







原文作者:aircraft
原文链接:https://www.cnblogs.com/DOMLX/p/9780786.html
有没有大佬们的公司招c++服务端开发实习的啊,带上我一个呗QAQ
最近秦老师叫我研究深度学习与指静脉结合,我就拿这篇来做敲门砖,并且成功将指静脉的纹理特征提取用u-net实现了,而眼球血管分割则给我提供了很大的帮助。现在就分享给大家吧。。
DRIVE数据集下载百度云链接:链接:https://pan.baidu.com/s/1C_1ikDwexB0hZvOwMSeDtw
提取码:8m1q
U-net+kears实现眼部血管分割源码python2.7版本的百度云链接:链接:https://pan.baidu.com/s/1C_1ikDwexB0hZvOwMSeDtw
提取码:8m1q
U-net+kears实现眼部血管分割源码python3.6版本的百度链接:链接:https://pan.baidu.com/s/1rAf6wuWGCswuBfkDivxjyQ
提取码:rtdg
全卷积神经网络
大名鼎鼎的FCN就不多做介绍了,这里有一篇很好的博文 http://www.cnblogs.com/gujianhan/p/6030639.html。
不过还是建议把论文读一下,这样才能加深理解。
医学图像分割框架
医学图像分割主要有两种框架,一个是基于CNN的,另一个就是基于FCN的。这里都是通过网络来进行语义分割。
那么什么是语义分割?可不是汉字分割句意,在图像处理中有自己的定义。
图像语义分割的意思就是机器自动分割并识别出图像中的内容,比如给出一个人骑摩托车的照片,机器判断后应当能够生成右侧图,红色标注为人,绿色是车(黑色表示 back ground)。

所以图像分割对图像理解的意义,就好比读古书首先要断句一样。
在 Deeplearning 技术快速发展之前,就已经有了很多做图像分割的技术,其中比较著名的是一种叫做 “Normalized cut” 的图划分方法,简称 “N-cut”。
N-cut 的计算有一些连接权重的公式,这里就不提了,它的思想主要是通过像素和像素之间的关系权重来综合考虑,根据给出的阈值,将图像一分为二。
基于CNN 的框架
这个想法也很简单,就是对图像的每一个像素点进行分类,在每一个像素点上取一个patch,当做一幅图像,输入神经网络进行训练,举个例子:
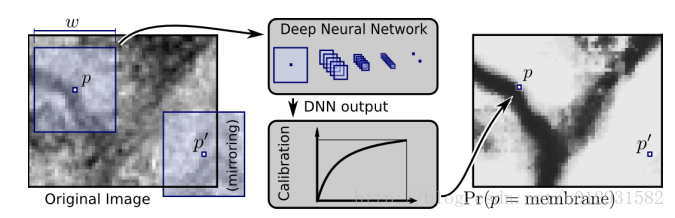
这是一个二分类问题,把图像中所有label为0的点作为负样本,所有label为1的点作为正样本。
这种网络显然有两个缺点:
1. 冗余太大,由于每个像素点都需要取一个以本身为中心patch,那么相邻的两个像素点的patch相似度是非常高的,这就导致了非常多的冗余,导致网络训练很慢。
2. 感受野和定位精度不可兼得,当感受野选取比较大的时候,后面对应的pooling层的降维倍数就会增大,这样就会导致定位精度降低,但是如果感受野比较小,那么分类精度就会降低。
