







- 背景介绍
公司核心系统,由于时间比较久远,现在已经非常臃肿,系统为了对请求作出快速的响应,所以会加载一些数据到内存里,这就是问题所在,现在这些数据已经占到了4G多,但是领导要求不能做太大的改动,只能一点一点分析原因并解决。
- 问题初步猜测
一开始觉得内存占用比较多可以考虑将冷热数据分开,所以做了二级缓存,将冷数据放到了redis中,热数据使用guava cache,存在系统内存中,改造之后,内存占用变成了2G,但是还是感觉有点不对劲,因为这份元数据的真实大小其实只有500M,那剩下的内存都消耗在哪里呢?
线上系统的几个主要的类加起来会有15个实例左右(系统用的Vertx,跟spring还是有点差别的,类的实例都是自己控制个数),每个实例,都会有一份元数据。
本机测试1个实例:
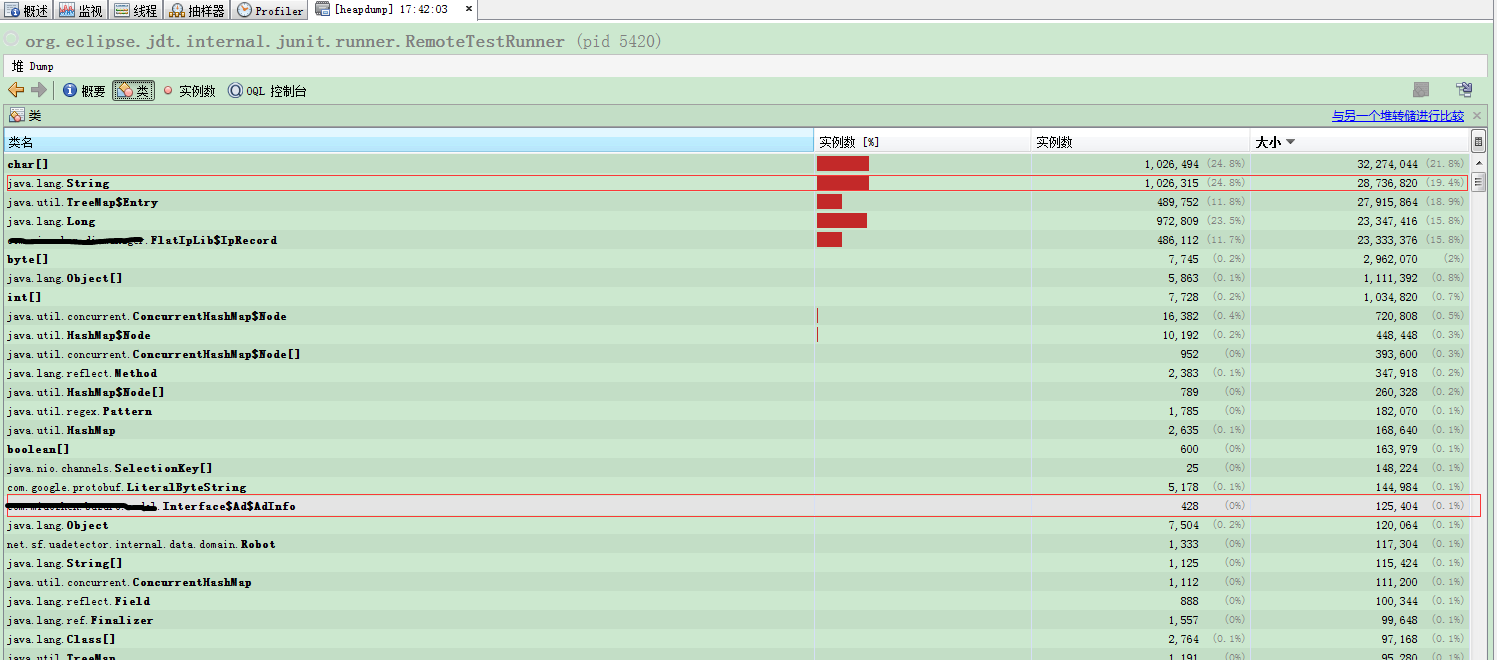
本机测试2个实例:
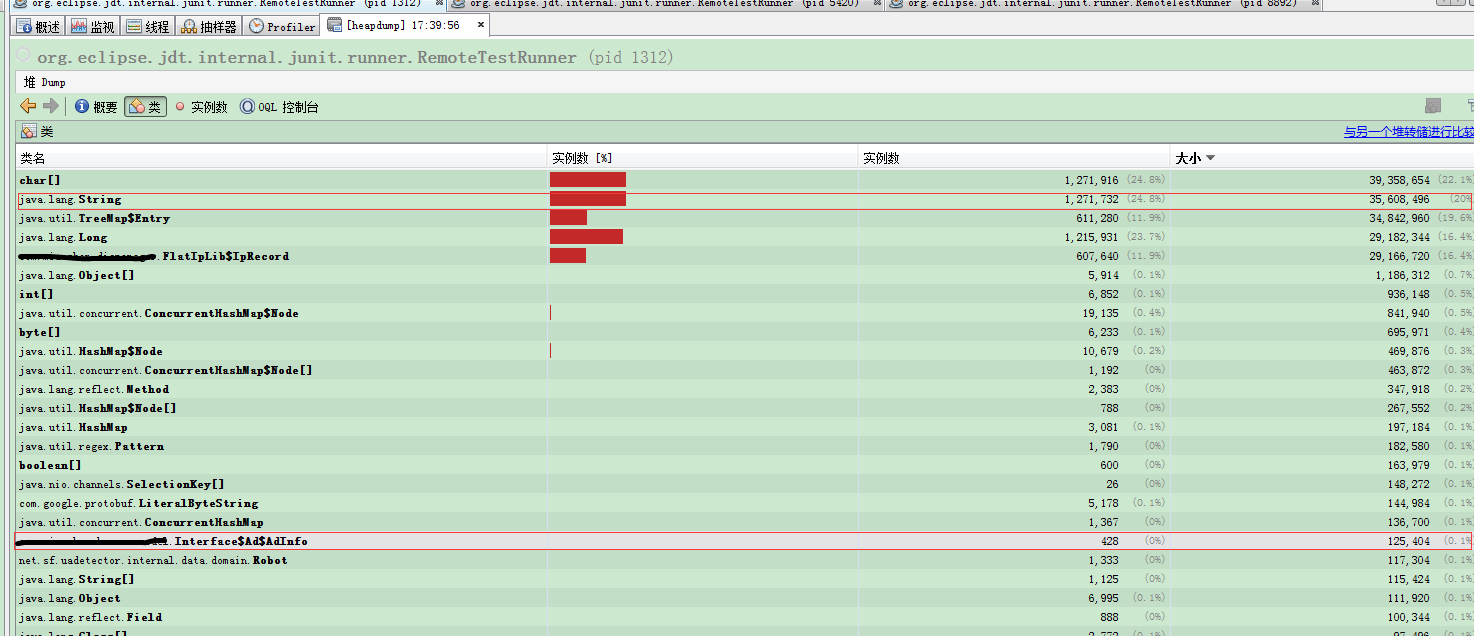
本机测试7个实例:
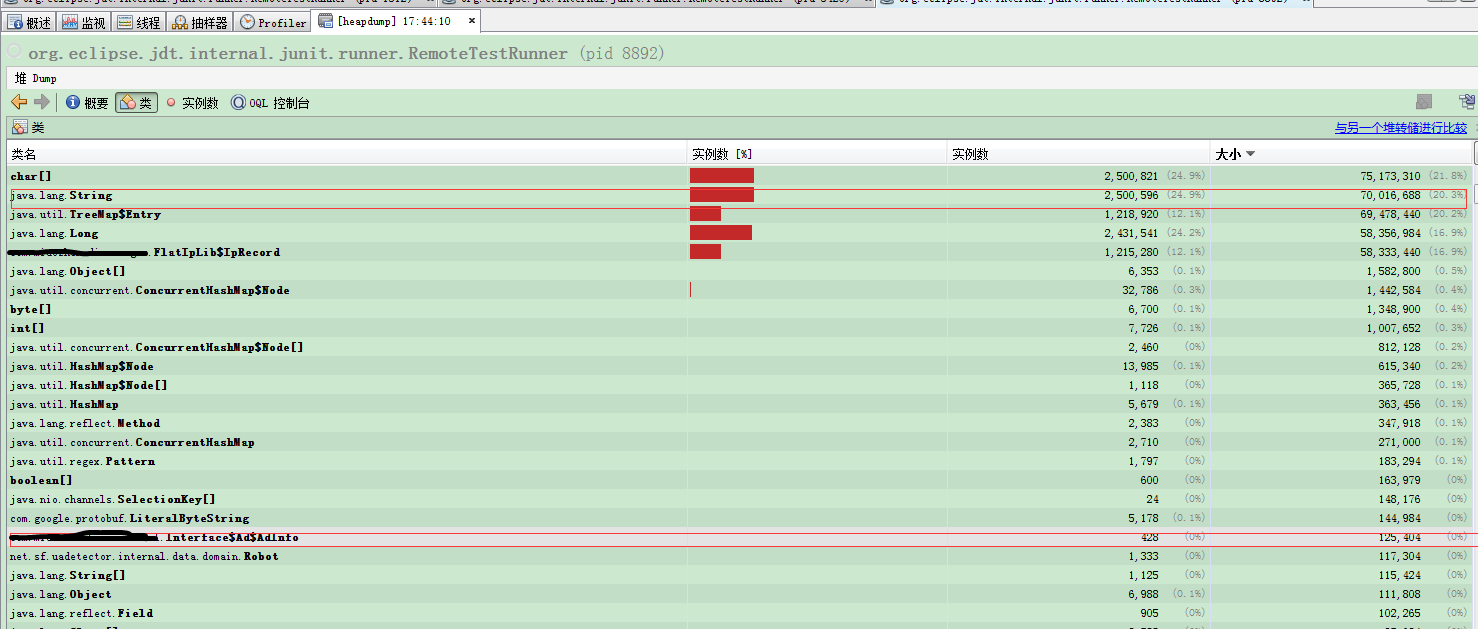
