






一、Linux 网络收包总览
在 TCP / IP 网络分层模型里,整个协议栈被分成了物理层、链路层、网络层,传输层和应用层。物理层对应的是网卡和网线,应用层对应的是我们常见的 Nginx,FTP 等等各种应用。Linux 实现的是链路层、网络层和传输层这三层。
在 Linux 内核实现中,链路层协议靠网卡驱动来实现,内核协议栈来实现网络层和传输层。内核对更上层的应用层提供 socket 接口来供用户进程访问。
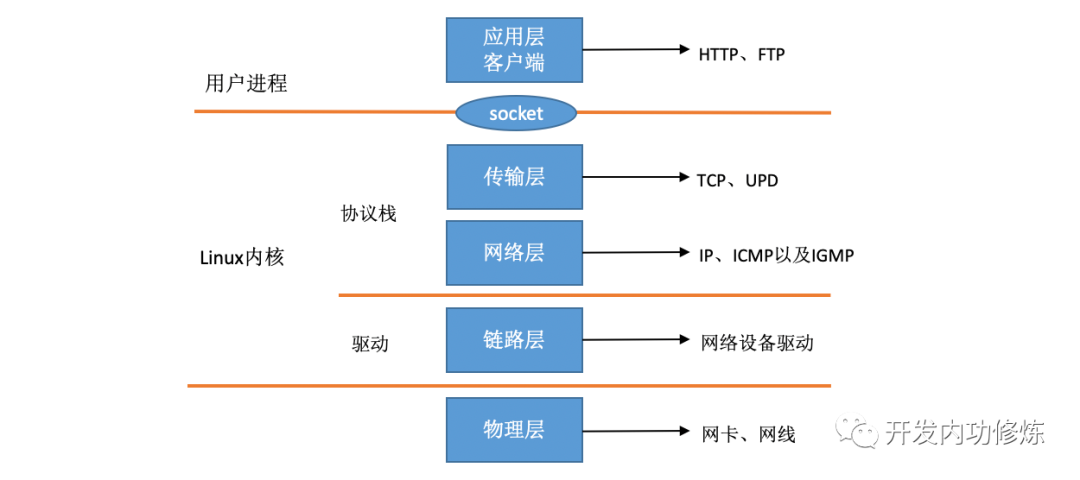
在 Linux 的源代码中,网络设备驱动对应的逻辑位于driver/net/ethernet。协议栈模块代码位于 kernel 和 net 目录。
内核网络收包过程
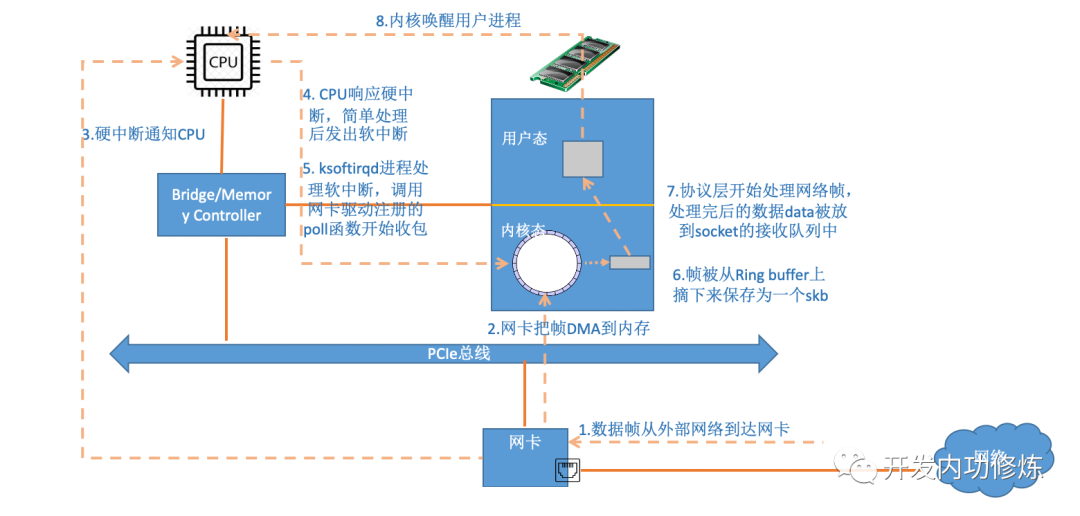
1、网卡收到数据包后,linux中第一个工作的模块就是网络驱动,网络驱动以DMA方式把网卡上收到的帧写到内存中。再向CPU发出硬中断以通知CPU有数据到了。
2、中断上半部来说(基本等同硬中断),当 CPU 收到中断请求后,会去调用网络驱动注册的中断处理函数,最后发送一个软中断信号通知下半部做进一步处理。
3、下半部(基本等于软中断)被软中断信号唤醒后,ksoftirqd 检测到有软中断请求到达,调用 poll 开始轮询收包,收到后交由各级协议栈处理,直到把数据送到应用程序。
二、Linux 启动
Linux 驱动,内核协议栈等等模块在具备接收网卡数据包之前,要做很多的准备工作才行。比如要注册硬中断、提前创建好 ksoftirqd 内核线程、要注册好各个协议对应的处理函数,网络设备子系统要提前初始化好,网卡要启动好。只有这些都 Ready 之后,我们才能真正开始接收数据包。
2.1 注册硬中断
一般是在probe中使用devm_request_irq注册硬中断及handler。
err = devm_request_irq(eth->dev, eth->irq[1],
mtk_handle_irq_tx, 0,
dev_name(eth->dev), eth);
err = devm_request_irq(eth->dev, eth->irq[2],
mtk_handle_irq_rx, 0,
dev_name(eth->dev), ð->rx_napi[0]);
2.2 创建 ksoftirqd 内核线程
Linux 的软中断都是在专门的内核线程(ksoftirqd)中进行的。该进程数量和核数相同。
root@/tmp/root/root# ps | grep ksoftirqd
9 root 0 SW [ksoftirqd/0]
16 root 0 SW [ksoftirqd/1]
系统初始化的时候在 kernel/smpboot.c 中调用了 smpboot_register_percpu_thread,该函数进一步会执行到 spawn_ksoftirqd(位于 kernel/softirq.c)来创建出 softirqd 进程。

static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
static __init int spawn_ksoftirqd(void)
{
cpuhp_setup_state_nocalls(CPUHP_SOFTIRQ_DEAD, "softirq:dead", NULL,
takeover_tasklets);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
return 0;
}
early_initcall(spawn_ksoftirqd);
当 ksoftirqd 被创建出来以后,它就会进入自己的线程循环函数 ksoftirqd_should_run 和 run_ksoftirqd 了。不停地判断有没有软中断需要被处理。软中断类型:
//file: include/linux/interrupt.h
enum{
HI_SOFTIRQ=0, //start_kernel->softirq_init
TIMER_SOFTIRQ, //start_kernel->init_timers
NET_TX_SOFTIRQ, //net_dev_init
NET_RX_SOFTIRQ, //net_dev_init
