






linux网络实现分析(2)——数据包的接收(从链路层到ip层)
——lvyilong316
任何数据包在由驱动接收进入协议栈都会经过netif_receive_skb函数,可以说这个函数是协议栈的入口。在分析这个函数前,首先介绍下三层协议在内核中的组织方式。
在Linux内核中,有两种不同目的的3层协议:
(1) ptype_all管理的协议主要用于分析目的,它接收所有到达第3层协议的数据包。
(2) ptype_base管理正常的3层协议,仅接收具有正确协议标志符的数据包,例如,Internet的0x0800。
它们的组织关系如下图:
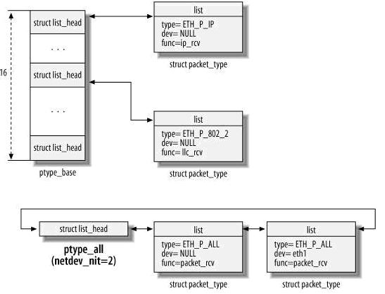
下面开始分析netif_receive_skb函数。
netif_receive_skb
int netif_receive_skb(struct sk_buff *skb)
{
struct packet_type *ptype, *pt_prev;
struct net_device *orig_dev;
struct net_device *null_or_orig;
int ret = NET_RX_DROP;
__be16 type;
if (skb->vlan_tci && vlan_hwaccel_do_receive(skb)) //有vlan tag,则vlan处理
return NET_RX_SUCCESS;
null_or_orig = NULL;
orig_dev = skb->dev; //接受数据包的原始设备
if (orig_dev->master) {
if (skb_bond_should_drop(skb))
null_or_orig = orig_dev; /* deliver only exact match */
else
skb->dev = orig_dev->master;
}
pt_prev = NULL;
rcu_read_lock();
//如AF_PACKET等ETH_P_ALL网络协议会被放在ptype_all链表中(tcpdump)。
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (ptype->dev == null_or_orig || ptype->dev == skb->dev ||
ptype->dev == orig_dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
skb = handle_bridge(skb, &pt_prev, &ret, orig_dev);//bridge逻辑处理
if (!skb)
goto out;
type = skb->protocol; //获取协议类型
//根据协议类型在hash表ptype_base中找到相关的注册协议(IP、ARP)
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_orig || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);//调用协议处理函数
pt_prev = ptype;
}
}
if (pt_prev) {
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);//???
} else {
kfree_skb(skb);
/* Jamal, now you will not able to escape explaining
* me how you were going to use this. :-)
*/
ret = NET_RX_DROP;
}
out:
rcu_read_unlock();
return ret;
}
deliver_skb
int deliver_skb(struct sk_buff *skb,struct packet_type *pt_prev, struct net_device *orig_dev){
atomic_inc(&skb->users); //这句不容忽视,与后面流程的kfree_skb()相呼应
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);//调函数ip_rcv() arp_rcv()等
}
如果是IP数据包,则调用ip_rcv()函数,这是因为ip协议再引导时间初始化协议处理函数为ip_rcv(),具体如下:
net/ipv4/af_inet.c,
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.gso_send_check = inet_gso_send_check,
.gso_segment = inet_gso_segment,
.gro_receive = inet_gro_receive,
.gro_complete = inet_gro_complete,
};
static int __init inet_init(void){
…
dev_add_pack(&ip_packet_type);
…
}
下面来看ip_rcv()函数:
ip_rcv()
net/ipv4/ip_input.c
/*
参数说明:
@dev:即skb->dev,但并不一定是最开始接收skb的dev,如经过bridge逻辑又发回本机协议栈时,此时dev即为刚经过的bridge对应的虚拟dev,具体见bridge逻辑。
@pt: 指向协议的指针,这里即ip_packet_type。
@orig_dev: 这是最开始接收数据包的设备dev,再netif_receive_skb中被设置。
*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
struct iphdr *iph;
u32 len;
//如果skb是share的(skb->users不为1),则clone一个skb_buff,skb指向这个新的skb->users为1的skb_buff
if ((skb = skb_share_check(skb, GFP_ATOMIC)) == NULL) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
goto out;
}
//进入ip_rcv之前,skb->date已经指向链路头后面,链路头已被解析。
if (!pskb_may_pull(skb, sizeof(struct iphdr)))
goto inhdr_error;
iph = ip_hdr(skb);
if (iph->ihl < 5 || iph->version != 4) //丢掉ip头长小于4*5=20的,或者ip version不为4的包(头部长度是以4字节为单位的)
goto inhdr_error;
if (!pskb_may_pull(skb, iph->ihl*4))
goto inhdr_error;
iph = ip_hdr(skb);
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))//丢弃校验和(仅头部)错误的包
goto inhdr_error;
len = ntohs(iph->tot_len); //len为数据包的真实长度
//由于链路层传输时,由于对齐或最小mtu等原因,可能会对数据包填充,所以这里要将数据包截断为其真实长度(len),len包括线性和非线性数据两部分。另外pskb_trim_rcsum会让L4校验和失效,以免接受的NIC计算过此值,但是计算的不正确。
if (pskb_trim_rcsum(skb, len)) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
goto drop;
}
skb_orphan(skb);//使包成为不属于任何套接字的孤包(skb->sk = NULL)
//IP PRE_ROUTING
return NF_HOOK(PF_INET, NF_INET_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
inhdr_error:
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INHDRERRORS);
drop:
kfree_skb(skb);
out:
return NET_RX_DROP;
}
在经过IP协议的PRE_ROUTING hook点后,将调用ip_rcv_finish函数。
ip_rcv_finish
net/ipv4/ip_input.c,
static int ip_rcv_finish(struct sk_buff *skb)
{
const struct iphdr *iph = ip_hdr(skb);
struct rtable *rt;
// skb->_skb_dst 指向dst_entry
if (skb_dst(skb) == NULL) {//如果 skb->_skb_dst为空
int err = ip_route_input(skb, iph->daddr, iph->saddr, iph->tos,
skb->dev); //查找路由表
…
}
}
//当ip头部超过20字节时,表示有一些选项要处理,此时skb_cow(命名来自于copy on write)会被调用,如果skb和别人有share,就拷贝一个副本,因为处理选项有可能修改ip头。同时处理选项
if (iph->ihl > 5 && ip_rcv_options(skb))
goto drop;
rt = skb_rtable(skb);
if (rt->rt_type == RTN_MULTICAST) { //多播
IP_UPD_PO_STATS_BH(dev_net(rt->u.dst.dev), IPSTATS_MIB_INMCAST,
skb->len);
} else if (rt->rt_type == RTN_BROADCAST) //广播
IP_UPD_PO_STATS_BH(dev_net(rt->u.dst.dev), IPSTATS_MIB_INBCAST,
skb->len);
return dst_input(skb);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}
dst_input
static inline int dst_input(struct sk_buff *skb)
{
return skb_dst(skb)->input(skb);
}
即调用skb->_skb_dst->input(skb),skb->_skb_dst在ip_route_input中被初始化为ip_local_deliver或ip_forward,这取决于封包的目的地址。














 9475
9475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