根据jvisualvm分析,元数据对象在内存中其实就只有一份,但是随着实例数的增加,String的数量再不断增加,根据代码,元数据的存储方式都是使用Map,Key基本上都是使用的是String,由此推断,线上内存大多数都被Map的Key占用了,由于本机数据较少,不太明显,所以打算使用线上数据分析。
- 线上数据分析
由于线上数据比较多,不能导出拿到本机上直接分析,所以考虑使用线上服务器分析完,本地查看分析结果。
- 线上使用jmap导出堆数据
 7个G,还真不小{哭笑}
7个G,还真不小{哭笑} - 下载MAT,并分析
- MAT分析完,会有很多文件
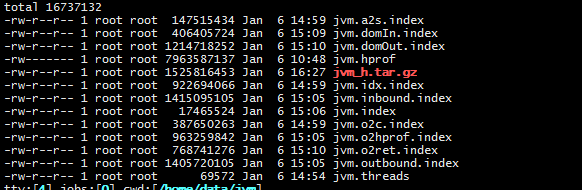
将这些文件打包回传到自己电脑,用Windows版的MAT直接打开hprof文件,这样就可以直接看结果了
- MAT分析结果
- 总体占用
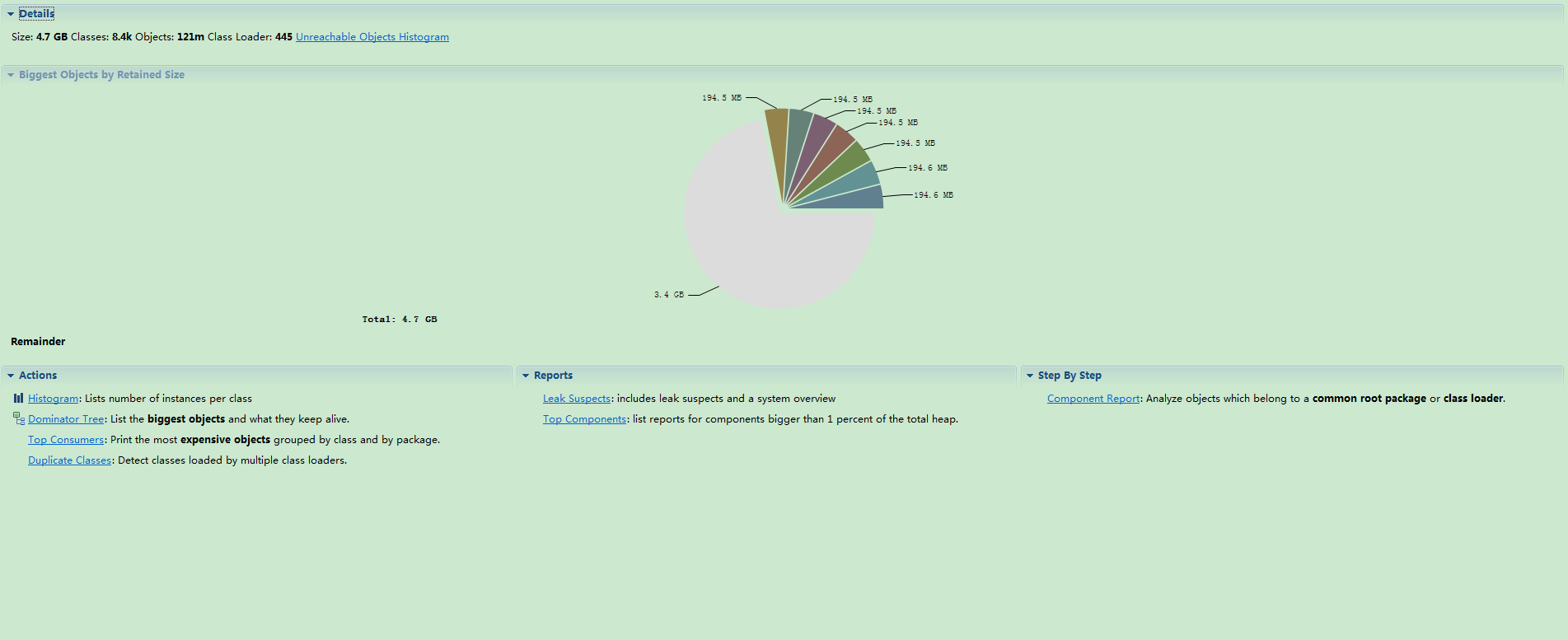
- 点击Leak Suspects MAT会给出内存占用比较多的几个对象