BLOCK_SOFTIRQ, //
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ, //start_kernel->softirq_init
SCHED_SOFTIRQ, //start_kernel->sched_init->init_sched_fair_class
HRTIMER_SOFTIRQ, //start_kernel->hrtimers_init
RCU_SOFTIRQ, //start_kernel->rcu_init
};
2.3 网络子系统初始化
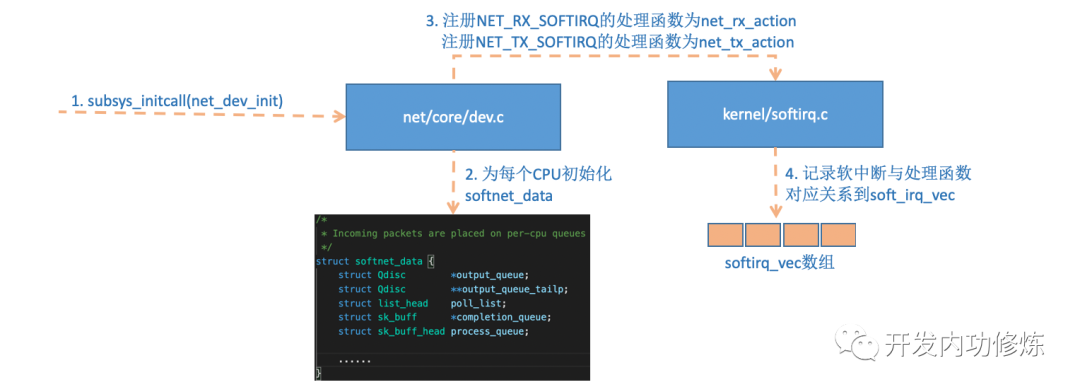
linux 内核通过调用 subsys_initcall 来初始化各个子系统,会执行到 net_dev_init 函数。
//file: net/core/dev.c
static int __init net_dev_init(void){
for_each_possible_cpu(i) {
struct work_struct *flush = per_cpu_ptr(&flush_works, i);
struct softnet_data *sd = &per_cpu(softnet_data, i);
INIT_WORK(flush, flush_backlog);
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
#ifdef CONFIG_XFRM_OFFLOAD
skb_queue_head_init(&sd->xfrm_backlog);
#endif
INIT_LIST_HEAD(&sd->poll_list);
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->cpu = i;
#endif
init_gro_hash(&sd->backlog);
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
}
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
}
subsys_initcall(net_dev_init);
在这个函数里,会为每个 CPU 都申请一个 softnet_data 数据结构,在这个数据结构里的 poll_list 是等待驱动程序将其 poll 函数注册进来,稍后网卡驱动初始化的时候我们可以看到这一过程。
另外 open_softirq 注册了每一种软中断都注册一个处理函数。NET_TX_SOFTIRQ 的处理函数为 net_tx_action,NET_RX_SOFTIRQ 的为 net_rx_action。继续跟踪 open_softirq 后发现这个注册的方式是记录在 softirq_vec 变量里的。后面 ksoftirqd 线程收到软中断的时候,也会使用这个变量来找到每一种软中断对应的处理函数。
//file: kernel/softirq.c
void open_softirq(int nr, void (*action)(struct softirq_action *)){
softirq_vec[nr].action = action;
}
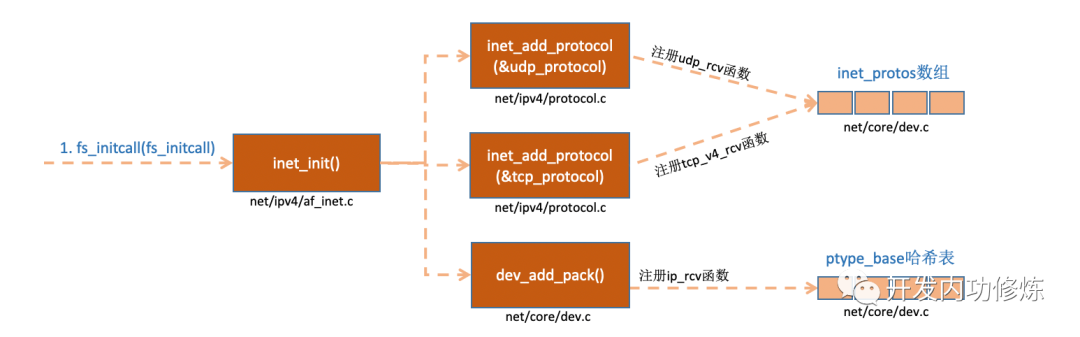
2.3 协议栈注册
内核实现了网络层的 ip 协议,也实现了传输层的 tcp 协议和 udp 协议。这些协议对应的实现函数分别是 ip_rcv (),tcp_v4_rcv () 和 udp_rcv ()。和我们平时写代码的方式不一样的是,内核是通过注册的方式来实现的。Linux 内核中的 fs_initcall 和 subsys_initcall 类似,也是初始化模块的入口。fs_initcall 调用 inet_init 后开始网络协议栈注册。通过 inet_init,将这些函数注册到了 inet_protos 和 ptype_base 数据结构中。如下图:
相关代码如下
//file: net/ipv4/af_inet.c
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
};
/* thinking of making this const? Don't.
