







Oracle默认认为SQL语句的where条件中出现的各列彼此是独立的,互不影响;所以oracle认为目标sql谓词条件以AND来组合的话,其选择率就是各个谓词条件的乘积,进而可以评估整个sql语句返回结果集的Cardinality。
例如:
select count(1) from people where sex='男' and birth_month=‘9月’;
选择率:性别只有男女,所以选择率是1/2;
月份只有12个月,所以选择率是1/12;
即 1/2*1/12=1/24。
如果表people有10000记录,那么基数Cardinality=100000*(1/2*1/12)=417,这样评估基数是没有问题的,因为 sex,birth_month是没有关系的。
再来看如下一个例子:
select count(1) from people where birth_month='9月' and constellation=‘处女座’;
如果还是按照如上的方法计算其选择率就有问题,因为月份跟星座是有关系的,并不能认为谓词各列是独立的,在这种情况下我们就需要动态采样机制来避免这种问题。
动态采样有如下作用:
1、不管目标sql语句中各列有什么关系,在大多数情况下,CBO都可以相对准确的评估出这个谓词条件各列的关系进而可以正确的评估出选择率,得到正确的返回基数。
2、由于有一些应用在执行的过程中会创建一些临时表,然后会往这些临时表里插入一些中间数据用于查询等操作,由于在执行完成之后这些临时表会被删除,问题是,这些临时表一旦参入了查询等操作的时候,他们是没有统计信息的,这种情况下,可能会导致最终的评估结果不准确甚至是错误的,动态采样可以避免这种情况。
动态采样开启方式:
1、optimizer_dynamic_sampling参数值大于或者等于1,则代表动态采样功能开启。
2、使用hint强制动态采样,dynamic_sampling(t,level) 表示对目标表T强制使用等级为level的动态采样。
optimizer_dynamic_sampling参数取值范围介绍:
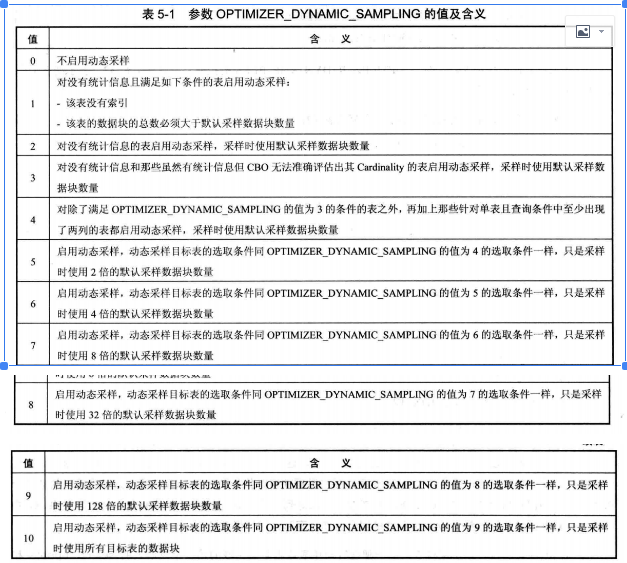
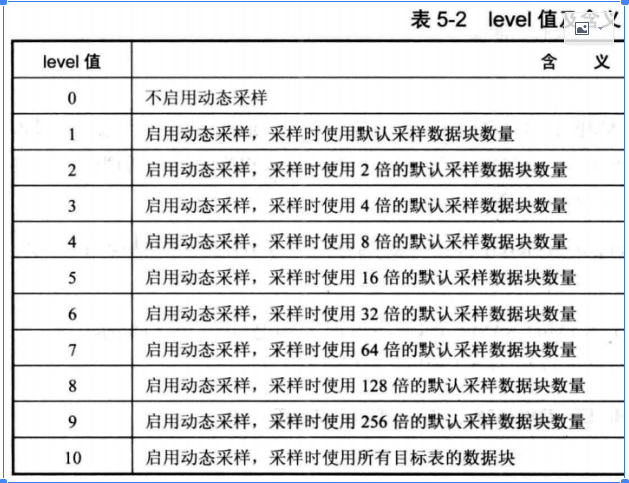
对于动态采样hint ,dynamic_sampling(t,level),其中level取值范围:
模拟环境:
SQL> create table t2 (c1 varchar2(1),c2 varchar2(2000),n1 number,n2 number);
SQL> insert into t2 select 'a','a',trunc(dbms_random.value(0,20)),trunc(dbms_random.value(0,25)) from dba_objects where rownum<10001;
SQL> create index idx_t2 on t2(n1,n2,c1);
SQL> exec dbms_stats.gather_table_stats('Sh','T2',cascade=>true);
PL/SQL procedure successfully completed.