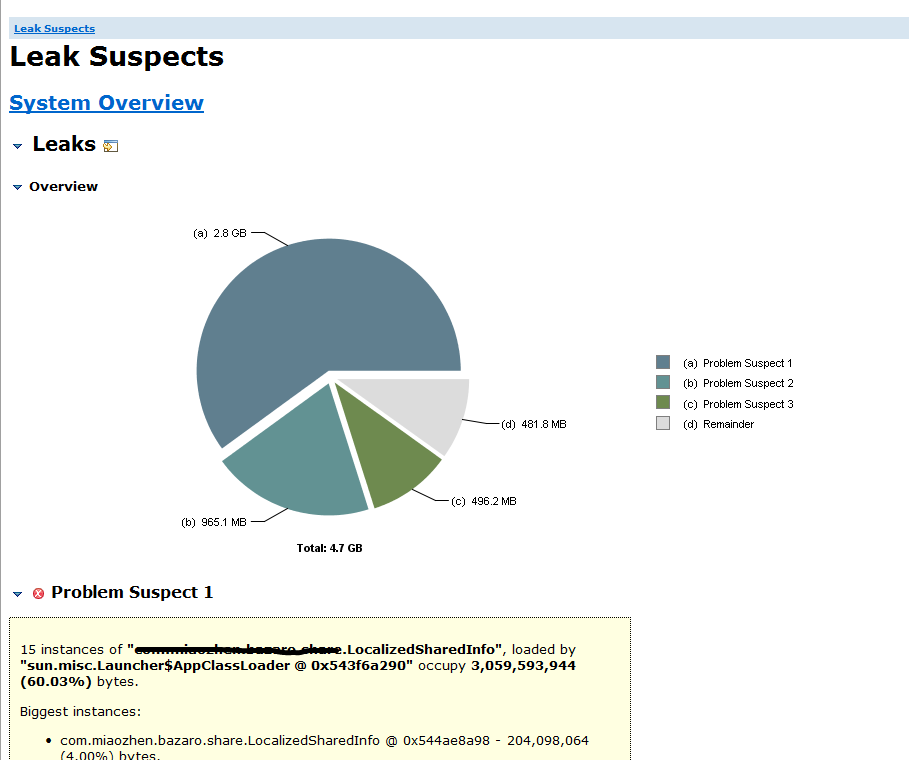
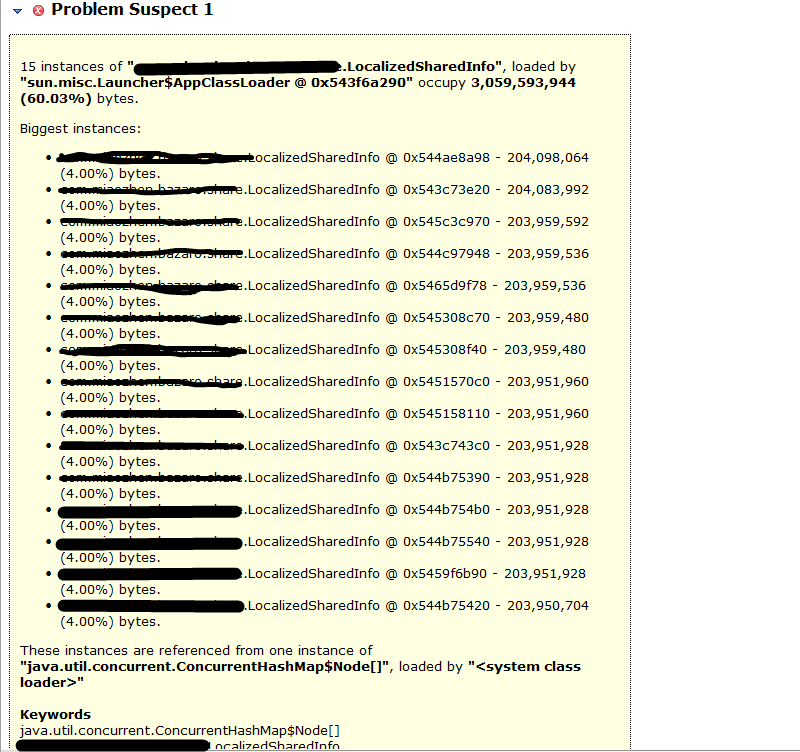
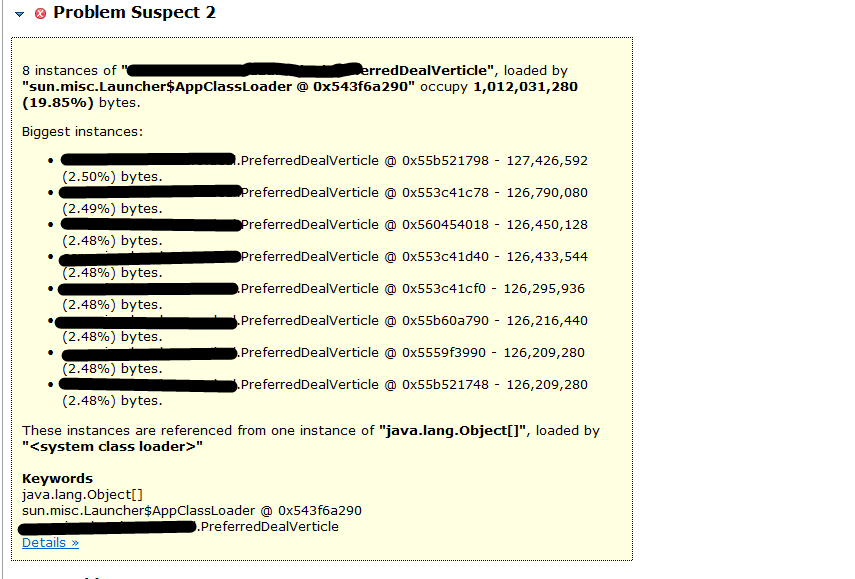
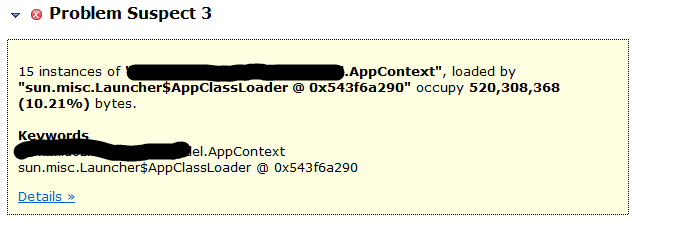
查看具体占用

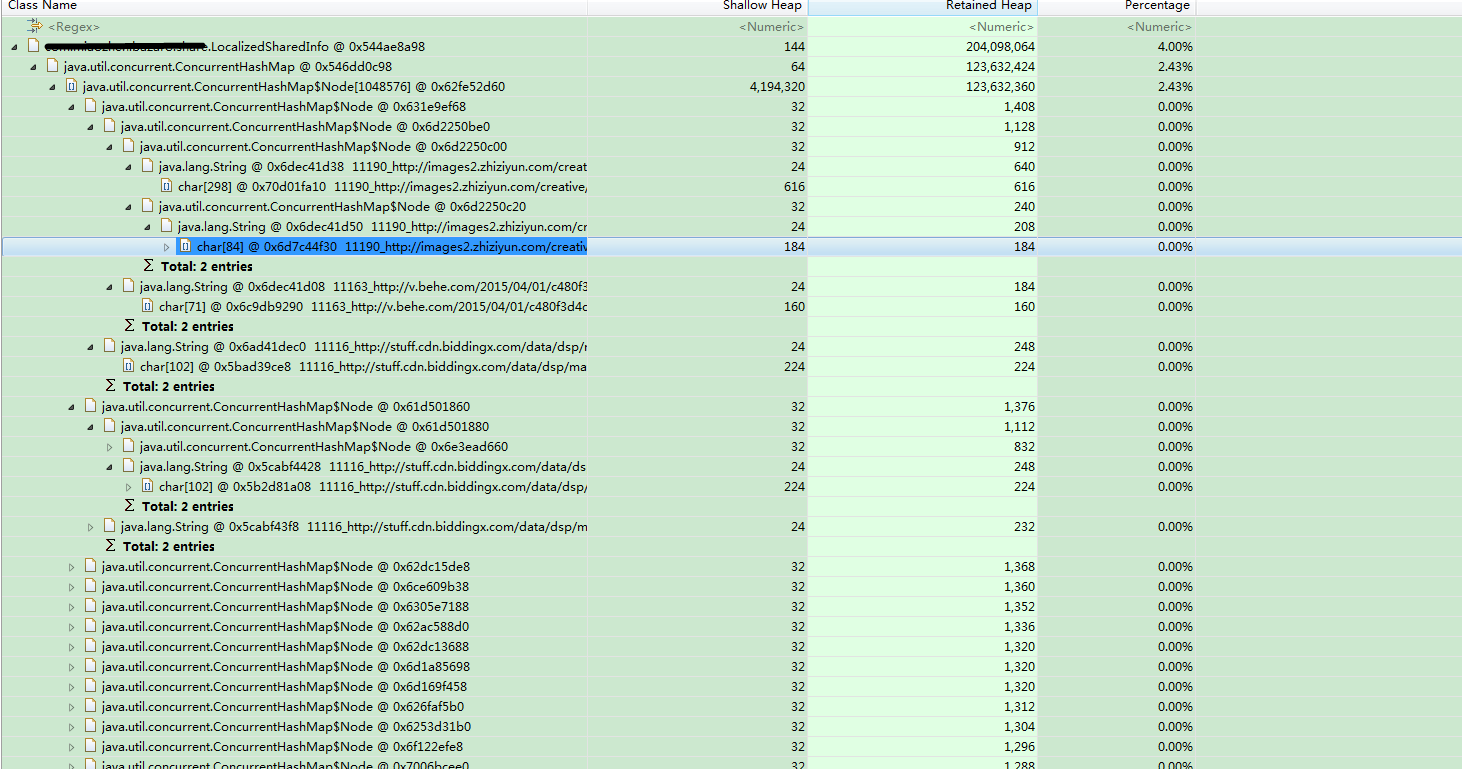
