰明了。
基于以上原因,我选择自己封装了Jedis单机版客户端来操作Redis集群,而没有采用JedisCluster。JedisClusterClient支持集群状态改变自动发现和处理,对于DEL key[]这样的命令则通过slot找到在同一Redis节点的key,然后通过Lua脚本来批处理,绕过多个key必须同一个slot的限制,否则clear操作在key数量庞大的时候可能会导致几秒甚至几分钟无响应。
因为时间关系,复杂的一些操作并没有实现,仅写了几个缓存需要用到的命令,但扩展命令其实非常简单,只要使用匿名内部类实现RedisCmd接口或者直接写实现类即可。因此,可以将其当作Redis Cluster客户端的简化版,并使用Xcache替代RedisTemplate来操作Redis,方便进行缓存管理。
未来有计划在Jedis的基础上用netty实现一个Redis客户端,这好像是一个好主意?!
4. 关于版本号方案设计
方案一:
通过额外的key来保存数据版本,版本号和数据分开存储。数据库中数据无版本号,每次保存数据时仅在Redis客户端通过Hincrby来递增1。
优点:版本号是独立于数据存在,对于既有的系统无需更改任何代码即可使用Xcache来实现版本管理。
缺点:集群状态下因为Key可能不在同一个Server,需要多一次通信来进行版本递增;更新缓存非原子操作,会出现版本错误问题;Redis需要开启持久化,同时保证有足够的内存避免Redis删除版本Key。如果Redis在更新缓存数据后因为Bug死机没有递增版本,或者其它原因导致版本不正确,那么本地缓存将以为旧数据就是最新数据,始终返回旧数据。
XcacheBasic采用此方案,但已经移出core,因为这种方式有太多无法在代码层解决的问题。
方案二:
数据对象中增加版本。
优点:数据更新和版本更新是原子操作,版本管理方便。
缺点1:原有系统需要增加版本字段才能使用。数据库表设计本就应有版本号和时间戳,用于数据比对合并之类的操作,所以其实并不算是什么问题。增加版本号其实也并不难,只是稍稍麻烦。
缺点2:编码较复杂,需要使用大量的Lua脚本来避免多次通信。缓存逻辑与Lua脚本的关联度较高,因此从程序设计的角度来看并不是太优雅。
XcacheDefault采用的是此方案,建议使用此方案。
五、配置与使用
这里不详细说明如何使用,就是Spring Cache的一些标准配置,具体可以参考Xcache-test,其包含了完整使用示例和一些测试用例,这里只简单介绍。
1、获取缓存Bean
@Autowired
private CacheManager cacheManager;
@PostConstruct
public void construct(){
xcache = (Xcache) cacheManager.getCache("~C_BOOK");
}通过缓存名获取缓存Bean然后进行统一的缓存操作和Redis操作,可以避免Key命名和存活时间混乱的问题。
2. 主要扩展接口
//保存列表到缓存
public <T> void putList(Object key, Object[] values, String idField, Class<T> idType);
//从缓存获取列表
public <E, T> CacheListResult<E, T> getList(Object key, Class<E> idType, Class<T> valueType);
//保存ID关联到缓存
public void putRelation(Object key, Object value, String idField);
//通过ID关联获取缓存对象
public <T> T getRelation(Object key, Class<T> type);
//保存非持久化对象到缓存(必须有存活时间)
public void putOther(Object key, int second, Object value);
//从缓存获取非持久化对象
public <T> T getOther(Object key, Class<T> type);
3. 保存缓存列表示例
xcache.putList(listKey, book[], "id", Long.class);
4. 获取缓存列表示例
CacheListResult<Long, Book> cacheList=xcache.getList(listKey, Long.class, Book.class);
5. 其它
xcache依赖了dcafe项目,这是我写的一个snowflake算法的分布式ID生成器,这里用了它的时间发生器功能,这个项目代码同样保存在github和码云,下载下来编译即可。
Spring标准注解可以正常使用,接下来会开发List注解和Relation注解来支持缓存List和关联缓存。
6. 小感悟
程序的设计在于平衡和取舍,获得了广泛适用性,那么就可能会失去部分灵活性;消除了复杂度,那么可能就会损耗部分性能。而架构设计的功力,很大一部分就在于如何作出取舍。
Spring、Hibernate追求大而全,试图解决所有通用性的问题,通过不断地追加层来封装扩展,整体框架设计就会变得复杂繁冗。
Redis的源码则非常的清晰简洁,通过五种最基本的数据结构,构建出了非常高效稳定的缓存系统。看其源码,完全找不到一点多余的设计和一句没用的代码,简直优雅到令人发指。
这两者无孰优孰劣之分,只是设计初衷和所解决问题类型不同,但我非常喜欢Redis这样的设计。
这是半年来看源码并写了几个小框架后的小感悟,与君分享。
Xcache刚刚完成,虽然跑通了好些测试,但一定会有Bug和不合理的设计,欢迎反馈!如果能够提一些建议和指出Bug,则不甚感激!谢谢!
项目地址:
Github:https://github.com/tonylau08/xcache
码 云:http://git.oschina.net/null_737_6953/xcache
项目介绍:https://my.oschina.net/xcafe/blog/856638
作者:Xcafe
项目依赖:
spring-context
dcafe-snowflake
jedis
fst
jackson















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









