







Zero-copy概念
"Zero-copy" describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.
从WIKI的定义中,我们看到“零拷贝”是指计算机操作的过程中,CPU不需要为数据在内存之间的拷贝消耗资源。而它通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式。
Non-Zero Copy方式: 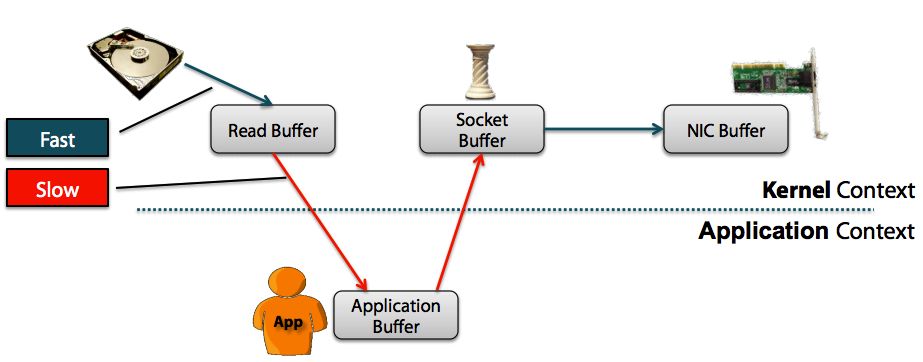
Zero Copy方式: 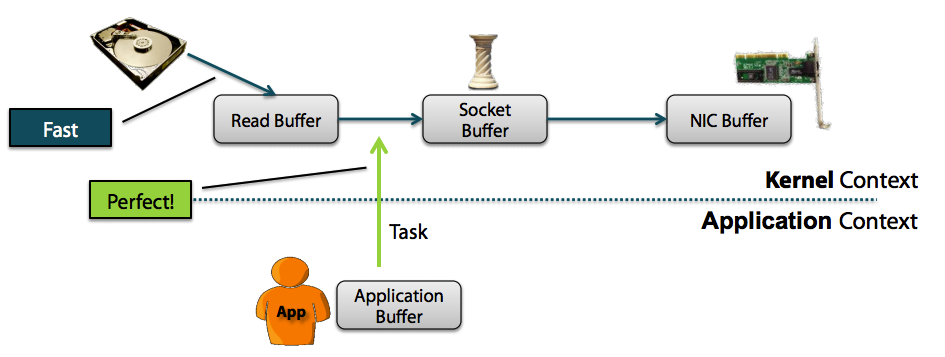
从上图中可以清楚的看到,Zero Copy的模式中,避免了数据在用户空间和内存空间之间的拷贝,从而提高了系统的整体性能。
程序访问方式
- The Linux kernel supports zero-copy through various system calls, such as sys/socket.h's sendfile, sendfile64, and splice. Some of them are specified in POSIX and thus also present in the BSD kernels or IBM AIX, some are unique to the Linux kernel API.
- Microsoft Windows supports zero-copy through the TransmitFile API.
- Java input streams can support zero-copy through the java.nio.channels.FileChannel's transferTo() method if the underlying operating system also supports zero copy
Netty支持的zero-copy有2种:
1 包装FileChannel.tranferTo方法实现zero-copy
Netty中通过在FileRegion中包装了NIO的FileChannel.transferTo()方法实现了零拷贝。
FileRegion是一个接口,默认的实现类是:DefaultFileRegion
2 复合缓冲类型中内置的透明的零拷贝实现。
Transparent Zero Copy 透明的零拷贝
举一个网络应用到极致的表现,你需要减少内存拷贝操作次数。你可能有一组缓冲区可以被组合以形成一个完整的消息。网络提供了一种复合缓冲,允许你从现有的任意数的缓冲区创建一个新的缓冲区而无需内存拷贝。例如,一个信息可以由两部分组成;header 和 body。在一个模块化的应用,当消息发送出去时,这两部分可以由不同的模块生产和装配。
+--------+----------+
| header | body |
+--------+----------+如果你使用的是 ByteBuffer ,你必须要创建一个新的大缓存区用来拷贝这两部分到这个新缓存区中。或者,你可以在 NiO做一个收集写操作,但限制你将复合缓冲类型作为 ByteBuffer 的数组而不是一个单一的缓冲区,打破了抽象,并且引入了复杂的状态管理。此外,如果你不从 NIO channel 读或写,它是没有用的。
// 复合类型与组件类型不兼容。
ByteBuffer[] message = new ByteBuffer[] { header, body };通过对比, ByteBuf 不会有警告,因为它是完全可扩展并有一个内置的复合缓冲区。
// 复合类型与组件类型是兼容的。
ByteBuf message = Unpooled.wrappedBuffer(header, body);
// 因此,你甚至可以通过混合复合类型与普通缓冲区来创建一个复合类型。
ByteBuf messageWithFooter = Unpooled.wrappedBuffer(message, footer);
// 由于复合类型仍是 ByteBuf,访问其内容很容易,
//并且访问方法的行为就像是访问一个单独的缓冲区,
//即使你想访问的区域是跨多个组件。
//这里的无符号整数读取位于 body 和 footer
messageWithFooter.getUnsignedInt(
messageWithFooter.readableBytes() - footer.readableBytes() - 1);Automatic Capacity Extension 自动容量扩展
许多协议定义可变长度的消息,这意味着没有办法确定消息的长度,直到你构建的消息。或者,在计算长度的精确值时,带来了困难和不便。这就像当你建立一个字符串。你经常估计得到的字符串的长度,让 StringBuffer 扩大了其本身的需求。
// 一种新的动态缓冲区被创建。在内部,实际缓冲区是被“懒”创建,从而避免潜在的浪费内存空间。
ByteBuf b = Unpooled.buffer(4);
// 当第一个执行写尝试,内部指定初始容量 4 的缓冲区被创建
b.writeByte('1');
b.writeByte('2');
b.writeByte('3');
b.writeByte('4');
// 当写入的字节数超过初始容量 4 时,
//内部缓冲区自动分配具有较大的容量
b.writeByte('5');
Better Performance 更好的性能
最频繁使用的缓冲区 ByteBuf 的实现是一个非常薄的字节数组包装器(比如,一个字节)。与 ByteBuffer 不同,它没有复杂的边界和索引检查补偿,因此对于 JVM 优化缓冲区的访问更加简单。更多复杂的缓冲区实现是用于拆分或者组合缓存,并且比 ByteBuffer 拥有更好的性能。
ByteBuf 具有丰富的操作集,可以快速的实现协议的优化。例如,ByteBuf 提供各种操作用于访问无符号值和字符串,以及在缓冲区搜索一定的字节序列。你也可以扩展或包装现有的缓冲类型用来提供方便的访问。自定义缓冲仍然实现自 ByteBuf 接口,而不是引入一个不兼容的类型
与ByteBuffer相比,不再需要调用的flip()方法,并且正常情况下效率更高、响应更好。














 2664
2664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