SQL> @/home/oracle/scripts/sosi.txt;
Table Number Empty Average Chain Average Global User Sample Date
Name of Rows Blocks Blocks Space Count Row Len Stats Stats Size MM-DD-YYYY
--------------- -------------- -------- ------------ ------- -------- ------- ------ ------ -------------- ----------
T2 10,000 28 0 0 0 10 YES NO 10,000 05-04-2018
Column Column Distinct Number Number Global User Sample Date
Name Details Values Density Buckets Nulls Stats Stats Size MM-DD-YYYY
------------------------- ------------------------ ------------ ------- ------- ---------- ------ ------ -------------- ----------
C1 VARCHAR2(1) 1 1 1 0 YES NO 10,000 05-04-2018
C2 VARCHAR2(2000) 1 1 1 0 YES NO 10,000 05-04-2018
N1 NUMBER(22) 20 0 1 0 YES NO 10,000 05-04-2018
N2 NUMBER(22) 25 0 1 0 YES NO 10,000 05-04-2018
计算其基数:10000*1/1*1/1*1/20*1/25=20;
SQL> select count(1) from t2 where n1=1 and n2=3 and c1='a'
COUNT(1)
----------
14
查看执行计划:
SQL> select * from table(dbms_xplan.display_cursor(null,0));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 3dant16ufywy5, child number 0
-------------------------------------
select count(1) from t2 where n1=1 and n2=3 and c1='a'
Plan hash value: 4191549303
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 1 (100)| |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
|* 2 | INDEX RANGE SCAN| IDX_T2 | 20 | 160 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("N1"=1 AND "N2"=3 AND "C1"='a')
执行计划返回rows为20,我们计算的基数为120,实际返回的为14,可见跟我们预算出来值基本吻合。
SQL> update t2 set n2=n1;
SQL> exec dbms_stats.gather_table_stats('Sh','T2',cascade=>true);
SQL> @/home/oracle/scripts/sosi.txt;
Table Number Empty Average Chain Average Global User Sample Date
Name of Rows Blocks Blocks Space Count Row Len Stats Stats Size MM-DD-YYYY
--------------- -------------- -------- ------------ ------- -------- ------- ------ ------ -------------- ----------
T2 10,000 28 0 0 0 10 YES NO 10,000 05-04-2018
Column Column Distinct Number Number Global User Sample Date
Name Details Values Density Buckets Nulls Stats Stats Size MM-DD-YYYY
------------------------- ------------------------ ------------ ------- ------- ---------- ------ ------ -------------- ----------
C1 VARCHAR2(1) 1 0 1 0 YES NO 10,000 05-04-2018
C2 VARCHAR2(2000) 1 1 1 0 YES NO 10,000 05-04-2018
N1 NUMBER(22) 20 0 20 0 YES NO 10,000 05-04-2018
N2 NUMBER(22) 20 0 20 0 YES NO 10,000 05-04-2018
如果还是按照以往的计算方式,基数为 :10000*1/20*1/20=25
SQL> select count(1) from t2 where n1=3 and n2=3 and c1='a';
COUNT(1)
----------
498
实际返回结果集是498,
SQL> select * from table(dbms_xplan.display_cursor(null,0));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 1tpvtscuhy3b6, child number 0
-------------------------------------
select count(1) from t2 where n1=3 and n2=3 and c1='a'
Plan hash value: 4191549303
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 1 (100)| |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
|* 2 | INDEX RANGE SCAN| IDX_T2 | 25 | 200 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("N1"=3 AND "N2"=3 AND "C1"='a')
查看执行计划,返回的rows为25,
执行计划范围的rows 是25,我们计算的基数是也是25,但是实际返回的结果集了498,相差很大,因此不能按照以往的方式来计算基数。可见,CBO也是按照原来的计算方式来评估,导致执行计划偏差很大。
下面使用动态采样方式来帮助CBO选择正确的执行计划:
SQL> select /*+dynamic_sampling(t2,2)*/ count(1) from t2 where n1=3 and n2=3 and c1='a';
COUNT(1)
----------
498
SQL> select * from table(dbms_xplan.display_cursor(null,0));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID cq6v06fah22r8, child number 0
-------------------------------------
select /*+dynamic_sampling(t2,2)*/ count(1) from t2 where n1=3 and n2=3
and c1='a'
Plan hash value: 4191549303
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 3 (100)| |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
|* 2 | INDEX RANGE SCAN| IDX_T2 | 498 | 3984 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("N1"=3 AND "N2"=3 AND "C1"='a')
Note
-----
- dynamic sampling used for this statement (level=2)
由上可见,执行计划返货的rows为498跟实际返回结果集一致,因此得出结论:在目标sql谓词列有关联关系时,动态采样可以正确评估出基数,进而可以帮助CBO选择正确的执行计划。















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









