







本文参考韦玮的《精通Python网络爬虫》
在windows上安装scrapy,可以打开cmd,输入pip install scrapy,会自动安装最新版的scrapy。也可以参考http://scrapy-chs.readthedocs.io/zh_CN/0.22/intro/install.html。
但是安装后使用过程中发现有问题,就是,使用如下命令创建一个名为myxml的爬虫项目时,cmd显示,“scrapy不是一个内部或外部命令”。无法创建,经过百度,参考该文章。
scrapy startproject myxml使用命令对之前安装的scrapy进行卸载:
pip uninstall scrapy去scrapy的官网,下载源码包:
下载后是一个.zip的压缩包,解压,打开解压的文件夹,按住shift键的同时,点击鼠标右键,点击“在此处打开命令窗口”,使用命令进行安装。
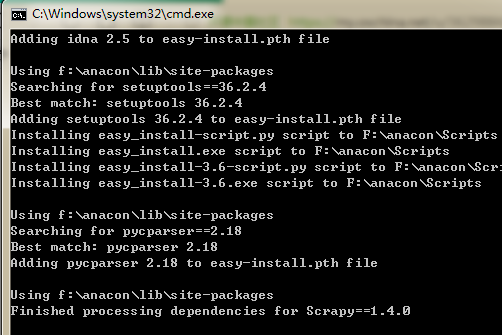
python setup.py install可以看到如下信息即代表安装成功:
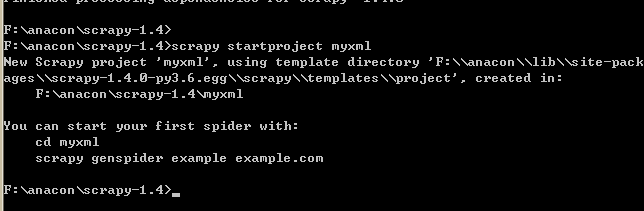
使用命令:scrapy startproject myxml创建一个名为myxml的爬虫项目
打开该目录可以看到以下文件
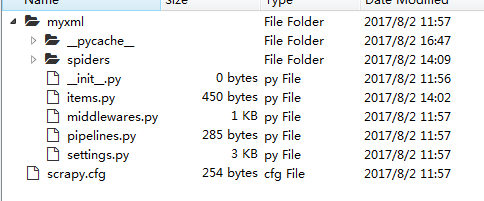
myxml/__inint__.py是项目的初始化文件,主要写的是一些项目的初始化信息。
myxml/items.py是爬虫项目的数据容器文件,主要用来定义我们要获取的数据。
myxml/middlewares.py是爬虫项目的中间件文件,像user-agent,IP池的都可以在其中进行设置。
myxml/pipelines.py是爬虫项目的管道文件,主要用来对items里面定义的数据进行进一步的加工与处理。
myxml/settings.py是爬虫项目的设置文件,主要为爬虫项目的一些设置信息。
myxml/scrapy.cfg是爬虫项目的配置文件。
myxml/spiders/__init__.py是爬虫项目的爬虫部分的初始化文件。
myxml/spiders内一般还有你用命令生成的爬虫模版或者你修改好的爬虫成品。
scrapy常用命令:
scrapy startproject xxxxxx#创建一个名为xxxxxx的爬虫项目
scrapy genspider -l#注意是英文的l不是数字1,查看当前可以使用的爬虫模版
scrapy crawl xxx #启动一个名为xxx的爬虫
scrapy bench#会创建一个本地服务器并以最大的速度进行爬取,测试本地硬件的性能
scrapy check xxxx#对名为xxxx的爬虫文件进行合同(契约)检查
scrapy list#可以列出当前可以使用的爬虫文件
scrapy Edit#打开对应的编辑器对爬虫文件进行编辑
scrapy Parse#可以获取指定的URL网址,并使用对应的爬虫文件进行处理和分析
等等......爬取一个新浪博客RSS订阅文件中的对应信息:
使用的是之前创建的myxml文件,首先设置Items:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class MyxmlItem(scrapy.Item):
#MyxmlIten是Item的子类
# define the fields for your item here like:
# name = scrapy.Field()
#实例化
#存储文章标题
title = scrapy.Field()
#存储对应的链接
link = scrapy.Field()
#存储对应文章的作者
author = scrapy.Field()
接着生成一个爬虫文件,使用命令:
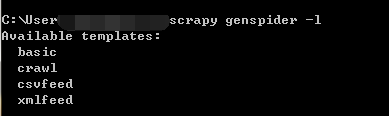
看到我们可以使用的爬虫模版有basic、crawl、csvfeed和xmlfeed。
再使用命令:
scrapy genspider -t xmlfeed Myxml sina.com.cn因为要分析xml源,所以爬虫模版使用的是xmlfeed,sina.com.cn是允许的域名。创建后在spiders目录下打开该.py文件(这边是Myxmlspider.py)进行编辑。
# -*- coding: utf-8 -*-
from scrapy.spiders import XMLFeedSpider
from myxml.items import MyxmlItem
class MyxmlspiderSpider(XMLFeedSpider):
name = 'myxmlspider'
allowed_domains = ['sina.com.cn']
start_urls = ['http://blog.sina.com.cn/rss/1615888477.xml']
iterator = 'iternodes' # you can change this; see the docs
itertag = 'rss' # change it accordingly
def parse_node(self, response,node):
i =MyxmlItem()
i['title'] = node.xpath("/rss/channel/item/title/text()").extract()
i['link'] = node.xpath("/rss/channel/item/link/text()").extract()
i['author'] = node.xpath("/rss/channel/item/author/text()").extract()
for j in range(len(i['title'])):
print("第"+str(j+1)+"篇文章")
print("标题是:")
print(i['title'][j])
print("对应的链接是:")
print(i['link'][j])
print("对应的作者是:")
print(i['author'][j])
print('.................')
return i
运行后显示:
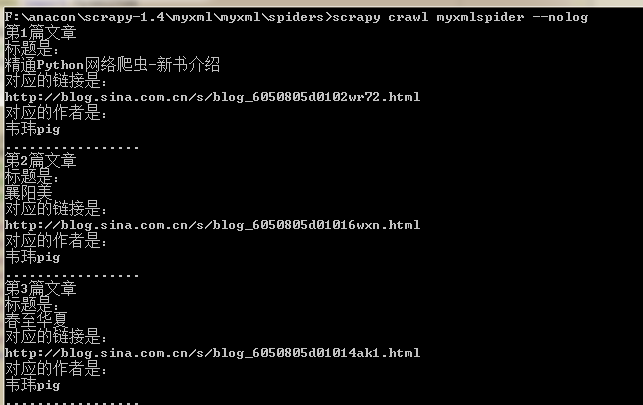














 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









