






【实例简介】爬取学堂在线动态页面
【实例内容】包括源文件、说明、可执行程序
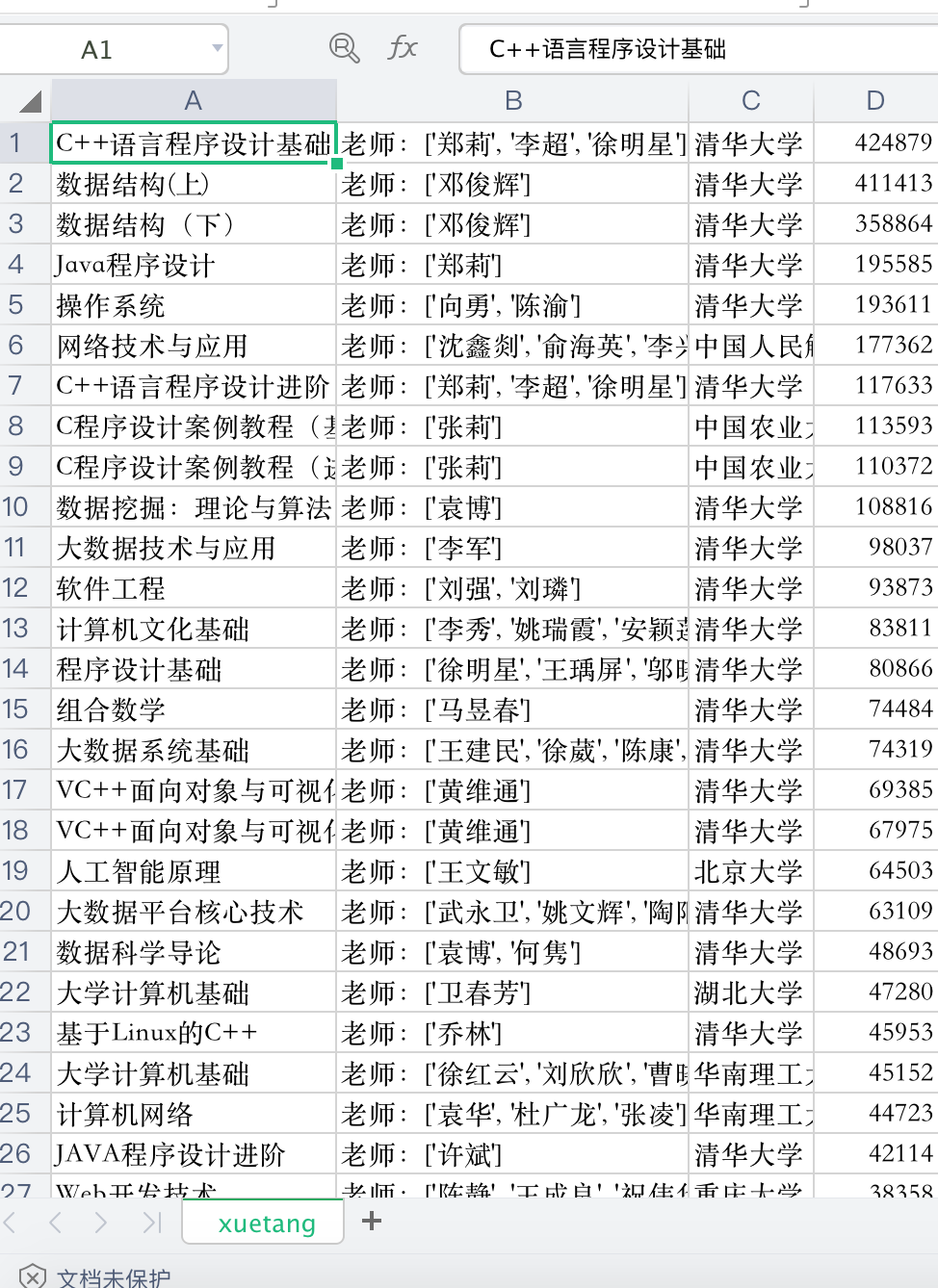
采集的数据保存到xuetang.csv文件中了,如下图:
【实例截图】
【核心代码】
xuetang
├── begin.py
├── scrapy.cfg
├── xuetang
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-37.pyc
│ │ ├── items.cpython-37.pyc
│ │ ├── pipelines.cpython-37.pyc
│ │ └── settings.cpython-37.pyc
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-37.pyc
│ │ └── spider.cpython-37.pyc
│ └── spider.py
└── xuetang.csv
4 directories, 16 files















 1039
1039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