* early_demux can change based on sysctl.
*/
static struct net_protocol udp_protocol = {
.early_demux = udp_v4_early_demux,
.early_demux_handler = udp_v4_early_demux,
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};
static const struct net_protocol icmp_protocol = {
.handler = icmp_rcv,
.err_handler = icmp_err,
.no_policy = 1,
.netns_ok = 1,
};
static int __init inet_init(void){
......
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
#ifdef CONFIG_IP_MULTICAST
if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0)
pr_crit("%s: Cannot add IGMP protocol\n", __func__);
#endif
......
dev_add_pack(&ip_packet_type);
}
上面的代码中我们可以看到,udp_protocol 结构体中的 handler 是 udp_rcv,tcp_protocol 结构体中的 handler 是 tcp_v4_rcv,通过 inet_add_protocol 被初始化了进来。
int int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol)
{
if (!prot->netns_ok) {
pr_err("Protocol %u is not namespace aware, cannot register.\n",
protocol);
return -EINVAL;
}
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],
NULL, prot) ? 0 : -1;
}
inet_add_protocol 函数将 tcp 和 udp 对应的处理函数都注册到了 inet_protos 数组中了。再看 dev_add_pack (&ip_packet_type); 这一行,ip_packet_type 结构体中的 type 是协议名,func 是 ip_rcv 函数,在 dev_add_pack 中会被注册到 ptype_base 哈希表中。
//file: net/core/dev.c
void dev_add_pack(struct packet_type *pt)
{
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
static inline struct list_head *ptype_head(const struct packet_type *pt)
{
if (pt->type == htons(ETH_P_ALL))
return pt->dev ? &pt->dev->ptype_all : &ptype_all;
else
return pt->dev ? &pt->dev->ptype_specific :
&ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
这里我们需要记住 inet_protos 记录着 udp,tcp 的处理函数地址,ptype_base 存储着 ip_rcv () 函数的处理地址。后面我们会看到软中断中会通过 ptype_base 找到 ip_rcv 函数地址,进而将 ip 包正确地送到 ip_rcv () 中执行。在 ip_rcv 中将会通过 inet_protos 找到 tcp 或者 udp 的处理函数,再而把包转发给 udp_rcv () 或 tcp_v4_rcv () 函数。
2.5 网卡驱动初始化
每一个驱动程序(不仅仅只是网卡驱动)会向内核注册driver结构体,如platform_driver。
static struct platform_driver mtk_driver = {
.probe = mtk_probe,
.remove = mtk_remove,
.driver = {
.name = "mtk_soc_eth",
.of_match_table = of_mtk_match,
},
};
module_platform_driver(mtk_driver);
实际上使用 module_init 向内核注册一个初始化函数,当驱动被加载时,内核会调用这个函数。
static int __init xxx_init(void)
{
return platform_driver_register(&xxx_driver);
}
module_init(xxx_init);
platform_driver_register调用完成后,Linux 内核就知道了该驱动的相关信息,比如driver_name 和 probe 函数地址等等。当网卡设备被识别以后,内核会调用其驱动的 probe 方法,probe 方法执行的目的就是让设备 ready。主要执行的操作如下:
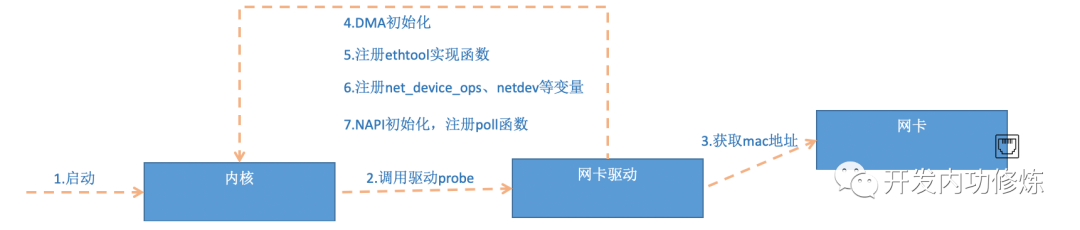
第 5 步中我们看到,网卡驱动实现了 ethtool 所需要的接口,也在这里注册完成函数地址的注册。当 ethtool 发起一个系统调用之后,内核会找到对应操作的回调函数。这个命令之所以能查看网卡收发包统计、能修改网卡自适应模式、能调整 RX 队列的数量和大小,是因为 ethtool 命令最终调用到了网卡驱动的相应方法。
static const struct ethtool_ops mtk_ethtool_ops = {
.get_link_ksettings = mtk_get_link_ksettings,
.set_link_ksettings = mtk_set_link_ksettings,
.get_drvinfo = mtk_get_drvinfo,
.get_msglevel = mtk_get_msglevel,
.set_msglevel = mtk_set_msglevel,
.nway_reset = mtk_nway_reset,
#if IS_ENABLED(CONFIG_BONDING)
.get_link = mtk_get_link,
#else
.get_link = ethtool_op_get_link,
#endif
.get_strings = mtk_get_strings,
.get_sset_count = mtk_get_sset_count,
.get_ethtool_stats = mtk_get_ethtool_stats,