ConcurrentHashMap存储数据的单元其实就是Node,根据这张图就能很明显的看出,每个Node的占用空间最大的就是Key,进一步证实上面的推论
- 分析代码发现,map的key都是用“+”拼接出来的
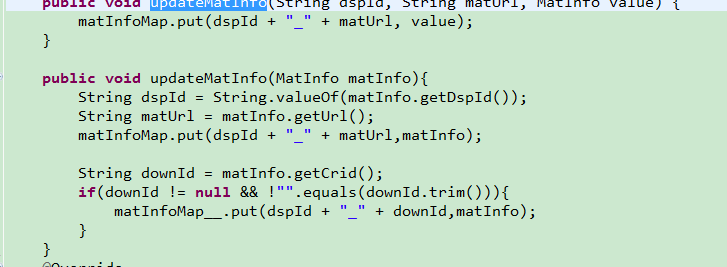
String的拼接其实等于new String,这样即使多个实例的Key的值是一样的,但是在内存中他们并不是同一个
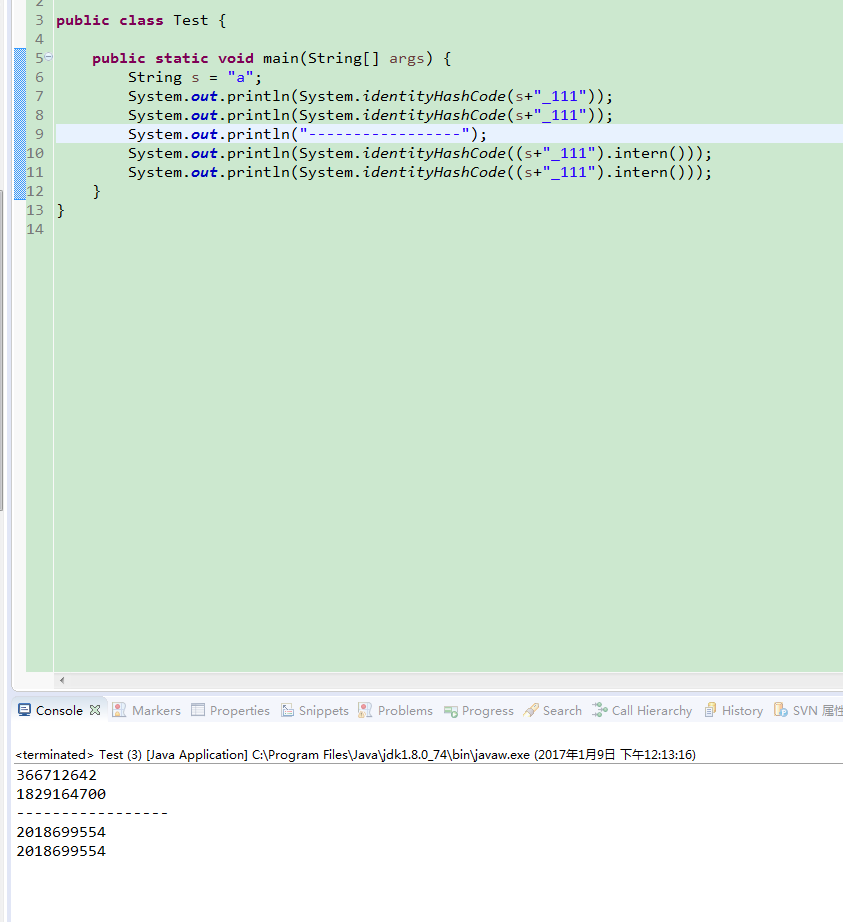
- 改进方案