CNN 存在很久了,但是一直受限于过大的数据量和神经网络的规模,并没有获得很大的成功,直至 Krizhevsky 才开始爆发。但是将 CNN 用于生物医学图像存在着两点困难,首先CNN常用于分类,但是生物医学往往关注的是分割之类的定位任务;其次医学图像很难获得那么大规模的数据
以往解决上面两点困难的方法是使用滑窗的方法,为每一个待分类的像素点取周围的一部分邻域输入。这样的方法有两点好处,首先它完成了定位的工作,其次因为每次取一个像素点周围的邻域,所以大大增加了训练数据的数量。但是这样的方法也有两个缺点,首先通过滑窗所取的块之间具有较大的重叠,所以会导致速度变慢(由FCN的论文分析可知,前向传播和反向传播的速度都会变慢);其次是网络需要在局部准确性和获取上下文之间进行取舍。因为更大的块需要更多的池化层进而降低了定位的准确率,但是小的块使网络只看到很小的一部分上下文。现在一种常见的作法是将多个层放在一起进行考虑(比如说FCN)。
基于FCN框架
在医学图像处理领域,有一个应用很广泛的网络结构—-U-net ,网络结构如下:
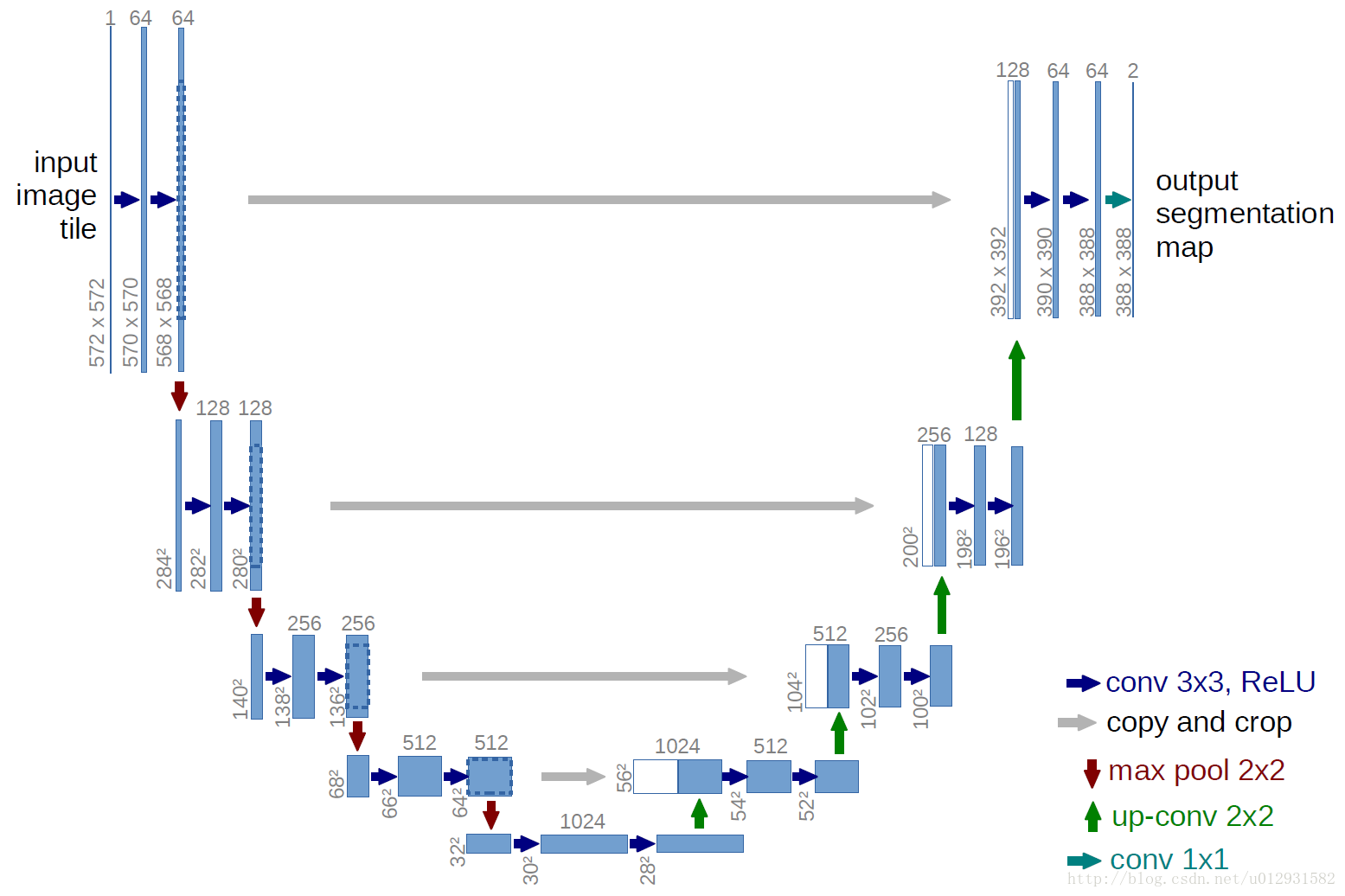
它包含重复的2个3x3卷积,紧接着是一个RELU,一个max pooling(步长为2),用来降采样,每次降采样我们都将feature channel减半。扩展路径包含一个上采样(2x2上卷积),这样会减半feature channel,接着是一个对应的收缩路径的feature map,然后是2个3x3卷积,每个卷积后面跟一个RELU,因为每次卷积会丢失图像边缘,所以裁剪是有必要的,最后来一个1x1的卷积,用来将有64个元素的feature vector映射到一个类标签,整个网络一共有23个卷积层。
可以看出来,就是一个全卷积神经网络,输入和输出都是图像,没有全连接层。较浅的高分辨率层用来解决像素定位的问题,较深的层用来解决像素分类的问题。
好了理解完U-net网络,我们就学习一下怎么用U-net网络来进行医学图像分割。
U-net+kears实现眼部血管分割
原作者的【英文说明】https://github.com/orobix/retina-unet#retina-blood-vessel-segmentation-with-a-convolution-neural-network-u-net
实现环境可直接看这篇博客下载:2018最新win10 安装tensorflow1.4(GPU/CPU)+cuda8.0+cudnn8.0-v6 + keras 安装CUDA失败 导入tensorflow失败报错问题解决
linux下就环境一样,配置就要自己去找了。
1、介绍
为了能够更好的对眼部血管等进行检测、分类等操作,我们首先要做的就是对眼底图像中的血管进行分割,保证最大限度的分割出眼部的血管。从而方便后续对血管部分的操作。
这部分代码选用的数据集是DRIVE数据集,包括训练集和测试集两部分。眼底图像数据如图1所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