.get_rxnfc = mtk_get_rxnfc,
.set_rxnfc = mtk_set_rxnfc,
};
第 6 步注册的netdev_ops 中包含的是 xxx_open 等函数,该函数在网卡被启动的时候会被调用。
static const struct net_device_ops mtk_netdev_ops = {
.ndo_init = mtk_init,
.ndo_uninit = mtk_uninit,
.ndo_open = mtk_open,
.ndo_stop = mtk_stop,
.ndo_start_xmit = mtk_start_xmit,
.ndo_set_mac_address = mtk_set_mac_address,
.ndo_validate_addr = eth_validate_addr,
.ndo_do_ioctl = mtk_do_ioctl,
.ndo_tx_timeout = mtk_tx_timeout,
.ndo_get_stats64 = mtk_get_stats64,
.ndo_fix_features = mtk_fix_features,
.ndo_set_features = mtk_set_features,
#ifdef CONFIG_NET_POLL_CONTROLLER
.ndo_poll_controller = mtk_poll_controller,
#endif
};
第 7 步中,xxx_probe 初始化过程中,还调用到了 netif_napi_add注册 NAPI 机制所必须的 poll 函数,比如mtk_napi_tx、mtk_napi_rx。
netif_napi_add(ð->dummy_dev, ð->tx_napi, mtk_napi_tx,
MTK_NAPI_WEIGHT);
netif_napi_add(ð->dummy_dev, ð->rx_napi[0].napi, mtk_napi_rx,
MTK_NAPI_WEIGHT);
2.6 启动网卡
当上面的初始化都完成以后,就可以启动网卡了。回忆前面网卡驱动初始化时,我们提到了驱动向内核注册了 structure net_device_ops 变量,它包含着网卡启用、发包、设置 mac 地址等回调函数(函数指针)。当启用一个网卡时(例如,通过 ifconfig eth0 up),net_device_ops 中的 xxx_open 方法会被调用。它通常会做以下事情:

图 7 启动网卡
// 注册中断也可能在probe中进行。
static int mtk_open(struct net_device *dev)
{
struct mtk_mac *mac = netdev_priv(dev);
struct mtk_eth *eth = mac->hw;
int err, i;
/* we run 2 netdevs on the same dma ring so we only bring it up once */
if (!refcount_read(ð->dma_refcnt)) {
int err = mtk_start_dma(eth);
if (err)
return err;
mtk_gdm_config(eth, MTK_GDMA_TO_PDMA);
/* Indicates CDM to parse the MTK special tag from CPU */
if (netdev_uses_dsa(dev)) {
u32 val;
val = mtk_r32(eth, MTK_CDMQ_IG_CTRL);
mtk_w32(eth, val | MTK_CDMQ_STAG_EN, MTK_CDMQ_IG_CTRL);
val = mtk_r32(eth, MTK_CDMP_IG_CTRL);
mtk_w32(eth, val | MTK_CDMP_STAG_EN, MTK_CDMP_IG_CTRL);
}
// 开启NAPI
napi_enable(ð->tx_napi);
napi_enable(ð->rx_napi[0].napi);
mtk_tx_irq_enable(eth, MTK_TX_DONE_INT);
mtk_rx_irq_enable(eth, MTK_RX_DONE_INT(0));
refcount_set(ð->dma_refcnt, 1);
}
else
refcount_inc(ð->dma_refcnt);
phylink_start(mac->phylink);
netif_start_queue(dev);
return 0;
}
当做好以上准备工作以后,就可以开门迎客(数据包)了!
三、迎接数据的到来
3.1 硬中断处理
首先当数据帧从网线到达网卡上的时候,第一站是网卡的接收队列。网卡在分配给自己的 RingBuffer 中寻找可用的内存位置,找到后 DMA 引擎会把数据 DMA 到网卡之前关联的内存里,这个时候 CPU 都是无感的。当 DMA 操作完成以后,网卡向 CPU 发起一个硬中断,通知 CPU 有数据到达。
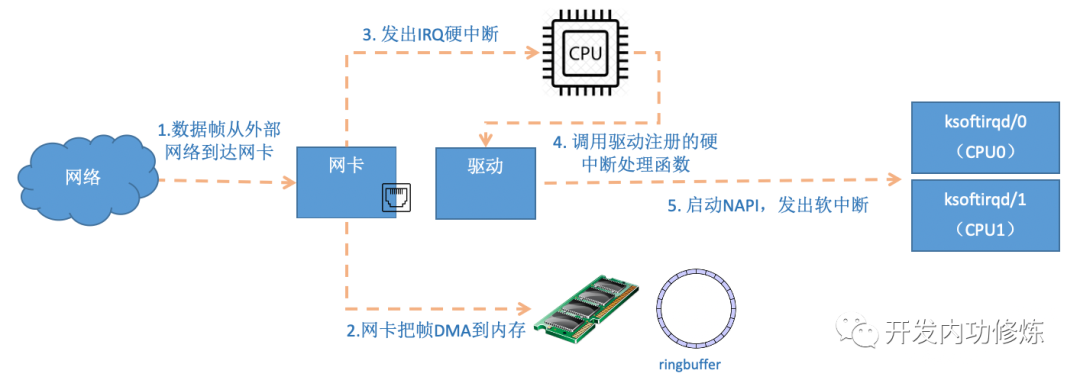
注意:当 RingBuffer 满的时候,新来的数据包将给丢弃。ifconfig 查看网卡的时候,可以里面有个 overruns,表示因为环形队列满被丢弃的包。如果发现有丢包,可能需要通过 ethtool 命令来加大环形队列的长度。
在启动网卡一节,我们说到了网卡的硬中断注册的处理函数是 igb_msix_ring。
static irqreturn_t mtk_handle_irq_rx(int irq, void *priv)
{
struct mtk_napi *rx_napi = priv;
struct mtk_eth *eth = rx_napi->eth;
struct mtk_rx_ring *ring = rx_napi->rx_ring;
if (likely(napi_schedule_prep(&rx_napi->napi))) {
// 关闭中断,开始poll
mtk_rx_irq_disable(eth, MTK_RX_DONE_INT(ring->ring_no));
__napi_schedule(&rx_napi->napi);
}
return IRQ_HANDLED;
}
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
struct task_struct *thread;
if (test_bit(NAPI_STATE_THREADED, &napi->state)) {
/* Paired with smp_mb__before_atomic() in
* napi_enable()/dev_set_threaded().
* Use READ_ONCE() to guarantee a complete
* read on napi->thread. Only call
* wake_up_process() when it's not NULL.