问题已经分析出来了,改进方案就是每个Key都调用一下String的intern方法
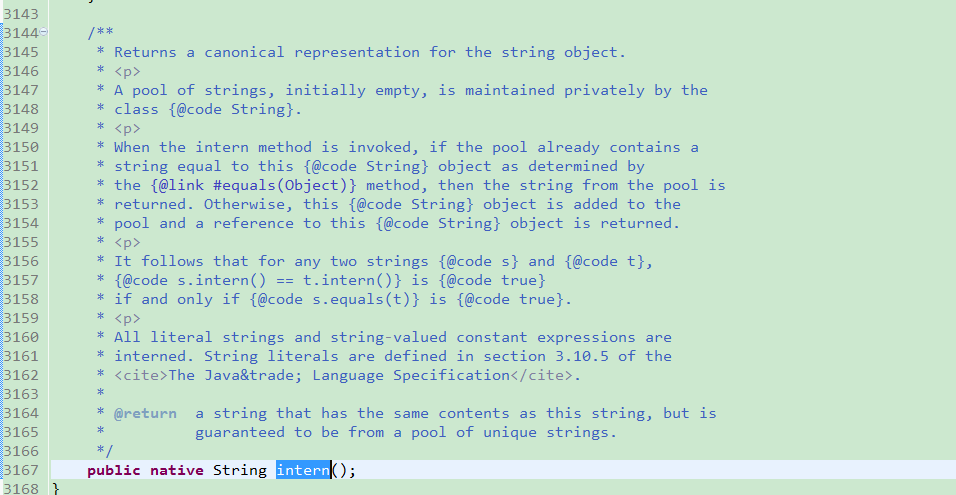
这个方法的大体意思就是,如果String 对象池中有这个值就直接返回引用,如果没有就添加到池中,并且返回
- 改进结果
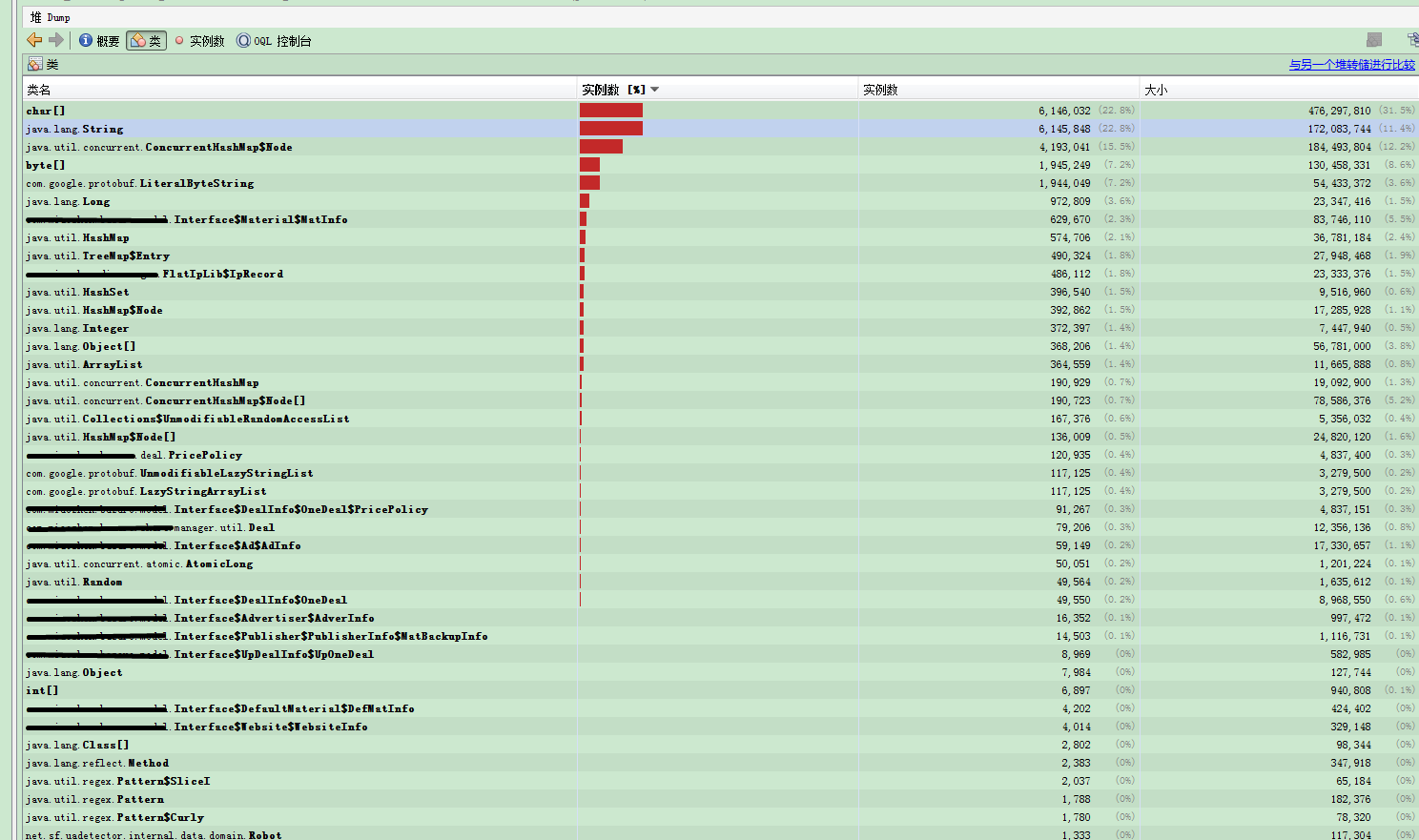
修改前,两个主类实例的内存占用情况(线上数据)
修改后,两个主类实例的内存占用情况(线上数据)
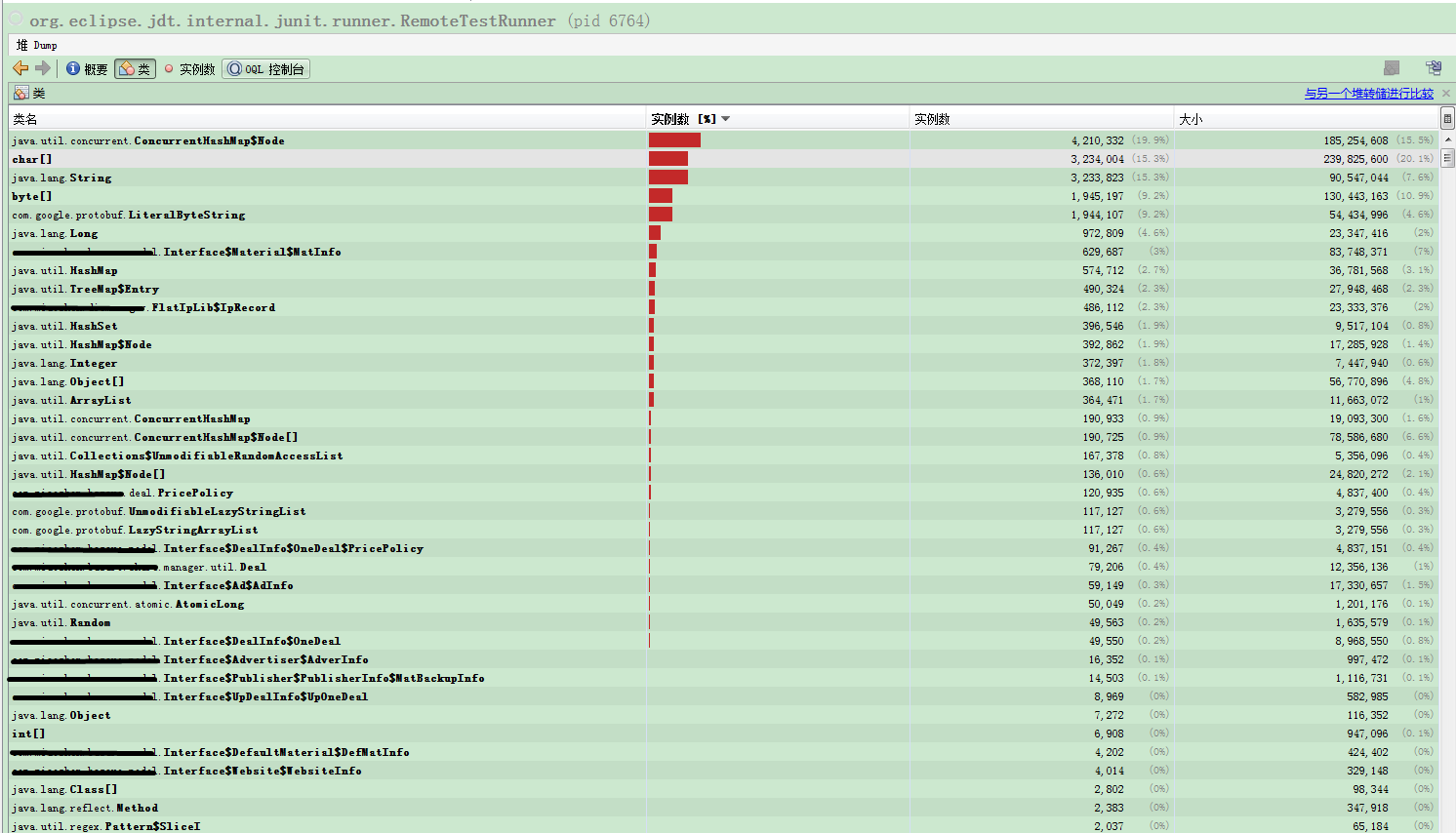
通过修改前后两张图对比,在char数组和String占用上,大约节省了近300M
- 后续补充
String.intern()的使用,也要考虑到jdk版本,具体参看文章
http://tech.meituan.com/in_depth_understanding_string_intern.html















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