*/
thread = READ_ONCE(napi->thread);
if (thread) {
if (thread->state != TASK_INTERRUPTIBLE)
set_bit(NAPI_STATE_SCHED_THREADED, &napi->state);
wake_up_process(thread);
return;
}
}
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
这里我们看到,list_add_tail 将驱动传过来的 poll_list 添加到CPU 变量 softnet_data 里的 poll_list。其中 softnet_data 中的 poll_list 是一个双向链表,其中的设备都带有输入帧等着被处理。紧接着__raise_softirq_irqoff 触发了一个软中断 NET_RX_SOFTIRQ,这个所谓的触发过程只是对一个变量进行了一次或运算而已。
void __raise_softirq_irqoff(unsigned int nr)
{
trace_softirq_raise(nr);
or_softirq_pending(1UL << nr);
}
#define or_softirq_pending(x) (__this_cpu_or(local_softirq_pending_ref, (x)))
我们说过,Linux 在硬中断里只完成简单必要的工作,剩下的大部分的处理都是转交给软中断的。通过上面代码可以看到,硬中断处理过程真的是非常短。只是记录了一个寄存器,修改了一下下 CPU 的 poll_list,然后发出个软中断。就这么简单,硬中断工作就算是完成了。
3.2 ksoftirqd 内核线程处理软中断
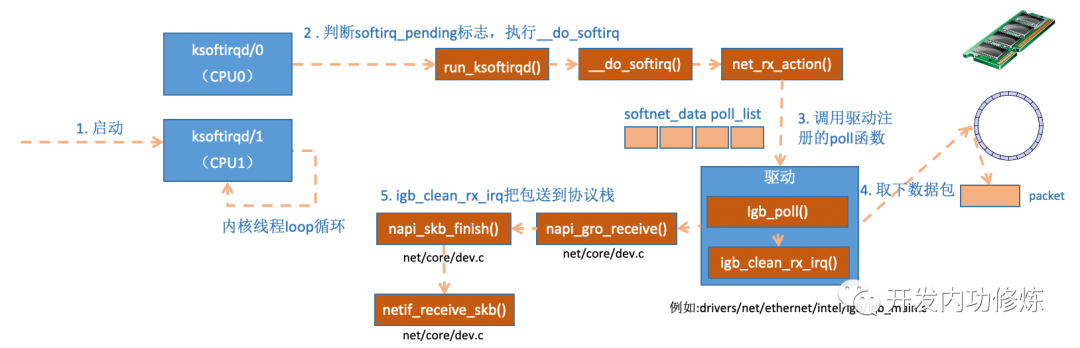
内核线程初始化的时候,我们介绍了 ksoftirqd 中两个线程函数 ksoftirqd_should_run 和 run_ksoftirqd。其中 ksoftirqd_should_run 代码如下:
static int ksoftirqd_should_run(unsigned int cpu)
{
return local_softirq_pending();
}
#define local_softirq_pending() (__this_cpu_read(local_softirq_pending_ref))
这里看到和硬中断中调用了同一个函数 local_softirq_pending。使用方式不同的是硬中断位置是为了写入标记,这里仅仅只是读取。如果硬中断中设置了 NET_RX_SOFTIRQ, 这里自然能读取的到。接下来会真正进入线程函数中 run_ksoftirqd 处理:
static void run_ksoftirqd(unsigned int cpu)
{
local_irq_disable();
if (local_softirq_pending()) {
/*
* We can safely run softirq on inline stack, as we are not deep
* in the task stack here.
*/
__do_softirq();
local_irq_enable();
cond_resched();
return;
}
local_irq_enable();
}
在__do_softirq 中,判断根据当前 CPU 的软中断类型,调用其注册的 action 方法。
asmlinkage void __do_softirq(void){
h = softirq_vec;
while ((softirq_bit = ffs(pending))) {
unsigned int vec_nr;
int prev_count;
h += softirq_bit - 1;
vec_nr = h - softirq_vec;
prev_count = preempt_count();
kstat_incr_softirqs_this_cpu(vec_nr);
trace_softirq_entry(vec_nr);
h->action(h);
trace_softirq_exit(vec_nr);
if (unlikely(prev_count != preempt_count())) {
pr_err("huh, entered softirq %u %s %p with preempt_count %08x, exited with %08x?\n",
vec_nr, softirq_to_name[vec_nr], h->action,
prev_count, preempt_count());
preempt_count_set(prev_count);
}
h++;
pending >>= softirq_bit;
}
}
之前为 NET_RX_SOFTIRQ 注册了处理函数 net_rx_action。所以 net_rx_action 函数就会被执行到了。这里需要注意一个细节,硬中断中设置软中断标记,和 ksoftirq 的判断是否有软中断到达,都是基于 smp_processor_id () 的。这意味着只要硬中断在哪个 CPU 上被响应,那么软中断也是在这个 CPU 上处理的。所以说,如果你发现你的 Linux 软中断 CPU 消耗都集中在一个核上的话,做法是要把调整硬中断的 CPU 亲和性,来将硬中断打散到不同的 CPU 核上去。
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies +
usecs_to_jiffies(netdev_budget_usecs);
int budget = netdev_budget;
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto out;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 ||
time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
net_rps_action_and_irq_enable(sd);
out:
__kfree_skb_flush();
}
函数开头的 time_limit 和 budget 是用来控制 net_rx_action 函数主动退出的,目的是保证网络包的接收不霸占 CPU 不放。等下次网卡再有硬中断过来的时候再处理剩下的接收数据包。其中 budget 可以通过内核参数调整。这个函数中剩下的核心逻辑是获取到当前 CPU 变量 softnet_data,对其 poll_list 进行遍历,然后执行到网卡驱动注册到的 poll 函数如mtk_napi_rx。
static int mtk_napi_rx(struct napi_struct *napi, int budget)
{
struct mtk_napi *rx_napi = container_of(napi, struct mtk_napi, napi);
struct mtk_eth *eth = rx_napi->eth;
struct mtk_rx_ring *ring = rx_napi->rx_ring;
u32 status, mask;
int rx_done = 0;
int remain_budget = budget;
mtk_handle_status_irq(eth);
poll_again:
mtk_w32(eth, MTK_RX_DONE_INT(ring->ring_no), MTK_PDMA_INT_STATUS);
rx_done = mtk_poll_rx(napi, remain_budget, eth);
if (unlikely(netif_msg_intr(eth))) {
status = mtk_r32(eth, MTK_PDMA_INT_STATUS);
mask = mtk_r32(eth, MTK_PDMA_INT_MASK);
dev_info(eth->dev,
"done rx %d, intr 0x%08x/0x%x\n",
rx_done, status, mask);
}
if (rx_done == remain_budget)
return budget;
status = mtk_r32(eth, MTK_PDMA_INT_STATUS);
if (status & MTK_RX_DONE_INT(ring->ring_no)) {
remain_budget -= rx_done;
goto poll_again;
}
if (napi_complete(napi))
mtk_rx_irq_enable(eth, MTK_RX_DONE_INT(ring->ring_no));
return rx_done + budget - remain_budget;
}
static int mtk_poll_rx(struct napi_struct *napi, int budget,
struct mtk_eth *eth)
{
struct mtk_napi *rx_napi = container_of(napi, struct mtk_napi, napi);
struct mtk_rx_ring *ring = rx_napi->rx_ring;
int idx;
struct sk_buff *skb;
u8 *data, *new_data;
struct mtk_rx_dma *rxd, trxd;
int done = 0;
if (unlikely(!ring))
goto rx_done;
while (done < budget) {
idx = NEXT_DESP_IDX(ring->calc_idx, ring->dma_size);
rxd = &ring->dma[idx];
data = ring->data[idx];
............
/* receive data */
skb = build_skb(data, 0);
skb_reserve(skb, NET_SKB_PAD + NET_IP_ALIGN);
pktlen = RX_DMA_GET_PLEN0(trxd.rxd2);
skb->dev = netdev;
skb_put(skb, pktlen);
if ((!MTK_HAS_CAPS(eth->soc->caps, MTK_NETSYS_V2) &&
(trxd.rxd4 & eth->rx_dma_l4_valid)) ||
(MTK_HAS_CAPS(eth->soc->caps, MTK_NETSYS_V2) &&
(trxd.rxd3 & eth->rx_dma_l4_valid)))
skb->ip_summed = CHECKSUM_UNNECESSARY;
else
skb_checksum_none_assert(skb);
skb->protocol = eth_type_trans(skb, netdev);
if (netdev->features & NETIF_F_HW_VLAN_CTAG_RX) {
if (MTK_HAS_CAPS(eth->soc->caps, MTK_NETSYS_V2)) {
if (trxd.rxd3 & RX_DMA_VTAG_V2)
__vlan_hwaccel_put_tag(skb,
htons(RX_DMA_VPID_V2(trxd.rxd4)),
RX_DMA_VID_V2(trxd.rxd4));
} else {
if (trxd.rxd2 & RX_DMA_VTAG)
__vlan_hwaccel_put_tag(skb,
htons(RX_DMA_VPID(trxd.rxd3)),
RX_DMA_VID(trxd.rxd3));
}
/* If netdev is attached to dsa switch, the special
* tag inserted in VLAN field by switch hardware can
* be offload by RX HW VLAN offload. Clears the VLAN
* information from @skb to avoid unexpected 8021d
* handler before packet enter dsa framework.
*/
if (netdev_uses_dsa(netdev))
__vlan_hwaccel_clear_tag(skb);
}
#if defined(CONFIG_NET_MEDIATEK_HNAT) || defined(CONFIG_NET_MEDIATEK_HNAT_MODULE)
#if defined(CONFIG_MEDIATEK_NETSYS_V2)
if (MTK_HAS_CAPS(eth->soc->caps, MTK_NETSYS_V2))
*(u32 *)(skb->head) = trxd.rxd5;
else
#endif
*(u32 *)(skb->head) = trxd.rxd4;
skb_hnat_alg(skb) = 0;
skb_hnat_filled(skb) = 0;
skb_hnat_magic_tag(skb) = HNAT_MAGIC_TAG;
if (skb_hnat_reason(skb) == HIT_BIND_FORCE_TO_CPU) {
trace_printk("[%s] reason=0x%x(force to CPU) from WAN to Ext\n",
__func__, skb_hnat_reason(skb));
skb->pkt_type = PACKET_HOST;
}
#endif
skb_record_rx_queue(skb, 0);
napi_gro_receive(napi, skb);
skip_rx:
ring->data[idx] = new_data;
rxd->rxd1 = (unsigned int)dma_addr;
release_desc:
if (MTK_HAS_CAPS(eth->soc->caps, MTK_SOC_MT7628))
rxd->rxd2 = RX_DMA_LSO;
else
rxd->rxd2 = RX_DMA_PLEN0(ring->buf_size);
ring->calc_idx = idx;
done++;
}
return done;
}
获取下来的一个数据帧用一个 skb 来表示。收取完数据以后,对其进行一些校验,然后开始设置 sbk 变量的 timestamp, VLAN id, protocol 等字段。接下来进入到 napi_gro_receive 中:
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
gro_result_t ret;
skb_mark_napi_id(skb, napi);
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb, 0);
ret = napi_skb_finish(napi, skb, dev_gro_receive(napi, skb));
trace_napi_gro_receive_exit(ret);
return ret;
}
dev_gro_receive 这个函数代表的是网卡 GRO 特性,可以简单理解成把相关的小包合并成一个大包就行,目的是减少传送给网络栈的包数,这有助于减少 CPU 的使用量。我们暂且忽略,直接看 napi_skb_finish, 这个函数主要就是调用了 netif_receive_skb。
static gro_result_t napi_skb_finish(struct napi_struct *napi,
struct sk_buff *skb,
gro_result_t ret)
{
switch (ret) {
case GRO_NORMAL:
gro_normal_one(napi, skb, 1);//最终调用deliver_skb
break;
case GRO_DROP:
kfree_skb(skb);
break;
case GRO_MERGED_FREE:
if (NAPI_GRO_CB(skb)->free == NAPI_GRO_FREE_STOLEN_HEAD)
napi_skb_free_stolen_head(skb);
else
__kfree_skb(skb);
break;
case GRO_HELD:
case GRO_MERGED:
case GRO_CONSUMED:
break;
}
return ret;
}
在 netif_receive_skb 中,数据包将被送到协议栈中。
3.3 网络协议栈处理
netif_receive_skb 函数会根据包的协议,假如是 udp 包,会将包依次送到 ip_rcv (),udp_rcv () 协议处理函数中进行处理。
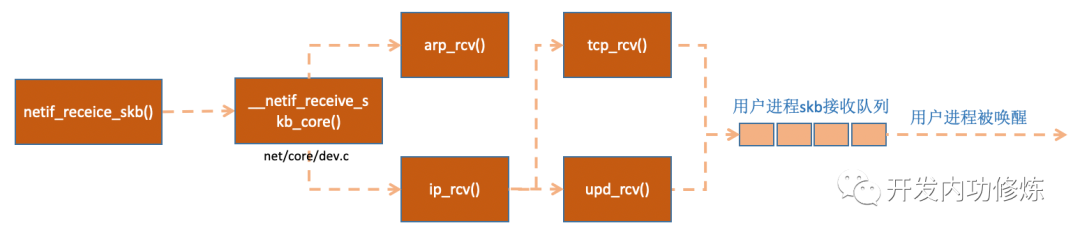
图 10 网络协议栈处理
napi_skb_finish
gro_normal_one
gro_normal_list
netif_receive_skb_list_internal
enqueue_to_backlog
__netif_receive_skb_list
__netif_receive_skb_list_core
deliver_skb
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev)
{
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
return -ENOMEM;
refcount_inc(&skb->users);
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
pt_prev->func 这一行就调用到了协议层注册的处理函数了。对于 ip 包来讲,就会进入到 ip_rcv(如果是 arp 包的话,会进入到 arp_rcv)。
3.4 IP 协议层处理
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
if (skb == NULL)
return NET_RX_DROP;
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
}
这里 NF_HOOK 是一个钩子函数,当执行完注册的钩子后就会执行到最后一个参数指向的函数 ip_rcv_finish。
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
int ret;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_rcv(skb);
if (!skb)
return NET_RX_SUCCESS;
ret = ip_rcv_finish_core(net, sk, skb, dev);
if (ret != NET_RX_DROP)
ret = dst_input(skb);
return ret;
}
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
__skb_pull(skb, skb_network_header_len(skb));
rcu_read_lock();
ip_protocol_deliver_rcu(net, skb, ip_hdr(skb)->protocol);
rcu_read_unlock();
return 0;
}
void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol)
{
const struct net_protocol *ipprot;
int raw, ret;
resubmit:
raw = raw_local_deliver(skb, protocol);
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
if (!ipprot->no_policy) {
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
kfree_skb(skb);
return;
}
nf_reset_ct(skb);
}
ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv,
skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
}
...
}
inet_protos 中保存着 tcp_rcv () 和 udp_rcv () 的函数地址。这里将会根据包中的协议类型选择进行分发,在这里 skb 包将会进一步被派送到更上层的协议中,udp 和 tcp。
四、recvfrom 系统调用
Linux 内核对数据包的接收和处理后最后把数据包放到 socket 的接收队列中了。那么我们再回头看用户进程调用 recvfrom 后是发生了什么。我们在代码里调用的 recvfrom 是一个 glibc 的库函数,该函数在执行后会将用户进行陷入到内核态,进入到 Linux 实现的系统调用 sys_recvfrom。在理解 Linux 对 sys_revvfrom 之前,我们先来简单看一下 socket 这个核心数据结构。这个数据结构太大了,我们只把对和我们今天主题相关的内容画出来,如下:
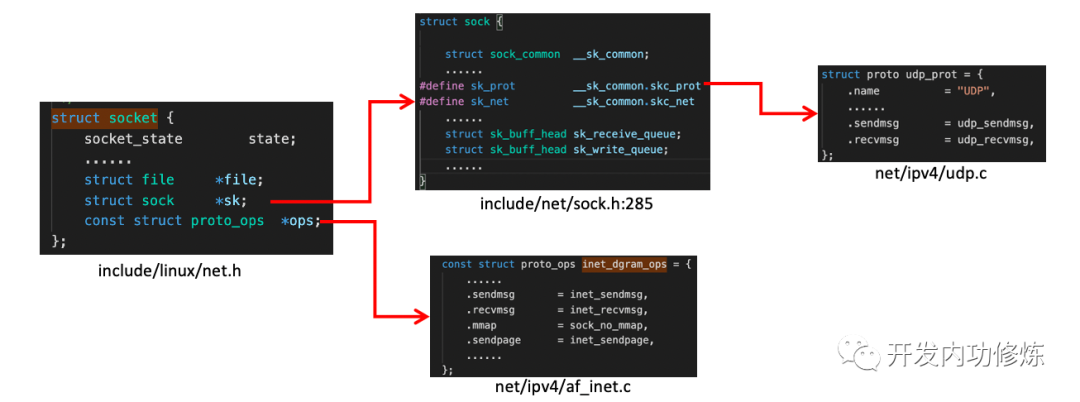
socket 数据结构中的 const struct proto_ops 对应的是协议的方法集合。每个协议都会实现不同的方法集,对于 IPv4 Internet 协议族来说,每种协议都有对应的处理方法,如下。对于 udp 来说,是通过 inet_dgram_ops 来定义的,其中注册了 inet_recvmsg 方法。
const struct proto_ops inet_stream_ops = {
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
#ifdef CONFIG_MMU
.mmap = tcp_mmap,
#endif
}
const struct proto_ops inet_dgram_ops = {
......
.recvmsg = inet_recvmsg,
.mmap = sock_no_mmap,
};
socket 数据结构中的另一个数据结构 struct sock *sk 是一个非常大,非常重要的子结构体。其中的 sk_prot 又定义了二级处理函数。对于 UDP 协议来说,会被设置成 UDP 协议实现的方法集 udp_prot。
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
...
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,
.sendpage = udp_sendpage,
};
看完了 socket 变量之后,我们再来看 sys_revvfrom 的实现过程。
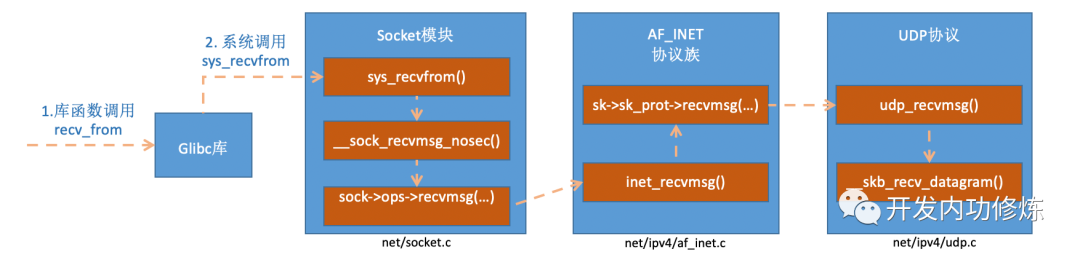
图 12 recvfrom 函数内部实现过程
在 inet_recvmsg 调用了 sk->sk_prot->recvmsg。
//file: net/ipv4/af_inet.c
int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,size_t size, int flags){ struct sock *sk = sock->sk;
int addr_len = 0;
int err;
if (likely(!(flags & MSG_ERRQUEUE)))
sock_rps_record_flow(sk);
err = INDIRECT_CALL_2(sk->sk_prot->recvmsg, tcp_recvmsg, udp_recvmsg,
sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
if (err >= 0)
msg->msg_namelen = addr_len;
return err;
}
struct sk_buff *__skb_recv_udp(struct sock *sk, unsigned int flags,
int noblock, int *off, int *err)
{
struct sk_buff_head *sk_queue = &sk->sk_receive_queue;
struct sk_buff_head *queue;
struct sk_buff *last;
long timeo;
int error;
queue = &udp_sk(sk)->reader_queue;
flags |= noblock ? MSG_DONTWAIT : 0;
timeo = sock_rcvtimeo(sk, flags & MSG_DONTWAIT);
do {
struct sk_buff *skb;
error = sock_error(sk);
if (error)
break;
error = -EAGAIN;
do {
spin_lock_bh(&queue->lock);
skb = __skb_try_recv_from_queue(sk, queue, flags,
udp_skb_destructor,
off, err, &last);
if (skb) {
spin_unlock_bh(&queue->lock);
return skb;
}
if (skb_queue_empty_lockless(sk_queue)) {
spin_unlock_bh(&queue->lock);
goto busy_check;
}
/* refill the reader queue and walk it again
* keep both queues locked to avoid re-acquiring
* the sk_receive_queue lock if fwd memory scheduling
* is needed.
*/
spin_lock(&sk_queue->lock);
skb_queue_splice_tail_init(sk_queue, queue);
skb = __skb_try_recv_from_queue(sk, queue, flags,
udp_skb_dtor_locked,
off, err, &last);
spin_unlock(&sk_queue->lock);
spin_unlock_bh(&queue->lock);
if (skb)
return skb;
busy_check:
if (!sk_can_busy_loop(sk))
break;
sk_busy_loop(sk, flags & MSG_DONTWAIT);
} while (!skb_queue_empty_lockless(sk_queue));
/* sk_queue is empty, reader_queue may contain peeked packets */
} while (timeo &&
!__skb_wait_for_more_packets(sk, &error, &timeo,
(struct sk_buff *)sk_queue));
*err = error;
return NULL;
}
访问 sk->sk_receive_queue读取数据。如果没有数据,且用户也允许等待,则将调用 wait_for_more_packets () 执行等待操作,它加入会让用户进程进入睡眠状态。
五、总结
当用户执行完 recvfrom 调用后,用户进程就通过系统调用进行到内核态工作了。如果接收队列没有数据,进程就进入睡眠状态被操作系统挂起。剩下大部分都是由 Linux 内核其它模块来完成。
首先在开始收包之前,Linux 要做许多的准备工作:
-
创建 ksoftirqd 线程,为它设置好它自己的线程函数,以便后面处理软中断。
-
协议栈注册,linux 要实现许多协议,比如 arp,icmp,ip,udp,tcp,每一个协议都会将自己的处理函数注册一下,方便包来了迅速找到对应的处理函数
-
网卡驱动初始化,每个驱动都有一个初始化函数,内核会让驱动也初始化一下。在这个初始化过程中,把自己的 DMA 准备好,把 NAPI 的 poll 函数地址告诉内核
-
启动网卡,分配 RX,TX 队列,注册中断对应的处理函数
以上是内核准备收包之前的重要工作,当上面都 ready 之后,就可以打开硬中断,等待数据包的到来了。
当数据到来了以后,第一个迎接它的是网卡(我去,这不是废话么):
\1. 网卡将数据帧 DMA 到内存的 RingBuffer 中,然后向 CPU 发起中断通知
\2. CPU 响应中断请求,调用网卡启动时注册的中断处理函数
\3. 中断处理函数几乎没干啥,就发起了软中断请求
\4. 内核线程 ksoftirqd 线程发现有软中断请求到来,先关闭硬中断
\5. ksoftirqd 线程开始调用驱动的 poll 函数收包
\6. poll 函数将收到的包送到协议栈注册的 ip_rcv 函数中
\7. ip_rcv 函数再讲包送到 udp_rcv 函数中(对于 tcp 包就送到 tcp_rcv)
理解了整个收包过程以后,我们就能明确知道 Linux 收一个包的 CPU 开销了。首先第一块是用户进程调用系统调用陷入内核态的开销。第二块是 CPU 响应包的硬中断的 CPU 开销。第三块是 ksoftirqd 内核线程的软中断上下文花费的。















 374
374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









